diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.flake8 b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.flake8
deleted file mode 100644
index 3be5b6be4c7dc036e223db12aa880e0cee0ef5ce..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.flake8
+++ /dev/null
@@ -1,13 +0,0 @@
-[flake8]
-max-line-length = 119
-exclude = docs/source,*.egg,build
-select = E,W,F
-verbose = 2
-# https://pep8.readthedocs.io/en/latest/intro.html#error-codes
-format = pylint
-ignore =
- E731 # E731 - Do not assign a lambda expression, use a def
- W605 # W605 - invalid escape sequence '\_'. Needed for docs
- W504 # W504 - line break after binary operator
- W503 # W503 - line break before binary operator, need for black
- E203 # E203 - whitespace before ':'. Opposite convention enforced by black
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/ISSUE_TEMPLATE/bug-report.md b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/ISSUE_TEMPLATE/bug-report.md
deleted file mode 100644
index 51af8d6f76ffd5519a6f3c09aae1d872546bf1b4..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/ISSUE_TEMPLATE/bug-report.md
+++ /dev/null
@@ -1,48 +0,0 @@
----
-name: "\U0001F41B Bug Report"
-about: Submit a bug report to help to improve Open-Unmix
-
----
-
-## 🛠Bug
-
-<!-- A clear and concise description of what the bug is. -->
-
-## To Reproduce
-
-Steps to reproduce the behavior:
-
-1.
-1.
-1.
-
-<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
-
-## Expected behavior
-
-<!-- A clear and concise description of what you expected to happen. -->
-
-## Environment
-
-Please add some information about your environment
-
- - PyTorch Version (e.g., 1.2):
- - OS (e.g., Linux):
- - torchaudio loader (y/n):
- - Python version:
- - CUDA/cuDNN version:
- - Any other relevant information:
-
-If unsure you can paste the output from the [pytorch environment collection script](https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py)
-(or fill out the checklist below manually).
-
-You can get that script and run it with:
-```
-wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
-# For security purposes, please check the contents of collect_env.py before running it.
-python collect_env.py
-```
-
-## Additional context
-
-<!-- Add any other context about the problem here. -->
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/ISSUE_TEMPLATE/improved-model.md b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/ISSUE_TEMPLATE/improved-model.md
deleted file mode 100644
index e708c6d8f61fb777d0706cff239047b25e62086b..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/ISSUE_TEMPLATE/improved-model.md
+++ /dev/null
@@ -1,19 +0,0 @@
----
-name: "\U0001F680Improved Model"
-about: Submit a proposal for an improved separation model
-
----
-
-## 🚀 Model Improvement
-<!-- A clear and concise description of the added model improvement
-
-Example: we changed the ReLU activation to XeLU since it was shown in [1] that this reduces overfitting
--->
-
-## Motivation
-
-<!-- Please outline the motivation for the model improvement. Is your proposal related to a problem? -->
-
-## Objective Evaluation
-
-<!-- A table with the median of median BSSEval result on computed on the MUSDB18 test set -->
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/PULL_REQUEST_TEMPLATE.md b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/PULL_REQUEST_TEMPLATE.md
deleted file mode 100644
index 3f89d7d90fd0914039f95abd7a2c542e6a7bb669..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/PULL_REQUEST_TEMPLATE.md
+++ /dev/null
@@ -1,12 +0,0 @@
-<!--
-Thanks for contributing a pull request! Please ensure you have taken a look at
-the contribution guidelines: https://github.com/sigsep/open-unmix-pytorch/blob/master/CONTRIBUTING.md
-->
-
-#### Reference Issue
-<!-- Example: Fixes #123 -->
-
-#### What does this implement/fix? Explain your changes.
-
-
-#### Any other comments?
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/workflows/test_black.yml b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/workflows/test_black.yml
deleted file mode 100644
index 4fba942163fad8bbc60c50ddc991d7671f04a1c5..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/workflows/test_black.yml
+++ /dev/null
@@ -1,25 +0,0 @@
-name: Linter
-on: [push, pull_request]
-
-jobs:
- code-black:
- name: CI
- runs-on: ubuntu-latest
- steps:
- - name: Checkout
- uses: actions/checkout@v2
- - name: Set up Python 3.7
- uses: actions/setup-python@v2
- with:
- python-version: 3.7
-
- - name: Install Black and flake8
- run: pip install black==22.3.0 flake8
- - name: Run Black
- run: python -m black --config=pyproject.toml --check openunmix tests scripts
-
- - name: Lint with flake8
- # Exit on important linting errors and warn about others.
- run: |
- python -m flake8 openunmix tests --show-source --statistics --select=F6,F7,F82,F52
- python -m flake8 --config .flake8 --exit-zero openunmix tests --statistics
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/workflows/test_cli.yml b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/workflows/test_cli.yml
deleted file mode 100644
index 869c4979b48804c3546bc8bc974bb482561e3163..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/workflows/test_cli.yml
+++ /dev/null
@@ -1,37 +0,0 @@
-name: UMX
-# thanks for @mpariente for copying this workflow
-# see: https://help.github.com/en/actions/reference/events-that-trigger-workflows
-# Trigger the workflow on push or pull request
-on: [push, pull_request]
-
-jobs:
- src-test:
- name: separation test
- runs-on: ubuntu-latest
- strategy:
- matrix:
- python-version: [3.7, 3.8, 3.9]
-
- # Timeout: https://stackoverflow.com/a/59076067/4521646
- timeout-minutes: 10
- steps:
- - uses: actions/checkout@v2
- - name: Set up Python ${{ matrix.python-version }}
- uses: actions/setup-python@v2
- with:
- python-version: ${{ matrix.python-version }}
- - name: Install libnsdfile, ffmpeg and sox
- run: |
- sudo apt update
- sudo apt install libsndfile1-dev libsndfile1 ffmpeg sox
- - name: Install package dependencies
- run: |
- python -m pip install --upgrade --user pip --quiet
- python -m pip install .["stempeg"]
- python --version
- pip --version
- python -m pip list
-
- - name: CLI tests
- run: |
- umx https://samples.ffmpeg.org/A-codecs/wavpcm/test-96.wav --audio-backend stempeg
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/workflows/test_conda.yml b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/workflows/test_conda.yml
deleted file mode 100644
index f747f6821981a68bbaa31bc8e90b9f0d38cc3b7f..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/workflows/test_conda.yml
+++ /dev/null
@@ -1,42 +0,0 @@
-name: CI
-# thanks for @mpariente for copying this workflow
-# see: https://help.github.com/en/actions/reference/events-that-trigger-workflows
-# Trigger the workflow on push or pull request
-on: [push, pull_request]
-
-jobs:
- src-test:
- name: conda-tests
- runs-on: ubuntu-latest
-
- # Timeout: https://stackoverflow.com/a/59076067/4521646
- timeout-minutes: 10
- defaults:
- run:
- shell: bash -l {0}
- steps:
- - uses: actions/checkout@v2
- - name: Cache conda
- uses: actions/cache@v2
- with:
- path: ~/conda_pkgs_dir
- key: conda-${{ hashFiles('environment-ci.yml') }}
- - name: Setup Miniconda
- uses: conda-incubator/setup-miniconda@v2
- with:
- activate-environment: umx-cpu
- environment-file: scripts/environment-cpu-linux.yml
- auto-update-conda: true
- auto-activate-base: false
- python-version: 3.7
- - name: Install dependencies
- run: |
- python -m pip install -e .['tests']
- python --version
- pip --version
- python -m pip list
- - name: Conda list
- run: conda list
- - name: Run model test
- run: |
- py.test tests/test_model.py -v
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/workflows/test_unittests.yml b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/workflows/test_unittests.yml
deleted file mode 100644
index 3542d57ab37a19237ed138d0b1b823352708bad7..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.github/workflows/test_unittests.yml
+++ /dev/null
@@ -1,71 +0,0 @@
-name: CI
-# thanks for @mpariente for copying this workflow
-# see: https://help.github.com/en/actions/reference/events-that-trigger-workflows
-# Trigger the workflow on push or pull request
-on: [push, pull_request]
-
-jobs:
- src-test:
- name: unit-tests
- runs-on: ubuntu-latest
- strategy:
- matrix:
- python-version: [3.7]
- pytorch-version: ["1.9.0"]
-
- # Timeout: https://stackoverflow.com/a/59076067/4521646
- timeout-minutes: 10
- steps:
- - uses: actions/checkout@v2
- - name: Set up Python ${{ matrix.python-version }}
- uses: actions/setup-python@v2
- with:
- python-version: ${{ matrix.python-version }}
- - name: Install libnsdfile, ffmpeg and sox
- run: |
- sudo apt update
- sudo apt install libsndfile1-dev libsndfile1 ffmpeg sox
- - name: Install python dependencies
- env:
- TORCH_INSTALL: ${{ matrix.pytorch-version }}
- run: |
- python -m pip install --upgrade --user pip --quiet
- python -m pip install numpy Cython --upgrade-strategy only-if-needed --quiet
- python -m pip install coverage codecov --upgrade-strategy only-if-needed --quiet
- if [ $TORCH_INSTALL == "1.8.0" ]; then
- INSTALL="torch==1.8.0+cpu torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html"
- elif [ $TORCH_INSTALL == "1.9.0" ]; then
- INSTALL="torch==1.9.0+cpu torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html"
- else
- INSTALL="--pre torch torchaudio -f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html"
- fi
- python -m pip install $INSTALL
- python -m pip install -e .['tests']
- python --version
- pip --version
- python -m pip list
- - name: Create dummy dataset
- run: |
- chmod +x tests/create_dummy_datasets.sh
- ./tests/create_dummy_datasets.sh
- shell: bash
-
- - name: Source code tests
- run: |
- coverage run -a -m py.test tests
- # chmod +x ./tests/cli_test.sh
- # ./tests/cli_test.sh
-
- - name: CLI tests
- run: |
- chmod +x ./tests/cli_test.sh
- ./tests/cli_test.sh
-
- - name: Coverage report
- run: |
- coverage report -m
- coverage xml -o coverage.xml
- - name: Codecov upload
- uses: codecov/codecov-action@v1
- with:
- file: ./coverage.xml
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.gitignore b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.gitignore
deleted file mode 100644
index e5a08ce698b776e2648dc4226293343fba2dbbeb..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.gitignore
+++ /dev/null
@@ -1,99 +0,0 @@
-#### joe made this: http://goel.io/joe
-
-data/
-OSU/
-.mypy_cache
-.vscode
-*.json
-*.wav
-*.mp3
-*.pth.tar
-env*/
-
-#####=== Python ===#####
-
-# Byte-compiled / optimized / DLL files
-__pycache__/
-*.py[cod]
-*$py.class
-
-# C extensions
-*.so
-
-# Distribution / packaging
-.Python
-env/
-build/
-develop-eggs/
-dist/
-downloads/
-eggs/
-.eggs/
-lib/
-lib64/
-parts/
-sdist/
-var/
-*.egg-info/
-.installed.cfg
-*.egg
-
-# PyInstaller
-# Usually these files are written by a python script from a template
-# before PyInstaller builds the exe, so as to inject date/other infos into it.
