Showing
- nethack_baselines/torchbeast/README.md 150 additions, 0 deletionsnethack_baselines/torchbeast/README.md
- nethack_baselines/torchbeast/config.yaml 107 additions, 0 deletionsnethack_baselines/torchbeast/config.yaml
- nethack_baselines/torchbeast/core/file_writer.py 203 additions, 0 deletionsnethack_baselines/torchbeast/core/file_writer.py
- nethack_baselines/torchbeast/core/vtrace.py 136 additions, 0 deletionsnethack_baselines/torchbeast/core/vtrace.py
- nethack_baselines/torchbeast/models/__init__.py 56 additions, 0 deletionsnethack_baselines/torchbeast/models/__init__.py
- nethack_baselines/torchbeast/models/baseline.py 496 additions, 0 deletionsnethack_baselines/torchbeast/models/baseline.py
- nethack_baselines/torchbeast/models/util.py 142 additions, 0 deletionsnethack_baselines/torchbeast/models/util.py
- nethack_baselines/torchbeast/polybeast_env.py 127 additions, 0 deletionsnethack_baselines/torchbeast/polybeast_env.py
- nethack_baselines/torchbeast/polybeast_learner.py 520 additions, 0 deletionsnethack_baselines/torchbeast/polybeast_learner.py
- nethack_baselines/torchbeast/polyhydra.py 150 additions, 0 deletionsnethack_baselines/torchbeast/polyhydra.py
- notebooks/NetHackTutorial.ipynb 449 additions, 0 deletionsnotebooks/NetHackTutorial.ipynb
- notebooks/example_annotated.png 0 additions, 0 deletionsnotebooks/example_annotated.png
- notebooks/example_standalone.png 0 additions, 0 deletionsnotebooks/example_standalone.png
- notebooks/model.png 0 additions, 0 deletionsnotebooks/model.png
- requirements.txt 11 additions, 4 deletionsrequirements.txt
- rollout.py 68 additions, 19 deletionsrollout.py
- run.sh 1 addition, 0 deletionsrun.sh
- saved_models/torchbeast/pretrained_0.25B/checkpoint.tar 3 additions, 0 deletionssaved_models/torchbeast/pretrained_0.25B/checkpoint.tar
- saved_models/torchbeast/pretrained_0.25B/config.yaml 48 additions, 0 deletionssaved_models/torchbeast/pretrained_0.25B/config.yaml