-*.manifest
-*.spec
-
-# Installer logs
-pip-log.txt
-pip-delete-this-directory.txt
-
-# Unit test / coverage reports
-htmlcov/
-.tox/
-.coverage
-.coverage.*
-.cache
-nosetests.xml
-coverage.xml
-*,cover
-
-# Translations
-*.mo
-*.pot
-
-# Django stuff:
-*.log
-
-# Sphinx documentation
-docs/_build/
-
-# PyBuilder
-target/
-
-#####=== OSX ===#####
-.DS_Store
-.AppleDouble
-.LSOverride
-
-# Icon must end with two \r
-Icon
-
-
-# Thumbnails
-._*
-
-# Files that might appear in the root of a volume
-.DocumentRevisions-V100
-.fseventsd
-.Spotlight-V100
-.TemporaryItems
-.Trashes
-.VolumeIcon.icns
-
-# Directories potentially created on remote AFP share
-.AppleDB
-.AppleDesktop
-Network Trash Folder
-Temporary Items
-.apdisk
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.nojekyll b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/.nojekyll
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/CONTRIBUTING.md b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/CONTRIBUTING.md
deleted file mode 100644
index f3d96b6c1540b4c7fdb3f3ed019ae721edaffb6d..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/CONTRIBUTING.md
+++ /dev/null
@@ -1,137 +0,0 @@
-# Contributing
-
-Open-Unmix is designed as scientific software. Therefore, we encourage the community to submit bug-fixes and comments and improve the __computational performance__, __reproducibility__ and the __readability__ of the code where possible. When contributing to this repository, please first discuss the change you wish to make in the issue tracker with the owners of this repository before making a change.
-
-We are not looking for contributions that only focus on improving the __separation performance__. However, if this is case, we, instead, encourage researchers to
-
-1. Use Open-Unmix for their own research, e.g. by modification of the model.
-2. Publish and present the results in a scientific paper / conference and __cite open-unmix__.
-3. Contact us via mail or open a [performance issue]() if you are interested to contribute the new model.
- In this case we will rerun the training on our internal cluster and update the pre-trained weights accordingly.
-
-Please note we have a code of conduct, please follow it in all your interactions with the project.
-
-## Pull Request Process
-
-The preferred way to contribute to open-unmix is to fork the
-[main repository](http://github.com/sigsep/open-unmix-pytorch/) on
-GitHub:
-
-1. Fork the [project repository](http://github.com/sigsep/open-unmix-pytorch):
- click on the 'Fork' button near the top of the page. This creates
- a copy of the code under your account on the GitHub server.
-
-2. Clone this copy to your local disk:
-
-```
-$ git clone git@github.com:YourLogin/open-unmix-pytorch.git
-$ cd open-unmix-pytorch
-```
-
-3. Create a branch to hold your changes:
-
-```
-$ git checkout -b my-feature
-```
-
- and start making changes. Never work in the ``master`` branch!
-
-4. Ensure any install or build artifacts are removed before making the pull request.
-
-5. Update the README.md and/or the appropriate document in the `/docs` folder with details of changes to the interface, this includes new command line arguments, dataset description or command line examples.
-
-6. Work on this copy on your computer using Git to do the version
- control. When you're done editing, do:
-
-```
-$ git add modified_files
-$ git commit
-```
-
- to record your changes in Git, then push them to GitHub with:
-
-```
-$ git push -u origin my-feature
-```
-
-Finally, go to the web page of your fork of the open-unmix repo,
-and click 'Pull request' to send your changes to the maintainers for
-review. This will send an email to the committers.
-
-(If any of the above seems like magic to you, then look up the
-[Git documentation](http://git-scm.com/documentation) on the web.)
-
-## Code of Conduct
-
-### Our Pledge
-
-In the interest of fostering an open and welcoming environment, we as
-contributors and maintainers pledge to making participation in our project and
-our community a harassment-free experience for everyone, regardless of age, body
-size, disability, ethnicity, gender identity and expression, level of experience,
-nationality, personal appearance, race, religion, or sexual identity and
-orientation.
-
-### Our Standards
-
-Examples of behavior that contributes to creating a positive environment
-include:
-
-* Using welcoming and inclusive language
-* Being respectful of differing viewpoints and experiences
-* Gracefully accepting constructive criticism
-* Focusing on what is best for the community
-* Showing empathy towards other community members
-
-Examples of unacceptable behavior by participants include:
-
-* The use of sexualized language or imagery and unwelcome sexual attention or
-advances
-* Trolling, insulting/derogatory comments, and personal or political attacks
-* Public or private harassment
-* Publishing others' private information, such as a physical or electronic
- address, without explicit permission
-* Other conduct which could reasonably be considered inappropriate in a
- professional setting
-
-### Our Responsibilities
-
-Project maintainers are responsible for clarifying the standards of acceptable
-behavior and are expected to take appropriate and fair corrective action in
-response to any instances of unacceptable behavior.
-
-Project maintainers have the right and responsibility to remove, edit, or
-reject comments, commits, code, wiki edits, issues, and other contributions
-that are not aligned to this Code of Conduct, or to ban temporarily or
-permanently any contributor for other behaviors that they deem inappropriate,
-threatening, offensive, or harmful.
-
-### Scope
-
-This Code of Conduct applies both within project spaces and in public spaces
-when an individual is representing the project or its community. Examples of
-representing a project or community include using an official project e-mail
-address, posting via an official social media account, or acting as an appointed
-representative at an online or offline event. Representation of a project may be
-further defined and clarified by project maintainers.
-
-### Enforcement
-
-Instances of abusive, harassing, or otherwise unacceptable behavior may be
-reported by contacting the project team @aliutkus, @faroit. All
-complaints will be reviewed and investigated and will result in a response that
-is deemed necessary and appropriate to the circumstances. The project team is
-obligated to maintain confidentiality with regard to the reporter of an incident.
-Further details of specific enforcement policies may be posted separately.
-
-Project maintainers who do not follow or enforce the Code of Conduct in good
-faith may face temporary or permanent repercussions as determined by other
-members of the project's leadership.
-
-### Attribution
-
-This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
-available at [http://contributor-covenant.org/version/1/4][version]
-
-[homepage]: http://contributor-covenant.org
-[version]: http://contributor-covenant.org/version/1/4/
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/Dockerfile b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/Dockerfile
deleted file mode 100644
index c09205d59873ae28b8a8862f00a86ce57ab2e27b..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/Dockerfile
+++ /dev/null
@@ -1,15 +0,0 @@
-FROM pytorch/pytorch:1.7.1-cuda11.0-cudnn8-runtime
-
-RUN apt-get update && apt-get install -y --no-install-recommends \
- libsox-fmt-all \
- sox \
- libsox-dev
-
-WORKDIR /workspace
-
-RUN conda install ffmpeg -c conda-forge
-RUN pip install musdb>=0.4.0
-
-RUN pip install openunmix['stempeg']
-
-ENTRYPOINT ["umx"]
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/LICENSE b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/LICENSE
deleted file mode 100644
index 4267b01da7a50980c2ce7393245000e283d3ab7d..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/LICENSE
+++ /dev/null
@@ -1,21 +0,0 @@
-MIT License
-
-Copyright (c) 2019 Inria (Fabian-Robert Stöter, Antoine Liutkus)
-
-Permission is hereby granted, free of charge, to any person obtaining a copy
-of this software and associated documentation files (the "Software"), to deal
-in the Software without restriction, including without limitation the rights
-to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-copies of the Software, and to permit persons to whom the Software is
-furnished to do so, subject to the following conditions:
-
-The above copyright notice and this permission notice shall be included in all
-copies or substantial portions of the Software.
-
-THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-SOFTWARE.
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/README.md b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/README.md
deleted file mode 100644
index ed10a838de651943f6c20e6254c771bf357abc9f..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/README.md
+++ /dev/null
@@ -1,291 +0,0 @@
-# _Open-Unmix_ for PyTorch
-
-[](https://joss.theoj.org/papers/571753bc54c5d6dd36382c3d801de41d)
-[](https://colab.research.google.com/drive/1mijF0zGWxN-KaxTnd0q6hayAlrID5fEQ)
-[](https://paperswithcode.com/sota/music-source-separation-on-musdb18?p=open-unmix-a-reference-implementation-for)
-
-[](https://github.com/sigsep/open-unmix-pytorch/actions?query=workflow%3ACI+branch%3Amaster+event%3Apush)
-[](https://pypi.python.org/pypi/openunmix)
-[](https://pypi.python.org/pypi/openunmix)
-
-This repository contains the PyTorch (1.8+) implementation of __Open-Unmix__, a deep neural network reference implementation for music source separation, applicable for researchers, audio engineers and artists. __Open-Unmix__ provides ready-to-use models that allow users to separate pop music into four stems: __vocals__, __drums__, __bass__ and the remaining __other__ instruments. The models were pre-trained on the freely available [MUSDB18](https://sigsep.github.io/datasets/musdb.html) dataset. See details at [apply pre-trained model](#getting-started).
-
-## âï¸ News
-
-- 03/07/2021: We added `umxl`, a model that was trained on extra data which significantly improves the performance, especially generalization.
-- 14/02/2021: We released the new version of open-unmix as a python package. This comes with: a fully differentiable version of [norbert](https://github.com/sigsep/norbert), improved audio loading pipeline and large number of bug fixes. See [release notes](https://github.com/sigsep/open-unmix-pytorch/releases/) for further info.
-
-- 06/05/2020: We added a pre-trained speech enhancement model `umxse` provided by Sony.
-
-- 13/03/2020: Open-unmix was awarded 2nd place in the [PyTorch Global Summer Hackathon 2020](https://devpost.com/software/open-unmix).
-
-__Related Projects:__ open-unmix-pytorch | [open-unmix-nnabla](https://github.com/sigsep/open-unmix-nnabla) | [musdb](https://github.com/sigsep/sigsep-mus-db) | [museval](https://github.com/sigsep/sigsep-mus-eval) | [norbert](https://github.com/sigsep/norbert)
-
-## 🧠The Model (for one source)
-
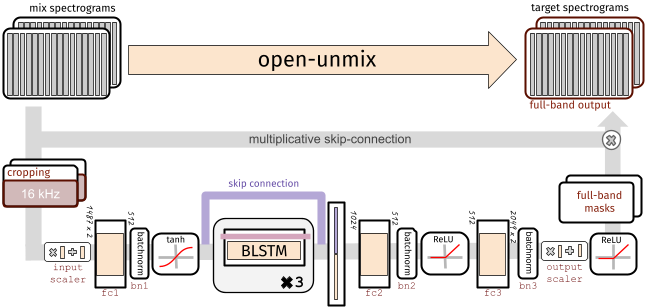
-
-
-To perform separation into multiple sources, _Open-unmix_ comprises multiple models that are trained for each particular target. While this makes the training less comfortable, it allows great flexibility to customize the training data for each target source.
-
-Each _Open-Unmix_ source model is based on a three-layer bidirectional deep LSTM. The model learns to predict the magnitude spectrogram of a target source, like _vocals_, from the magnitude spectrogram of a mixture input. Internally, the prediction is obtained by applying a mask on the input. The model is optimized in the magnitude domain using mean squared error.
-
-### Input Stage
-
-__Open-Unmix__ operates in the time-frequency domain to perform its prediction. The input of the model is either:
-
-* __`models.Separator`:__ A time domain signal tensor of shape `(nb_samples, nb_channels, nb_timesteps)`, where `nb_samples` are the samples in a batch, `nb_channels` is 1 or 2 for mono or stereo audio, respectively, and `nb_timesteps` is the number of audio samples in the recording. In this case, the model computes STFTs with either `torch` or `asteroid_filteranks` on the fly.
-
-* __`models.OpenUnmix`:__ The core open-unmix takes **magnitude spectrograms** directly (e.g. when pre-computed and loaded from disk). In that case, the input is of shape `(nb_frames, nb_samples, nb_channels, nb_bins)`, where `nb_frames` and `nb_bins` are the time and frequency-dimensions of a Short-Time-Fourier-Transform.
-
-The input spectrogram is _standardized_ using the global mean and standard deviation for every frequency bin across all frames. Furthermore, we apply batch normalization in multiple stages of the model to make the training more robust against gain variation.
-
-### Dimensionality reduction
-
-The LSTM is not operating on the original input spectrogram resolution. Instead, in the first step after the normalization, the network learns to compresses the frequency and channel axis of the model to reduce redundancy and make the model converge faster.
-
-### Bidirectional-LSTM
-
-The core of __open-unmix__ is a three layer bidirectional [LSTM network](https://dl.acm.org/citation.cfm?id=1246450). Due to its recurrent nature, the model can be trained and evaluated on arbitrary length of audio signals. Since the model takes information from past and future simultaneously, the model cannot be used in an online/real-time manner.
-An uni-directional model can easily be trained as described [here](docs/training.md).
-
-### Output Stage
-
-After applying the LSTM, the signal is decoded back to its original input dimensionality. In the last steps the output is multiplied with the input magnitude spectrogram, so that the models is asked to learn a mask.
-
-## 🤹â€â™€ï¸ Putting source models together: the `Separator`
-
-`models.Separator` puts together _Open-unmix_ spectrogram model for each desired target, and combines their output through a multichannel generalized Wiener filter, before application of inverse STFTs using `torchaudio`.
-The filtering is differentiable (but parameter-free) version of [norbert](https://github.com/sigsep/norbert). The separator is currently currently only used during inference.
-
-## ðŸ Getting started
-
-### Installation
-
-`openunmix` can be installed from pypi using:
-
-```
-pip install openunmix
-```
-
-Note, that the pypi version of openunmix uses [torchaudio] to load and save audio files. To increase the number of supported input and output file formats (such as STEMS export), please additionally install [stempeg](https://github.com/faroit/stempeg).
-
-Training is not part of the open-unmix package, please follow [docs/train.md] for more information.
-
-#### Using Docker
-
-We also provide a docker container. Performing separation of a local track in `~/Music/track1.wav` can be performed in a single line:
-
-```
-docker run -v ~/Music/:/data -it faroit/open-unmix-pytorch "/data/track1.wav" --outdir /data/track1
-```
-
-### Pre-trained models
-
-We provide three core pre-trained music separation models. All three models are end-to-end models that take waveform inputs and output the separated waveforms.
-
-* __`umxl` (default)__ trained on private stems dataset of compressed stems. __Note, that the weights are only licensed for non-commercial use (CC BY-NC-SA 4.0).__
-
- [](https://doi.org/10.5281/zenodo.5069601)
-
-* __`umxhq`__ trained on [MUSDB18-HQ](https://sigsep.github.io/datasets/musdb.html#uncompressed-wav) which comprises the same tracks as in MUSDB18 but un-compressed which yield in a full bandwidth of 22050 Hz.
-
- [](https://doi.org/10.5281/zenodo.3370489)
-
-* __`umx`__ is trained on the regular [MUSDB18](https://sigsep.github.io/datasets/musdb.html#compressed-stems) which is bandwidth limited to 16 kHz do to AAC compression. This model should be used for comparison with other (older) methods for evaluation in [SiSEC18](sisec18.unmix.app).
-
- [](https://doi.org/10.5281/zenodo.3370486)
-
-Furthermore, we provide a model for speech enhancement trained by [Sony Corporation](link)
-
-* __`umxse`__ speech enhancement model is trained on the 28-speaker version of the [Voicebank+DEMAND corpus](https://datashare.is.ed.ac.uk/handle/10283/1942?show=full).
-
- [](https://doi.org/10.5281/zenodo.3786908)
-
-All four models are also available as spectrogram (core) models, which take magnitude spectrogram inputs and ouput separated spectrograms.
-These models can be loaded using `umxl_spec`, `umxhq_spec`, `umx_spec` and `umxse_spec`.
-
-To separate audio files (`wav`, `flac`, `ogg` - but not `mp3`) files just run:
-
-```bash
-umx input_file.wav
-```
-
-A more detailed list of the parameters used for the separation is given in the [inference.md](/docs/inference.md) document.
-
-We provide a [jupyter notebook on google colab](https://colab.research.google.com/drive/1mijF0zGWxN-KaxTnd0q6hayAlrID5fEQ) to experiment with open-unmix and to separate files online without any installation setup.
-
-### Using pre-trained models from within python
-
-We implementes several ways to load pre-trained models and use them from within your python projects:
-#### When the package is installed
-
-Loading a pre-trained models is as simple as loading
-
-```python
-separator = openunmix.umxl(...)
-```
-#### torch.hub
-
-We also provide a torch.hub compatible modules that can be loaded. Note that this does _not_ even require to install the open-unmix packagen and should generally work when the pytorch version is the same.
-
-```python
-separator = torch.hub.load('sigsep/open-unmix-pytorch', 'umxl, device=device)
-```
-
-Where, `umxl` specifies the pre-trained model.
-#### Performing separation
-
-With a created separator object, one can perform separation of some `audio` (torch.Tensor of shape `(channels, length)`, provided as at a sampling rate `separator.sample_rate`) through:
-
-```python
-estimates = separator(audio, ...)
-# returns estimates as tensor
-```
-
-Note that this requires the audio to be in the right shape and sampling rate. For convenience we provide a pre-processing in `openunmix.utils.preprocess(..`)` that takes numpy audio and converts it to be used for open-unmix.
-
-#### One-liner
-
-To perform model loading, preprocessing and separation in one step, just use:
-
-```python
-from openunmix import separate
-estimates = separate.predict(audio, ...)
-```
-
-### Load user-trained models
-
-When a path instead of a model-name is provided to `--model`, pre-trained `Separator` will be loaded from disk.
-E.g. The following files are assumed to present when loading `--model mymodel --targets vocals`
-
-* `mymodel/separator.json`
-* `mymodel/vocals.pth`
-* `mymodel/vocals.json`
-
-
-Note that the separator usually joins multiple models for each target and performs separation using all models. E.g. if the separator contains `vocals` and `drums` models, two output files are generated, unless the `--residual` option is selected, in which case an additional source will be produced, containing an estimate of all that is not the targets in the mixtures.
-
-### Evaluation using `museval`
-
-To perform evaluation in comparison to other SISEC systems, you would need to install the `museval` package using
-
-```
-pip install museval
-```
-
-and then run the evaluation using
-
-`python -m openunmix.evaluate --outdir /path/to/musdb/estimates --evaldir /path/to/museval/results`
-
-### Results compared to SiSEC 2018 (SDR/Vocals)
-
-Open-Unmix yields state-of-the-art results compared to participants from [SiSEC 2018](https://sisec18.unmix.app/#/methods). The performance of `UMXHQ` and `UMX` is almost identical since it was evaluated on compressed STEMS.
-
-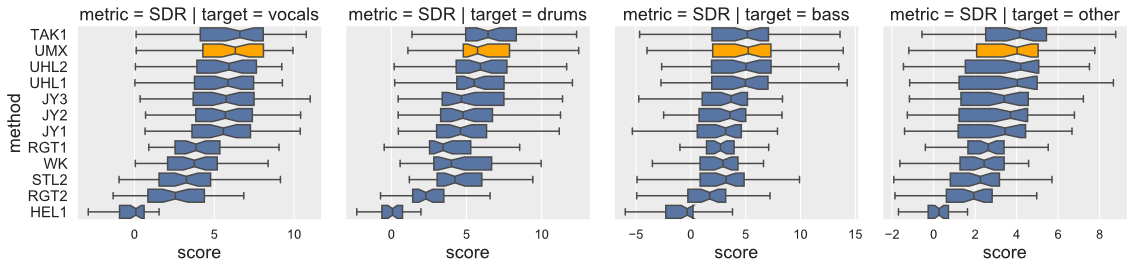
-
-Note that
-
-1. [`STL1`, `TAK2`, `TAK3`, `TAU1`, `UHL3`, `UMXHQ`] were omitted as they were _not_ trained on only _MUSDB18_.
-2. [`HEL1`, `TAK1`, `UHL1`, `UHL2`] are not open-source.
-
-#### Scores (Median of frames, Median of tracks)
-
-|target|SDR | SDR | SDR |
-|------|-----|-----|-----|
-|`model`|UMX |UMXHQ|UMXL |
-|vocals|6.32 | 6.25|__7.21__ |
-|bass |5.23 | 5.07|__6.02__ |
-|drums |5.73 | 6.04|__7.15__ |
-|other |4.02 | 4.28|__4.89__ |
-
-## Training
-
-Details on the training is provided in a separate document [here](docs/training.md).
-
-## Extensions
-
-Details on how _open-unmix_ can be extended or improved for future research on music separation is described in a separate document [here](docs/extensions.md).
-
-
-## Design Choices
-
-we favored simplicity over performance to promote clearness of the code. The rationale is to have __open-unmix__ serve as a __baseline__ for future research while performance still meets current state-of-the-art (See [Evaluation](#Evaluation)). The results are comparable/better to those of `UHL1`/`UHL2` which obtained the best performance over all systems trained on MUSDB18 in the [SiSEC 2018 Evaluation campaign](https://sisec18.unmix.app).
-We designed the code to allow researchers to reproduce existing results, quickly develop new architectures and add own user data for training and testing. We favored framework specifics implementations instead of having a monolithic repository with common code for all frameworks.
-
-## How to contribute
-
-_open-unmix_ is a community focused project, we therefore encourage the community to submit bug-fixes and requests for technical support through [github issues](https://github.com/sigsep/open-unmix-pytorch/issues/new/choose). For more details of how to contribute, please follow our [`CONTRIBUTING.md`](CONTRIBUTING.md). For help and support, please use the gitter chat or the google groups forums.