- saved_models/torchbeast/pretrained_0.5B/checkpoint.tar 3 additions, 0 deletionssaved_models/torchbeast/pretrained_0.5B/checkpoint.tar
nethack_baselines/torchbeast/README.md
0 → 100644
nethack_baselines/torchbeast/config.yaml
0 → 100644
nethack_baselines/torchbeast/core/vtrace.py
0 → 100644
nethack_baselines/torchbeast/models/util.py
0 → 100644
nethack_baselines/torchbeast/polyhydra.py
0 → 100644
notebooks/NetHackTutorial.ipynb
0 → 100644
notebooks/example_annotated.png
0 → 100644
{kind=link}
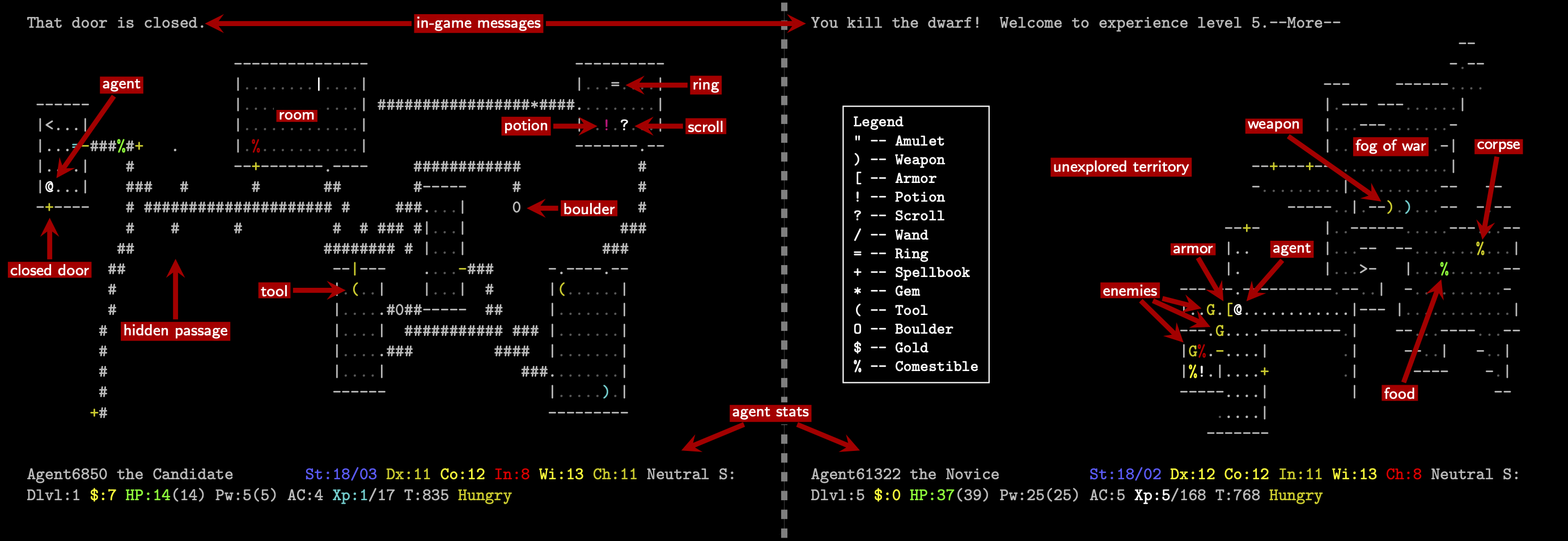
292 KiB
notebooks/example_standalone.png
0 → 100644
{kind=link}
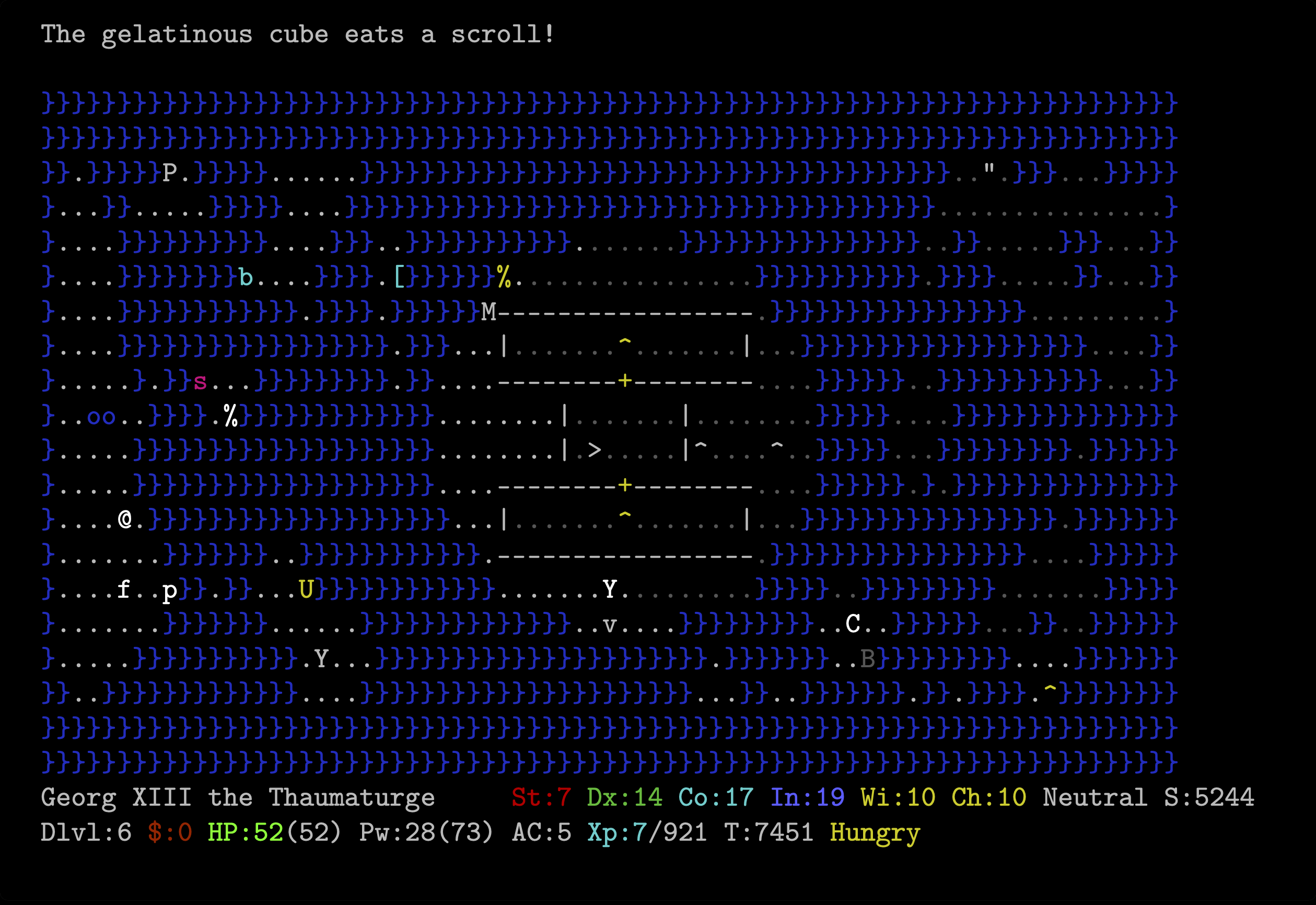
262 KiB
notebooks/model.png
0 → 100644
{kind=link}
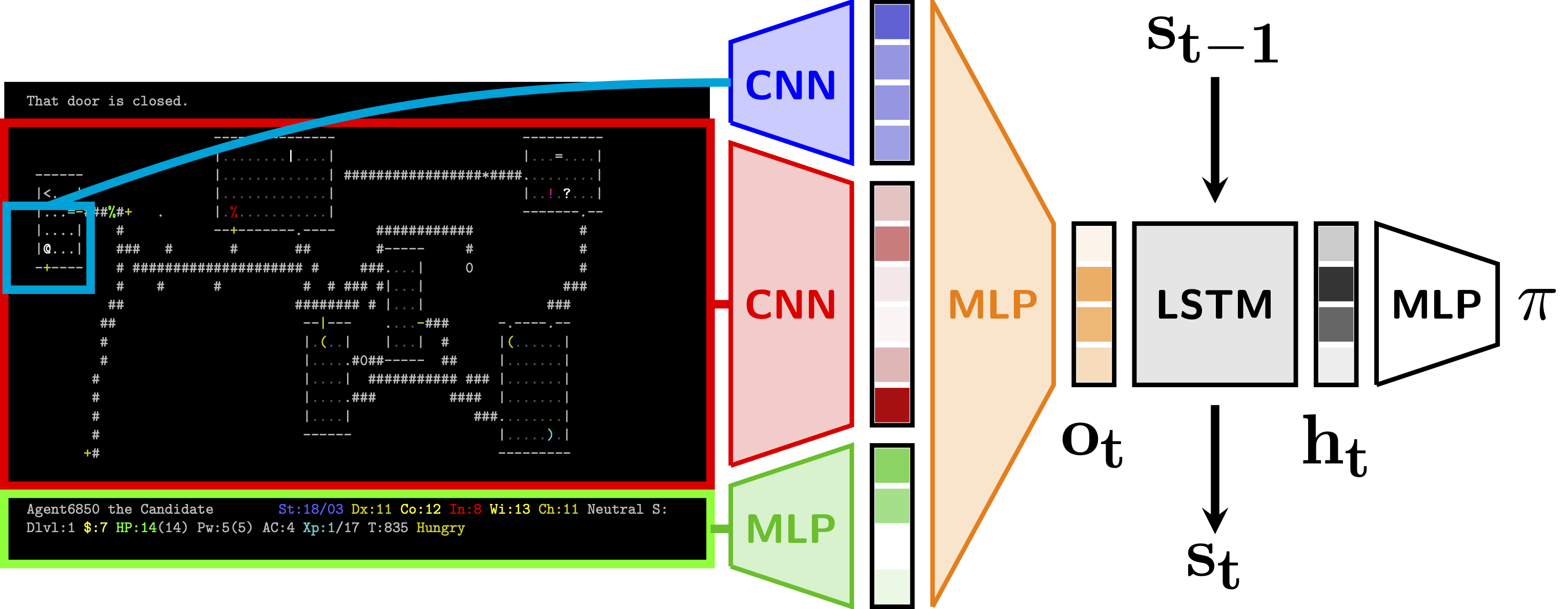
238 KiB
| aicrowd_api | ||
| gym | ||
| nle --no-binary :all: | ||
| torch | ||
| einops | ||
| hydra-core==1.0.6 | ||
| hydra_colorlog | ||
| aicrowd-api | ||
| aicrowd-gym | ||
| numpy | ||
| scipy | ||
| nle>=0.7.2 | ||
| tqdm | ||
| wandb |
File added
File added