-
-### Authors
-
-[Fabian-Robert Stöter](https://www.faroit.com/), [Antoine Liutkus](https://github.com/aliutkus), Inria and LIRMM, Montpellier, France
-
-## References
-
-<details><summary>If you use open-unmix for your research – Cite Open-Unmix</summary>
-
-```latex
-@article{stoter19,
- author={F.-R. St\\"oter and S. Uhlich and A. Liutkus and Y. Mitsufuji},
- title={Open-Unmix - A Reference Implementation for Music Source Separation},
- journal={Journal of Open Source Software},
- year=2019,
- doi = {10.21105/joss.01667},
- url = {https://doi.org/10.21105/joss.01667}
-}
-```
-
-</p>
-</details>
-
-<details><summary>If you use the MUSDB dataset for your research - Cite the MUSDB18 Dataset</summary>
-<p>
-
-```latex
-@misc{MUSDB18,
- author = {Rafii, Zafar and
- Liutkus, Antoine and
- Fabian-Robert St{\"o}ter and
- Mimilakis, Stylianos Ioannis and
- Bittner, Rachel},
- title = {The {MUSDB18} corpus for music separation},
- month = dec,
- year = 2017,
- doi = {10.5281/zenodo.1117372},
- url = {https://doi.org/10.5281/zenodo.1117372}
-}
-```
-
-</p>
-</details>
-
-
-<details><summary>If compare your results with SiSEC 2018 Participants - Cite the SiSEC 2018 LVA/ICA Paper</summary>
-<p>
-
-```latex
-@inproceedings{SiSEC18,
- author="St{\"o}ter, Fabian-Robert and Liutkus, Antoine and Ito, Nobutaka",
- title="The 2018 Signal Separation Evaluation Campaign",
- booktitle="Latent Variable Analysis and Signal Separation:
- 14th International Conference, LVA/ICA 2018, Surrey, UK",
- year="2018",
- pages="293--305"
-}
-```
-
-</p>
-</details>
-
-âš ï¸ Please note that the official acronym for _open-unmix_ is **UMX**.
-
-### License
-
-MIT
-
-### Acknowledgements
-
-<p align="center">
- <img src="https://raw.githubusercontent.com/sigsep/website/master/content/open-unmix/logo_INRIA.svg?sanitize=true" width="200" title="inria">
- <img src="https://raw.githubusercontent.com/sigsep/website/master/content/open-unmix/anr.jpg" width="100" alt="anr">
-</p>
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/codecov.yml b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/codecov.yml
deleted file mode 100644
index 482585a984003a0c344a5e60ffb88aeb7fc496d6..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/codecov.yml
+++ /dev/null
@@ -1,2 +0,0 @@
-codecov:
- require_ci_to_pass: no
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/cli.html b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/cli.html
deleted file mode 100644
index b66e74dadad7c64d987c643795dd94f8d89682f1..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/cli.html
+++ /dev/null
@@ -1,466 +0,0 @@
-<!doctype html>
-<html lang="en">
-<head>
-<meta charset="utf-8">
-<meta name="viewport" content="width=device-width, initial-scale=1, minimum-scale=1" />
-<meta name="generator" content="pdoc 0.9.2" />
-<title>openunmix.cli API documentation</title>
-<meta name="description" content="" />
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/sanitize.min.css" integrity="sha256-PK9q560IAAa6WVRRh76LtCaI8pjTJ2z11v0miyNNjrs=" crossorigin>
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/typography.min.css" integrity="sha256-7l/o7C8jubJiy74VsKTidCy1yBkRtiUGbVkYBylBqUg=" crossorigin>
-<link rel="stylesheet preload" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/styles/github.min.css" crossorigin>
-<style>:root{--highlight-color:#fe9}.flex{display:flex !important}body{line-height:1.5em}#content{padding:20px}#sidebar{padding:30px;overflow:hidden}#sidebar > *:last-child{margin-bottom:2cm}.http-server-breadcrumbs{font-size:130%;margin:0 0 15px 0}#footer{font-size:.75em;padding:5px 30px;border-top:1px solid #ddd;text-align:right}#footer p{margin:0 0 0 1em;display:inline-block}#footer p:last-child{margin-right:30px}h1,h2,h3,h4,h5{font-weight:300}h1{font-size:2.5em;line-height:1.1em}h2{font-size:1.75em;margin:1em 0 .50em 0}h3{font-size:1.4em;margin:25px 0 10px 0}h4{margin:0;font-size:105%}h1:target,h2:target,h3:target,h4:target,h5:target,h6:target{background:var(--highlight-color);padding:.2em 0}a{color:#058;text-decoration:none;transition:color .3s ease-in-out}a:hover{color:#e82}.title code{font-weight:bold}h2[id^="header-"]{margin-top:2em}.ident{color:#900}pre code{background:#f8f8f8;font-size:.8em;line-height:1.4em}code{background:#f2f2f1;padding:1px 4px;overflow-wrap:break-word}h1 code{background:transparent}pre{background:#f8f8f8;border:0;border-top:1px solid #ccc;border-bottom:1px solid #ccc;margin:1em 0;padding:1ex}#http-server-module-list{display:flex;flex-flow:column}#http-server-module-list div{display:flex}#http-server-module-list dt{min-width:10%}#http-server-module-list p{margin-top:0}.toc ul,#index{list-style-type:none;margin:0;padding:0}#index code{background:transparent}#index h3{border-bottom:1px solid #ddd}#index ul{padding:0}#index h4{margin-top:.6em;font-weight:bold}@media (min-width:200ex){#index .two-column{column-count:2}}@media (min-width:300ex){#index .two-column{column-count:3}}dl{margin-bottom:2em}dl dl:last-child{margin-bottom:4em}dd{margin:0 0 1em 3em}#header-classes + dl > dd{margin-bottom:3em}dd dd{margin-left:2em}dd p{margin:10px 0}.name{background:#eee;font-weight:bold;font-size:.85em;padding:5px 10px;display:inline-block;min-width:40%}.name:hover{background:#e0e0e0}dt:target .name{background:var(--highlight-color)}.name > span:first-child{white-space:nowrap}.name.class > span:nth-child(2){margin-left:.4em}.inherited{color:#999;border-left:5px solid #eee;padding-left:1em}.inheritance em{font-style:normal;font-weight:bold}.desc h2{font-weight:400;font-size:1.25em}.desc h3{font-size:1em}.desc dt code{background:inherit}.source summary,.git-link-div{color:#666;text-align:right;font-weight:400;font-size:.8em;text-transform:uppercase}.source summary > *{white-space:nowrap;cursor:pointer}.git-link{color:inherit;margin-left:1em}.source pre{max-height:500px;overflow:auto;margin:0}.source pre code{font-size:12px;overflow:visible}.hlist{list-style:none}.hlist li{display:inline}.hlist li:after{content:',\2002'}.hlist li:last-child:after{content:none}.hlist .hlist{display:inline;padding-left:1em}img{max-width:100%}td{padding:0 .5em}.admonition{padding:.1em .5em;margin-bottom:1em}.admonition-title{font-weight:bold}.admonition.note,.admonition.info,.admonition.important{background:#aef}.admonition.todo,.admonition.versionadded,.admonition.tip,.admonition.hint{background:#dfd}.admonition.warning,.admonition.versionchanged,.admonition.deprecated{background:#fd4}.admonition.error,.admonition.danger,.admonition.caution{background:lightpink}</style>
-<style media="screen and (min-width: 700px)">@media screen and (min-width:700px){#sidebar{width:30%;height:100vh;overflow:auto;position:sticky;top:0}#content{width:70%;max-width:100ch;padding:3em 4em;border-left:1px solid #ddd}pre code{font-size:1em}.item .name{font-size:1em}main{display:flex;flex-direction:row-reverse;justify-content:flex-end}.toc ul ul,#index ul{padding-left:1.5em}.toc > ul > li{margin-top:.5em}}</style>
-<style media="print">@media print{#sidebar h1{page-break-before:always}.source{display:none}}@media print{*{background:transparent !important;color:#000 !important;box-shadow:none !important;text-shadow:none !important}a[href]:after{content:" (" attr(href) ")";font-size:90%}a[href][title]:after{content:none}abbr[title]:after{content:" (" attr(title) ")"}.ir a:after,a[href^="javascript:"]:after,a[href^="#"]:after{content:""}pre,blockquote{border:1px solid #999;page-break-inside:avoid}thead{display:table-header-group}tr,img{page-break-inside:avoid}img{max-width:100% !important}@page{margin:0.5cm}p,h2,h3{orphans:3;widows:3}h1,h2,h3,h4,h5,h6{page-break-after:avoid}}</style>
-<script async src="https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.7/latest.js?config=TeX-AMS_CHTML" integrity="sha256-kZafAc6mZvK3W3v1pHOcUix30OHQN6pU/NO2oFkqZVw=" crossorigin></script>
-<script defer src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/highlight.min.js" integrity="sha256-Uv3H6lx7dJmRfRvH8TH6kJD1TSK1aFcwgx+mdg3epi8=" crossorigin></script>
-<script>window.addEventListener('DOMContentLoaded', () => hljs.initHighlighting())</script>
-</head>
-<body>
-<main>
-<article id="content">
-<header>
-<h1 class="title">Module <code>openunmix.cli</code></h1>
-</header>
-<section id="section-intro">
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/cli.py#L0-L199" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">from pathlib import Path
-import torch
-import torchaudio
-import json
-import numpy as np
-
-
-from openunmix import utils
-from openunmix import predict
-from openunmix import data
-
-import argparse
-
-
-def separate():
- parser = argparse.ArgumentParser(
- description="UMX Inference",
- add_help=True,
- formatter_class=argparse.RawDescriptionHelpFormatter,
- )
-
- parser.add_argument("input", type=str, nargs="+", help="List of paths to wav/flac files.")
-
- parser.add_argument(
- "--model",
- default="umxhq",
- type=str,
- help="path to mode base directory of pretrained models",
- )
-
- parser.add_argument(
- "--targets",
- nargs="+",
- type=str,
- help="provide targets to be processed. \
- If none, all available targets will be computed",
- )
-
- parser.add_argument(
- "--outdir",
- type=str,
- help="Results path where audio evaluation results are stored",
- )
-
- parser.add_argument(
- "--ext",
- type=str,
- default=".wav",
- help="Output extension which sets the audio format",
- )
-
- parser.add_argument("--start", type=float, default=0.0, help="Audio chunk start in seconds")
-
- parser.add_argument(
- "--duration",
- type=float,
- help="Audio chunk duration in seconds, negative values load full track",
- )
-
- parser.add_argument(
- "--no-cuda", action="store_true", default=False, help="disables CUDA inference"
- )
-
- parser.add_argument(
- "--audio-backend",
- type=str,
- default="sox_io",
- help="Set torchaudio backend "
- "(`sox_io`, `sox`, `soundfile` or `stempeg`), defaults to `sox_io`",
- )
-
- parser.add_argument(
- "--niter",
- type=int,
- default=1,
- help="number of iterations for refining results.",
- )
-
- parser.add_argument(
- "--wiener-win-len",
- type=int,
- default=300,
- help="Number of frames on which to apply filtering independently",
- )
-
- parser.add_argument(
- "--residual",
- type=str,
- default=None,
- help="if provided, build a source with given name"
- "for the mix minus all estimated targets",
- )
-
- parser.add_argument(
- "--aggregate",
- type=str,
- default=None,
- help="if provided, must be a string containing a valid expression for "
- "a dictionary, with keys as output target names, and values "
- "a list of targets that are used to build it. For instance: "
- '\'{"vocals":["vocals"], "accompaniment":["drums",'
- '"bass","other"]}\'',
- )
-
- parser.add_argument(
- "--filterbank",
- type=str,
- default="torch",
- help="filterbank implementation method. "
- "Supported: `['torch', 'asteroid']`. `torch` is ~30% faster"
- "compared to `asteroid` on large FFT sizes such as 4096. However"
- "asteroids stft can be exported to onnx, which makes is practical"
- "for deployment.",
- )
- args = parser.parse_args()
- torchaudio.USE_SOUNDFILE_LEGACY_INTERFACE = False
-
- if args.audio_backend != "stempeg":
- torchaudio.set_audio_backend(args.audio_backend)
-
- use_cuda = not args.no_cuda and torch.cuda.is_available()
- device = torch.device("cuda" if use_cuda else "cpu")
-
- # parsing the output dict
- aggregate_dict = None if args.aggregate is None else json.loads(args.aggregate)
-
- # create separator only once to reduce model loading
- # when using multiple files
- separator = utils.load_separator(
- model_str_or_path=args.model,
- targets=args.targets,
- niter=args.niter,
- residual=args.residual,
- wiener_win_len=args.wiener_win_len,
- device=device,
- pretrained=True,
- filterbank=args.filterbank,
- )
-
- separator.freeze()
- separator.to(device)
-
- if args.audio_backend == "stempeg":
- try:
- import stempeg
- except ImportError:
- raise RuntimeError("Please install pip package `stempeg`")
-
- # loop over the files
- for input_file in args.input:
- if args.audio_backend == "stempeg":
- audio, rate = stempeg.read_stems(
- input_file,
- start=args.start,
- duration=args.duration,
- sample_rate=separator.sample_rate,
- dtype=np.float32,
- )
- audio = torch.tensor(audio)
- else:
- audio, rate = data.load_audio(input_file, start=args.start, dur=args.duration)
- estimates = predict.separate(
- audio=audio,
- rate=rate,
- aggregate_dict=aggregate_dict,
- separator=separator,
- device=device,
- )
- if not args.outdir:
- model_path = Path(args.model)
- if not model_path.exists():
- outdir = Path(Path(input_file).stem + "_" + args.model)
- else:
- outdir = Path(Path(input_file).stem + "_" + model_path.stem)
- else:
- outdir = Path(args.outdir)
- outdir.mkdir(exist_ok=True, parents=True)
-
- # write out estimates
- if args.audio_backend == "stempeg":
- target_path = str(outdir / Path("target").with_suffix(args.ext))
- # convert torch dict to numpy dict
- estimates_numpy = {}
- for target, estimate in estimates.items():
- estimates_numpy[target] = torch.squeeze(estimate).detach().numpy().T
-
- stempeg.write_stems(
- target_path,
- estimates_numpy,
- sample_rate=separator.sample_rate,
- writer=stempeg.FilesWriter(multiprocess=True, output_sample_rate=rate),
- )
- else:
- for target, estimate in estimates.items():
- target_path = str(outdir / Path(target).with_suffix(args.ext))
- torchaudio.save(
- target_path,
- torch.squeeze(estimate).to("cpu"),
- sample_rate=separator.sample_rate,
- )</code></pre>
-</details>
-</section>
-<section>
-</section>
-<section>
-</section>
-<section>
-<h2 class="section-title" id="header-functions">Functions</h2>
-<dl>
-<dt id="openunmix.cli.separate"><code class="name flex">
-<span>def <span class="ident">separate</span></span>(<span>)</span>
-</code></dt>
-<dd>
-<div class="desc"></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/cli.py#L15-L200" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def separate():
- parser = argparse.ArgumentParser(
- description="UMX Inference",
- add_help=True,
- formatter_class=argparse.RawDescriptionHelpFormatter,
- )
-
- parser.add_argument("input", type=str, nargs="+", help="List of paths to wav/flac files.")
-
- parser.add_argument(
- "--model",
- default="umxhq",
- type=str,
- help="path to mode base directory of pretrained models",
- )
-
- parser.add_argument(
- "--targets",
- nargs="+",
- type=str,
- help="provide targets to be processed. \
- If none, all available targets will be computed",
- )
-
- parser.add_argument(
- "--outdir",
- type=str,
- help="Results path where audio evaluation results are stored",
- )
-
- parser.add_argument(
- "--ext",
- type=str,
- default=".wav",
- help="Output extension which sets the audio format",
- )
-
- parser.add_argument("--start", type=float, default=0.0, help="Audio chunk start in seconds")
-
- parser.add_argument(
- "--duration",
- type=float,
- help="Audio chunk duration in seconds, negative values load full track",
- )
-
- parser.add_argument(
- "--no-cuda", action="store_true", default=False, help="disables CUDA inference"
- )
-
- parser.add_argument(
- "--audio-backend",
- type=str,
- default="sox_io",
- help="Set torchaudio backend "
- "(`sox_io`, `sox`, `soundfile` or `stempeg`), defaults to `sox_io`",
- )
-
- parser.add_argument(
- "--niter",
- type=int,
- default=1,
- help="number of iterations for refining results.",
- )
-
- parser.add_argument(
- "--wiener-win-len",
- type=int,
- default=300,
- help="Number of frames on which to apply filtering independently",
- )
-
- parser.add_argument(
- "--residual",
- type=str,
- default=None,
- help="if provided, build a source with given name"
- "for the mix minus all estimated targets",
- )
-
- parser.add_argument(
- "--aggregate",
- type=str,
- default=None,
- help="if provided, must be a string containing a valid expression for "
- "a dictionary, with keys as output target names, and values "
- "a list of targets that are used to build it. For instance: "
- '\'{"vocals":["vocals"], "accompaniment":["drums",'
- '"bass","other"]}\'',
- )
-
- parser.add_argument(
- "--filterbank",
- type=str,
- default="torch",
- help="filterbank implementation method. "
- "Supported: `['torch', 'asteroid']`. `torch` is ~30% faster"
- "compared to `asteroid` on large FFT sizes such as 4096. However"
- "asteroids stft can be exported to onnx, which makes is practical"
- "for deployment.",
- )
- args = parser.parse_args()
- torchaudio.USE_SOUNDFILE_LEGACY_INTERFACE = False
-
- if args.audio_backend != "stempeg":
- torchaudio.set_audio_backend(args.audio_backend)
-
- use_cuda = not args.no_cuda and torch.cuda.is_available()
- device = torch.device("cuda" if use_cuda else "cpu")
-
- # parsing the output dict
- aggregate_dict = None if args.aggregate is None else json.loads(args.aggregate)
-
- # create separator only once to reduce model loading
- # when using multiple files
- separator = utils.load_separator(
- model_str_or_path=args.model,
- targets=args.targets,
- niter=args.niter,
- residual=args.residual,
- wiener_win_len=args.wiener_win_len,
- device=device,
- pretrained=True,
- filterbank=args.filterbank,
- )
-
- separator.freeze()
- separator.to(device)
-
- if args.audio_backend == "stempeg":
- try:
- import stempeg
- except ImportError:
- raise RuntimeError("Please install pip package `stempeg`")
-
- # loop over the files
- for input_file in args.input:
- if args.audio_backend == "stempeg":
- audio, rate = stempeg.read_stems(
- input_file,
- start=args.start,
- duration=args.duration,
- sample_rate=separator.sample_rate,
- dtype=np.float32,
- )
- audio = torch.tensor(audio)
- else:
- audio, rate = data.load_audio(input_file, start=args.start, dur=args.duration)
- estimates = predict.separate(
- audio=audio,
- rate=rate,
- aggregate_dict=aggregate_dict,
- separator=separator,
- device=device,
- )
- if not args.outdir:
- model_path = Path(args.model)
- if not model_path.exists():
- outdir = Path(Path(input_file).stem + "_" + args.model)
- else:
- outdir = Path(Path(input_file).stem + "_" + model_path.stem)
- else:
- outdir = Path(args.outdir)
- outdir.mkdir(exist_ok=True, parents=True)
-
- # write out estimates
- if args.audio_backend == "stempeg":
- target_path = str(outdir / Path("target").with_suffix(args.ext))
- # convert torch dict to numpy dict
- estimates_numpy = {}
- for target, estimate in estimates.items():
- estimates_numpy[target] = torch.squeeze(estimate).detach().numpy().T
-
- stempeg.write_stems(
- target_path,
- estimates_numpy,
- sample_rate=separator.sample_rate,
- writer=stempeg.FilesWriter(multiprocess=True, output_sample_rate=rate),
- )
- else:
- for target, estimate in estimates.items():
- target_path = str(outdir / Path(target).with_suffix(args.ext))
- torchaudio.save(
- target_path,
- torch.squeeze(estimate).to("cpu"),
- sample_rate=separator.sample_rate,
- )</code></pre>
-</details>
-</dd>
-</dl>
-</section>
-<section>
-</section>
-</article>
-<nav id="sidebar">
-<h1>Index</h1>
-<div class="toc">
-<ul></ul>
-</div>
-<ul id="index">
-<li><h3>Super-module</h3>
-<ul>
-<li><code><a title="openunmix" href="index.html">openunmix</a></code></li>
-</ul>
-</li>
-<li><h3><a href="#header-functions">Functions</a></h3>
-<ul class="">
-<li><code><a title="openunmix.cli.separate" href="#openunmix.cli.separate">separate</a></code></li>
-</ul>
-</li>
-</ul>
-</nav>
-</main>
-<footer id="footer">
-<p>Generated by <a href="https://pdoc3.github.io/pdoc"><cite>pdoc</cite> 0.9.2</a>.</p>
-</footer>
-</body>
-</html>
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/data.html b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/data.html
deleted file mode 100644
index a7be05f24455acca523bbc7695ac69749e5a435b..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/data.html
+++ /dev/null
@@ -1,2449 +0,0 @@
-<!doctype html>
-<html lang="en">
-<head>
-<meta charset="utf-8">
-<meta name="viewport" content="width=device-width, initial-scale=1, minimum-scale=1" />
-<meta name="generator" content="pdoc 0.9.2" />
-<title>openunmix.data API documentation</title>
-<meta name="description" content="" />
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/sanitize.min.css" integrity="sha256-PK9q560IAAa6WVRRh76LtCaI8pjTJ2z11v0miyNNjrs=" crossorigin>
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/typography.min.css" integrity="sha256-7l/o7C8jubJiy74VsKTidCy1yBkRtiUGbVkYBylBqUg=" crossorigin>
-<link rel="stylesheet preload" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/styles/github.min.css" crossorigin>
-<style>:root{--highlight-color:#fe9}.flex{display:flex !important}body{line-height:1.5em}#content{padding:20px}#sidebar{padding:30px;overflow:hidden}#sidebar > *:last-child{margin-bottom:2cm}.http-server-breadcrumbs{font-size:130%;margin:0 0 15px 0}#footer{font-size:.75em;padding:5px 30px;border-top:1px solid #ddd;text-align:right}#footer p{margin:0 0 0 1em;display:inline-block}#footer p:last-child{margin-right:30px}h1,h2,h3,h4,h5{font-weight:300}h1{font-size:2.5em;line-height:1.1em}h2{font-size:1.75em;margin:1em 0 .50em 0}h3{font-size:1.4em;margin:25px 0 10px 0}h4{margin:0;font-size:105%}h1:target,h2:target,h3:target,h4:target,h5:target,h6:target{background:var(--highlight-color);padding:.2em 0}a{color:#058;text-decoration:none;transition:color .3s ease-in-out}a:hover{color:#e82}.title code{font-weight:bold}h2[id^="header-"]{margin-top:2em}.ident{color:#900}pre code{background:#f8f8f8;font-size:.8em;line-height:1.4em}code{background:#f2f2f1;padding:1px 4px;overflow-wrap:break-word}h1 code{background:transparent}pre{background:#f8f8f8;border:0;border-top:1px solid #ccc;border-bottom:1px solid #ccc;margin:1em 0;padding:1ex}#http-server-module-list{display:flex;flex-flow:column}#http-server-module-list div{display:flex}#http-server-module-list dt{min-width:10%}#http-server-module-list p{margin-top:0}.toc ul,#index{list-style-type:none;margin:0;padding:0}#index code{background:transparent}#index h3{border-bottom:1px solid #ddd}#index ul{padding:0}#index h4{margin-top:.6em;font-weight:bold}@media (min-width:200ex){#index .two-column{column-count:2}}@media (min-width:300ex){#index .two-column{column-count:3}}dl{margin-bottom:2em}dl dl:last-child{margin-bottom:4em}dd{margin:0 0 1em 3em}#header-classes + dl > dd{margin-bottom:3em}dd dd{margin-left:2em}dd p{margin:10px 0}.name{background:#eee;font-weight:bold;font-size:.85em;padding:5px 10px;display:inline-block;min-width:40%}.name:hover{background:#e0e0e0}dt:target .name{background:var(--highlight-color)}.name > span:first-child{white-space:nowrap}.name.class > span:nth-child(2){margin-left:.4em}.inherited{color:#999;border-left:5px solid #eee;padding-left:1em}.inheritance em{font-style:normal;font-weight:bold}.desc h2{font-weight:400;font-size:1.25em}.desc h3{font-size:1em}.desc dt code{background:inherit}.source summary,.git-link-div{color:#666;text-align:right;font-weight:400;font-size:.8em;text-transform:uppercase}.source summary > *{white-space:nowrap;cursor:pointer}.git-link{color:inherit;margin-left:1em}.source pre{max-height:500px;overflow:auto;margin:0}.source pre code{font-size:12px;overflow:visible}.hlist{list-style:none}.hlist li{display:inline}.hlist li:after{content:',\2002'}.hlist li:last-child:after{content:none}.hlist .hlist{display:inline;padding-left:1em}img{max-width:100%}td{padding:0 .5em}.admonition{padding:.1em .5em;margin-bottom:1em}.admonition-title{font-weight:bold}.admonition.note,.admonition.info,.admonition.important{background:#aef}.admonition.todo,.admonition.versionadded,.admonition.tip,.admonition.hint{background:#dfd}.admonition.warning,.admonition.versionchanged,.admonition.deprecated{background:#fd4}.admonition.error,.admonition.danger,.admonition.caution{background:lightpink}</style>
-<style media="screen and (min-width: 700px)">@media screen and (min-width:700px){#sidebar{width:30%;height:100vh;overflow:auto;position:sticky;top:0}#content{width:70%;max-width:100ch;padding:3em 4em;border-left:1px solid #ddd}pre code{font-size:1em}.item .name{font-size:1em}main{display:flex;flex-direction:row-reverse;justify-content:flex-end}.toc ul ul,#index ul{padding-left:1.5em}.toc > ul > li{margin-top:.5em}}</style>
-<style media="print">@media print{#sidebar h1{page-break-before:always}.source{display:none}}@media print{*{background:transparent !important;color:#000 !important;box-shadow:none !important;text-shadow:none !important}a[href]:after{content:" (" attr(href) ")";font-size:90%}a[href][title]:after{content:none}abbr[title]:after{content:" (" attr(title) ")"}.ir a:after,a[href^="javascript:"]:after,a[href^="#"]:after{content:""}pre,blockquote{border:1px solid #999;page-break-inside:avoid}thead{display:table-header-group}tr,img{page-break-inside:avoid}img{max-width:100% !important}@page{margin:0.5cm}p,h2,h3{orphans:3;widows:3}h1,h2,h3,h4,h5,h6{page-break-after:avoid}}</style>
-<script async src="https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.7/latest.js?config=TeX-AMS_CHTML" integrity="sha256-kZafAc6mZvK3W3v1pHOcUix30OHQN6pU/NO2oFkqZVw=" crossorigin></script>
-<script defer src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/highlight.min.js" integrity="sha256-Uv3H6lx7dJmRfRvH8TH6kJD1TSK1aFcwgx+mdg3epi8=" crossorigin></script>
-<script>window.addEventListener('DOMContentLoaded', () => hljs.initHighlighting())</script>
-</head>
-<body>
-<main>
-<article id="content">
-<header>
-<h1 class="title">Module <code>openunmix.data</code></h1>
-</header>
-<section id="section-intro">
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L0-L974" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">import argparse
-import random
-from pathlib import Path
-from typing import Optional, Union, Tuple, List, Any, Callable
-
-import torch
-import torch.utils.data
-import torchaudio
-import tqdm
-from torchaudio.datasets.utils import bg_iterator
-
-
-def load_info(path: str) -> dict:
- """Load audio metadata
-
- this is a backend_independent wrapper around torchaudio.info
-
- Args:
- path: Path of filename
- Returns:
- Dict: Metadata with
- `samplerate`, `samples` and `duration` in seconds
-
- """
- # get length of file in samples
- if torchaudio.get_audio_backend() == "sox":
- raise RuntimeError("Deprecated backend is not supported")
-
- info = {}
- si = torchaudio.info(str(path))
- info["samplerate"] = si.sample_rate
- info["samples"] = si.num_frames
- info["channels"] = si.num_channels
- info["duration"] = info["samples"] / info["samplerate"]
- return info
-
-
-def load_audio(
- path: str,
- start: float = 0.0,
- dur: Optional[float] = None,
- info: Optional[dict] = None,
-):
- """Load audio file
-
- Args:
- path: Path of audio file
- start: start position in seconds, defaults on the beginning.
- dur: end position in seconds, defaults to `None` (full file).
- info: metadata object as called from `load_info`.
-
- Returns:
- Tensor: torch tensor waveform of shape `(num_channels, num_samples)`
- """
- # loads the full track duration
- if dur is None:
- # we ignore the case where start!=0 and dur=None
- # since we have to deal with fixed length audio
- sig, rate = torchaudio.load(path)
- return sig, rate
- else:
- if info is None:
- info = load_info(path)
- num_frames = int(dur * info["samplerate"])
- frame_offset = int(start * info["samplerate"])
- sig, rate = torchaudio.load(path, num_frames=num_frames, frame_offset=frame_offset)
- return sig, rate
-
-
-def aug_from_str(list_of_function_names: list):
- if list_of_function_names:
- return Compose([globals()["_augment_" + aug] for aug in list_of_function_names])
- else:
- return lambda audio: audio
-
-
-class Compose(object):
- """Composes several augmentation transforms.
- Args:
- augmentations: list of augmentations to compose.
- """
-
- def __init__(self, transforms):
- self.transforms = transforms
-
- def __call__(self, audio: torch.Tensor) -> torch.Tensor:
- for t in self.transforms:
- audio = t(audio)
- return audio
-
-
-def _augment_gain(audio: torch.Tensor, low: float = 0.25, high: float = 1.25) -> torch.Tensor:
- """Applies a random gain between `low` and `high`"""
- g = low + torch.rand(1) * (high - low)
- return audio * g
-
-
-def _augment_channelswap(audio: torch.Tensor) -> torch.Tensor:
- """Swap channels of stereo signals with a probability of p=0.5"""
- if audio.shape[0] == 2 and torch.tensor(1.0).uniform_() < 0.5:
- return torch.flip(audio, [0])
- else:
- return audio
-
-
-def _augment_force_stereo(audio: torch.Tensor) -> torch.Tensor:
- # for multichannel > 2, we drop the other channels
- if audio.shape[0] > 2:
- audio = audio[:2, ...]
-
- if audio.shape[0] == 1:
- # if we have mono, we duplicate it to get stereo
- audio = torch.repeat_interleave(audio, 2, dim=0)
-
- return audio
-
-
-class UnmixDataset(torch.utils.data.Dataset):
- _repr_indent = 4
-
- def __init__(
- self,
- root: Union[Path, str],
- sample_rate: float,
- seq_duration: Optional[float] = None,
- source_augmentations: Optional[Callable] = None,
- ) -> None:
- self.root = Path(args.root).expanduser()
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.source_augmentations = source_augmentations
-
- def __getitem__(self, index: int) -> Any:
- raise NotImplementedError
-
- def __len__(self) -> int:
- raise NotImplementedError
-
- def __repr__(self) -> str:
- head = "Dataset " + self.__class__.__name__
- body = ["Number of datapoints: {}".format(self.__len__())]
- body += self.extra_repr().splitlines()
- lines = [head] + [" " * self._repr_indent + line for line in body]
- return "\n".join(lines)
-
- def extra_repr(self) -> str:
- return ""
-
-
-def load_datasets(
- parser: argparse.ArgumentParser, args: argparse.Namespace
-) -> Tuple[UnmixDataset, UnmixDataset, argparse.Namespace]:
- """Loads the specified dataset from commandline arguments
-
- Returns:
- train_dataset, validation_dataset
- """
- if args.dataset == "aligned":
- parser.add_argument("--input-file", type=str)
- parser.add_argument("--output-file", type=str)
-
- args = parser.parse_args()
- # set output target to basename of output file
- args.target = Path(args.output_file).stem
-
- dataset_kwargs = {
- "root": Path(args.root),
- "seq_duration": args.seq_dur,
- "input_file": args.input_file,
- "output_file": args.output_file,
- }
- args.target = Path(args.output_file).stem
- train_dataset = AlignedDataset(
- split="train", random_chunks=True, **dataset_kwargs
- ) # type: UnmixDataset
- valid_dataset = AlignedDataset(split="valid", **dataset_kwargs) # type: UnmixDataset
-
- elif args.dataset == "sourcefolder":
- parser.add_argument("--interferer-dirs", type=str, nargs="+")
- parser.add_argument("--target-dir", type=str)
- parser.add_argument("--ext", type=str, default=".wav")
- parser.add_argument("--nb-train-samples", type=int, default=1000)
- parser.add_argument("--nb-valid-samples", type=int, default=100)
- parser.add_argument("--source-augmentations", type=str, nargs="+")
- args = parser.parse_args()
- args.target = args.target_dir
-
- dataset_kwargs = {
- "root": Path(args.root),
- "interferer_dirs": args.interferer_dirs,
- "target_dir": args.target_dir,
- "ext": args.ext,
- }
-
- source_augmentations = aug_from_str(args.source_augmentations)
-
- train_dataset = SourceFolderDataset(
- split="train",
- source_augmentations=source_augmentations,
- random_chunks=True,
- nb_samples=args.nb_train_samples,
- seq_duration=args.seq_dur,
- **dataset_kwargs,
- )
-
- valid_dataset = SourceFolderDataset(
- split="valid",
- random_chunks=True,
- seq_duration=args.seq_dur,
- nb_samples=args.nb_valid_samples,
- **dataset_kwargs,
- )
-
- elif args.dataset == "trackfolder_fix":
- parser.add_argument("--target-file", type=str)
- parser.add_argument("--interferer-files", type=str, nargs="+")
- parser.add_argument(
- "--random-track-mix",
- action="store_true",
- default=False,
- help="Apply random track mixing augmentation",
- )
- parser.add_argument("--source-augmentations", type=str, nargs="+")
-
- args = parser.parse_args()
- args.target = Path(args.target_file).stem
-
- dataset_kwargs = {
- "root": Path(args.root),
- "interferer_files": args.interferer_files,
- "target_file": args.target_file,
- }
-
- source_augmentations = aug_from_str(args.source_augmentations)
-
- train_dataset = FixedSourcesTrackFolderDataset(
- split="train",
- source_augmentations=source_augmentations,
- random_track_mix=args.random_track_mix,
- random_chunks=True,
- seq_duration=args.seq_dur,
- **dataset_kwargs,
- )
- valid_dataset = FixedSourcesTrackFolderDataset(
- split="valid", seq_duration=None, **dataset_kwargs
- )
-
- elif args.dataset == "trackfolder_var":
- parser.add_argument("--ext", type=str, default=".wav")
- parser.add_argument("--target-file", type=str)
- parser.add_argument("--source-augmentations", type=str, nargs="+")
- parser.add_argument(
- "--random-interferer-mix",
- action="store_true",
- default=False,
- help="Apply random interferer mixing augmentation",
- )
- parser.add_argument(
- "--silence-missing",
- action="store_true",
- default=False,
- help="silence missing targets",
- )
-
- args = parser.parse_args()
- args.target = Path(args.target_file).stem
-
- dataset_kwargs = {
- "root": Path(args.root),
- "target_file": args.target_file,
- "ext": args.ext,
- "silence_missing_targets": args.silence_missing,
- }
-
- source_augmentations = Compose(
- [globals()["_augment_" + aug] for aug in args.source_augmentations]
- )
-
- train_dataset = VariableSourcesTrackFolderDataset(
- split="train",
- source_augmentations=source_augmentations,
- random_interferer_mix=args.random_interferer_mix,
- random_chunks=True,
- seq_duration=args.seq_dur,
- **dataset_kwargs,
- )
- valid_dataset = VariableSourcesTrackFolderDataset(
- split="valid", seq_duration=None, **dataset_kwargs
- )
-
- else:
- parser.add_argument(
- "--is-wav",
- action="store_true",
- default=False,
- help="loads wav instead of STEMS",
- )
- parser.add_argument("--samples-per-track", type=int, default=64)
- parser.add_argument("--source-augmentations", type=str, nargs="+")
-
- args = parser.parse_args()
- dataset_kwargs = {
- "root": args.root,
- "is_wav": args.is_wav,
- "subsets": "train",
- "target": args.target,
- "download": args.root is None,
- "seed": args.seed,
- }
-
- source_augmentations = aug_from_str(args.source_augmentations)
-
- train_dataset = MUSDBDataset(
- split="train",
- samples_per_track=args.samples_per_track,
- seq_duration=args.seq_dur,
- source_augmentations=source_augmentations,
- random_track_mix=True,
- **dataset_kwargs,
- )
-
- valid_dataset = MUSDBDataset(
- split="valid", samples_per_track=1, seq_duration=None, **dataset_kwargs
- )
-
- return train_dataset, valid_dataset, args
-
-
-class AlignedDataset(UnmixDataset):
- def __init__(
- self,
- root: str,
- split: str = "train",
- input_file: str = "mixture.wav",
- output_file: str = "vocals.wav",
- seq_duration: Optional[float] = None,
- random_chunks: bool = False,
- sample_rate: float = 44100.0,
- source_augmentations: Optional[Callable] = None,
- seed: int = 42,
- ) -> None:
- """A dataset of that assumes multiple track folders
- where each track includes and input and an output file
- which directly corresponds to the the input and the
- output of the model. This dataset is the most basic of
- all datasets provided here, due to the least amount of
- preprocessing, it is also the fastest option, however,
- it lacks any kind of source augmentations or custum mixing.
-
- Typical use cases:
-
- * Source Separation (Mixture -> Target)
- * Denoising (Noisy -> Clean)
- * Bandwidth Extension (Low Bandwidth -> High Bandwidth)
-
- Example
- =======
- data/train/01/mixture.wav --> input
- data/train/01/vocals.wav ---> output
-
- """
- self.root = Path(root).expanduser()
- self.split = split
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.random_chunks = random_chunks
- # set the input and output files (accept glob)
- self.input_file = input_file
- self.output_file = output_file
- self.tuple_paths = list(self._get_paths())
- if not self.tuple_paths:
- raise RuntimeError("Dataset is empty, please check parameters")
- self.seed = seed
- random.seed(self.seed)
-
- def __getitem__(self, index):
- input_path, output_path = self.tuple_paths[index]
-
- if self.random_chunks:
- input_info = load_info(input_path)
- output_info = load_info(output_path)
- duration = min(input_info["duration"], output_info["duration"])
- start = random.uniform(0, duration - self.seq_duration)
- else:
- start = 0
-
- X_audio, _ = load_audio(input_path, start=start, dur=self.seq_duration)
- Y_audio, _ = load_audio(output_path, start=start, dur=self.seq_duration)
- # return torch tensors
- return X_audio, Y_audio
-
- def __len__(self):
- return len(self.tuple_paths)
-
- def _get_paths(self):
- """Loads input and output tracks"""
- p = Path(self.root, self.split)
- for track_path in tqdm.tqdm(p.iterdir()):
- if track_path.is_dir():
- input_path = list(track_path.glob(self.input_file))
- output_path = list(track_path.glob(self.output_file))
- if input_path and output_path:
- if self.seq_duration is not None:
- input_info = load_info(input_path[0])
- output_info = load_info(output_path[0])
- min_duration = min(input_info["duration"], output_info["duration"])
- # check if both targets are available in the subfolder
- if min_duration > self.seq_duration:
- yield input_path[0], output_path[0]
- else:
- yield input_path[0], output_path[0]
-
-
-class SourceFolderDataset(UnmixDataset):
- def __init__(
- self,
- root: str,
- split: str = "train",
- target_dir: str = "vocals",
- interferer_dirs: List[str] = ["bass", "drums"],
- ext: str = ".wav",
- nb_samples: int = 1000,
- seq_duration: Optional[float] = None,
- random_chunks: bool = True,
- sample_rate: float = 44100.0,
- source_augmentations: Optional[Callable] = lambda audio: audio,
- seed: int = 42,
- ) -> None:
- """A dataset that assumes folders of sources,
- instead of track folders. This is a common
- format for speech and environmental sound datasets
- such das DCASE. For each source a variable number of
- tracks/sounds is available, therefore the dataset
- is unaligned by design.
- By default, for each sample, sources from random track are drawn
- to assemble the mixture.
-
- Example
- =======
- train/vocals/track11.wav -----------------\
- train/drums/track202.wav (interferer1) ---+--> input
- train/bass/track007a.wav (interferer2) --/
-
- train/vocals/track11.wav ---------------------> output
-
- """
- self.root = Path(root).expanduser()
- self.split = split
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.ext = ext
- self.random_chunks = random_chunks
- self.source_augmentations = source_augmentations
- self.target_dir = target_dir
- self.interferer_dirs = interferer_dirs
- self.source_folders = self.interferer_dirs + [self.target_dir]
- self.source_tracks = self.get_tracks()
- self.nb_samples = nb_samples
- self.seed = seed
- random.seed(self.seed)
-
- def __getitem__(self, index):
- # For each source draw a random sound and mix them together
- audio_sources = []
- for source in self.source_folders:
- if self.split == "valid":
- # provide deterministic behaviour for validation so that
- # each epoch, the same tracks are yielded
- random.seed(index)
-
- # select a random track for each source
- source_path = random.choice(self.source_tracks[source])
- duration = load_info(source_path)["duration"]
- if self.random_chunks:
- # for each source, select a random chunk
- start = random.uniform(0, duration - self.seq_duration)
- else:
- # use center segment
- start = max(duration // 2 - self.seq_duration // 2, 0)
-
- audio, _ = load_audio(source_path, start=start, dur=self.seq_duration)
- audio = self.source_augmentations(audio)
- audio_sources.append(audio)
-
- stems = torch.stack(audio_sources)
- # # apply linear mix over source index=0
- x = stems.sum(0)
- # target is always the last element in the list
- y = stems[-1]
- return x, y
-
- def __len__(self):
- return self.nb_samples
-
- def get_tracks(self):
- """Loads input and output tracks"""
- p = Path(self.root, self.split)
- source_tracks = {}
- for source_folder in tqdm.tqdm(self.source_folders):
- tracks = []
- source_path = p / source_folder
- for source_track_path in sorted(source_path.glob("*" + self.ext)):
- if self.seq_duration is not None:
- info = load_info(source_track_path)
- # get minimum duration of track
- if info["duration"] > self.seq_duration:
- tracks.append(source_track_path)
- else:
- tracks.append(source_track_path)
- source_tracks[source_folder] = tracks
- return source_tracks
-
-
-class FixedSourcesTrackFolderDataset(UnmixDataset):
- def __init__(
- self,
- root: str,
- split: str = "train",
- target_file: str = "vocals.wav",
- interferer_files: List[str] = ["bass.wav", "drums.wav"],
- seq_duration: Optional[float] = None,
- random_chunks: bool = False,
- random_track_mix: bool = False,
- source_augmentations: Optional[Callable] = lambda audio: audio,
- sample_rate: float = 44100.0,
- seed: int = 42,
- ) -> None:
- """A dataset that assumes audio sources to be stored
- in track folder where each track has a fixed number of sources.
- For each track the users specifies the target file-name (`target_file`)
- and a list of interferences files (`interferer_files`).
- A linear mix is performed on the fly by summing the target and
- the inferers up.
-
- Due to the fact that all tracks comprise the exact same set
- of sources, the random track mixing augmentation technique
- can be used, where sources from different tracks are mixed
- together. Setting `random_track_mix=True` results in an
- unaligned dataset.
- When random track mixing is enabled, we define an epoch as
- when the the target source from all tracks has been seen and only once
- with whatever interfering sources has randomly been drawn.
-
- This dataset is recommended to be used for small/medium size
- for example like the MUSDB18 or other custom source separation
- datasets.
-
- Example
- =======
- train/1/vocals.wav ---------------\
- train/1/drums.wav (interferer1) ---+--> input
- train/1/bass.wav -(interferer2) --/
-
- train/1/vocals.wav -------------------> output
-
- """
- self.root = Path(root).expanduser()
- self.split = split
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.random_track_mix = random_track_mix
- self.random_chunks = random_chunks
- self.source_augmentations = source_augmentations
- # set the input and output files (accept glob)
- self.target_file = target_file
- self.interferer_files = interferer_files
- self.source_files = self.interferer_files + [self.target_file]
- self.seed = seed
- random.seed(self.seed)
-
- self.tracks = list(self.get_tracks())
- if not len(self.tracks):
- raise RuntimeError("No tracks found")
-
- def __getitem__(self, index):
- # first, get target track
- track_path = self.tracks[index]["path"]
- min_duration = self.tracks[index]["min_duration"]
- if self.random_chunks:
- # determine start seek by target duration
- start = random.uniform(0, min_duration - self.seq_duration)
- else:
- start = 0
-
- # assemble the mixture of target and interferers
- audio_sources = []
- # load target
- target_audio, _ = load_audio(
- track_path / self.target_file, start=start, dur=self.seq_duration
- )
- target_audio = self.source_augmentations(target_audio)
- audio_sources.append(target_audio)
- # load interferers
- for source in self.interferer_files:
- # optionally select a random track for each source
- if self.random_track_mix:
- random_idx = random.choice(range(len(self.tracks)))
- track_path = self.tracks[random_idx]["path"]
- if self.random_chunks:
- min_duration = self.tracks[random_idx]["min_duration"]
- start = random.uniform(0, min_duration - self.seq_duration)
-
- audio, _ = load_audio(track_path / source, start=start, dur=self.seq_duration)
- audio = self.source_augmentations(audio)
- audio_sources.append(audio)
-
- stems = torch.stack(audio_sources)
- # # apply linear mix over source index=0
- x = stems.sum(0)
- # target is always the first element in the list
- y = stems[0]
- return x, y
-
- def __len__(self):
- return len(self.tracks)
-
- def get_tracks(self):
- """Loads input and output tracks"""
- p = Path(self.root, self.split)
- for track_path in tqdm.tqdm(p.iterdir()):
- if track_path.is_dir():
- source_paths = [track_path / s for s in self.source_files]
- if not all(sp.exists() for sp in source_paths):
- print("Exclude track ", track_path)
- continue
-
- if self.seq_duration is not None:
- infos = list(map(load_info, source_paths))
- # get minimum duration of track
- min_duration = min(i["duration"] for i in infos)
- if min_duration > self.seq_duration:
- yield ({"path": track_path, "min_duration": min_duration})
- else:
- yield ({"path": track_path, "min_duration": None})
-
-
-class VariableSourcesTrackFolderDataset(UnmixDataset):
- def __init__(
- self,
- root: str,
- split: str = "train",
- target_file: str = "vocals.wav",
- ext: str = ".wav",
- seq_duration: Optional[float] = None,
- random_chunks: bool = False,
- random_interferer_mix: bool = False,
- sample_rate: float = 44100.0,
- source_augmentations: Optional[Callable] = lambda audio: audio,
- silence_missing_targets: bool = False,
- ) -> None:
- """A dataset that assumes audio sources to be stored
- in track folder where each track has a _variable_ number of sources.
- The users specifies the target file-name (`target_file`)
- and the extension of sources to used for mixing.
- A linear mix is performed on the fly by summing all sources in a
- track folder.
-
- Since the number of sources differ per track,
- while target is fixed, a random track mix
- augmentation cannot be used. Instead, a random track
- can be used to load the interfering sources.
-
- Also make sure, that you do not provide the mixture
- file among the sources!
-
- Example
- =======
- train/1/vocals.wav --> input target \
- train/1/drums.wav --> input target |
- train/1/bass.wav --> input target --+--> input
- train/1/accordion.wav --> input target |
- train/1/marimba.wav --> input target /
-
- train/1/vocals.wav -----------------------> output
-
- """
- self.root = Path(root).expanduser()
- self.split = split
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.random_chunks = random_chunks
- self.random_interferer_mix = random_interferer_mix
- self.source_augmentations = source_augmentations
- self.target_file = target_file
- self.ext = ext
- self.silence_missing_targets = silence_missing_targets
- self.tracks = list(self.get_tracks())
-
- def __getitem__(self, index):
- # select the target based on the dataset index
- target_track_path = self.tracks[index]["path"]
- if self.random_chunks:
- target_min_duration = self.tracks[index]["min_duration"]
- target_start = random.uniform(0, target_min_duration - self.seq_duration)
- else:
- target_start = 0
-
- # optionally select a random interferer track
- if self.random_interferer_mix:
- random_idx = random.choice(range(len(self.tracks)))
- intfr_track_path = self.tracks[random_idx]["path"]
- if self.random_chunks:
- intfr_min_duration = self.tracks[random_idx]["min_duration"]
- intfr_start = random.uniform(0, intfr_min_duration - self.seq_duration)
- else:
- intfr_start = 0
- else:
- intfr_track_path = target_track_path
- intfr_start = target_start
-
- # get sources from interferer track
- sources = sorted(list(intfr_track_path.glob("*" + self.ext)))
-
- # load sources
- x = 0
- for source_path in sources:
- # skip target file and load it later
- if source_path == intfr_track_path / self.target_file:
- continue
-
- try:
- audio, _ = load_audio(source_path, start=intfr_start, dur=self.seq_duration)
- except RuntimeError:
- index = index - 1 if index > 0 else index + 1
- return self.__getitem__(index)
- x += self.source_augmentations(audio)
-
- # load the selected track target
- if Path(target_track_path / self.target_file).exists():
- y, _ = load_audio(
- target_track_path / self.target_file,
- start=target_start,
- dur=self.seq_duration,
- )
- y = self.source_augmentations(y)
- x += y
-
- # Use silence if target does not exist
- else:
- y = torch.zeros(audio.shape)
-
- return x, y
-
- def __len__(self):
- return len(self.tracks)
-
- def get_tracks(self):
- p = Path(self.root, self.split)
- for track_path in tqdm.tqdm(p.iterdir()):
- if track_path.is_dir():
- # check if target exists
- if Path(track_path, self.target_file).exists() or self.silence_missing_targets:
- sources = sorted(list(track_path.glob("*" + self.ext)))
- if not sources:
- # in case of empty folder
- print("empty track: ", track_path)
- continue
- if self.seq_duration is not None:
- # check sources
- infos = list(map(load_info, sources))
- # get minimum duration of source
- min_duration = min(i["duration"] for i in infos)
- if min_duration > self.seq_duration:
- yield ({"path": track_path, "min_duration": min_duration})
- else:
- yield ({"path": track_path, "min_duration": None})
-
-
-class MUSDBDataset(UnmixDataset):
- def __init__(
- self,
- target: str = "vocals",
- root: str = None,
- download: bool = False,
- is_wav: bool = False,
- subsets: str = "train",
- split: str = "train",
- seq_duration: Optional[float] = 6.0,
- samples_per_track: int = 64,
- source_augmentations: Optional[Callable] = lambda audio: audio,
- random_track_mix: bool = False,
- seed: int = 42,
- *args,
- **kwargs,
- ) -> None:
- """MUSDB18 torch.data.Dataset that samples from the MUSDB tracks
- using track and excerpts with replacement.
-
- Parameters
- ----------
- target : str
- target name of the source to be separated, defaults to ``vocals``.
- root : str
- root path of MUSDB
- download : boolean
- automatically download 7s preview version of MUSDB
- is_wav : boolean
- specify if the WAV version (instead of the MP4 STEMS) are used
- subsets : list-like [str]
- subset str or list of subset. Defaults to ``train``.
- split : str
- use (stratified) track splits for validation split (``valid``),
- defaults to ``train``.
- seq_duration : float
- training is performed in chunks of ``seq_duration`` (in seconds,
- defaults to ``None`` which loads the full audio track
- samples_per_track : int
- sets the number of samples, yielded from each track per epoch.
- Defaults to 64
- source_augmentations : list[callables]
- provide list of augmentation function that take a multi-channel
- audio file of shape (src, samples) as input and output. Defaults to
- no-augmentations (input = output)
- random_track_mix : boolean
- randomly mixes sources from different tracks to assemble a
- custom mix. This augmenation is only applied for the train subset.
- seed : int
- control randomness of dataset iterations
- args, kwargs : additional keyword arguments
- used to add further control for the musdb dataset
- initialization function.
-
- """
- import musdb
-
- self.seed = seed
- random.seed(seed)
- self.is_wav = is_wav
- self.seq_duration = seq_duration
- self.target = target
- self.subsets = subsets
- self.split = split
- self.samples_per_track = samples_per_track
- self.source_augmentations = source_augmentations
- self.random_track_mix = random_track_mix
- self.mus = musdb.DB(
- root=root,
- is_wav=is_wav,
- split=split,
- subsets=subsets,
- download=download,
- *args,
- **kwargs,
- )
- self.sample_rate = 44100.0 # musdb is fixed sample rate
-
- def __getitem__(self, index):
- audio_sources = []
- target_ind = None
-
- # select track
- track = self.mus.tracks[index // self.samples_per_track]
-
- # at training time we assemble a custom mix
- if self.split == "train" and self.seq_duration:
- for k, source in enumerate(self.mus.setup["sources"]):
- # memorize index of target source
- if source == self.target:
- target_ind = k
-
- # select a random track
- if self.random_track_mix:
- track = random.choice(self.mus.tracks)
-
- # set the excerpt duration
-
- track.chunk_duration = self.seq_duration
- # set random start position
- track.chunk_start = random.uniform(0, track.duration - self.seq_duration)
- # load source audio and apply time domain source_augmentations
- audio = torch.as_tensor(track.sources[source].audio.T, dtype=torch.float32)
- audio = self.source_augmentations(audio)
- audio_sources.append(audio)
-
- # create stem tensor of shape (source, channel, samples)
- stems = torch.stack(audio_sources, dim=0)
- # # apply linear mix over source index=0
- x = stems.sum(0)
- # get the target stem
- if target_ind is not None:
- y = stems[target_ind]
- # assuming vocal/accompaniment scenario if target!=source
- else:
- vocind = list(self.mus.setup["sources"].keys()).index("vocals")
- # apply time domain subtraction
- y = x - stems[vocind]
-
- # for validation and test, we deterministically yield the full
- # pre-mixed musdb track
- else:
- # get the non-linear source mix straight from musdb
- x = torch.as_tensor(track.audio.T, dtype=torch.float32)
- y = torch.as_tensor(track.targets[self.target].audio.T, dtype=torch.float32)
-
- return x, y
-
- def __len__(self):
- return len(self.mus.tracks) * self.samples_per_track
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(description="Open Unmix Trainer")
- parser.add_argument(
- "--dataset",
- type=str,
- default="musdb",
- choices=[
- "musdb",
- "aligned",
- "sourcefolder",
- "trackfolder_var",
- "trackfolder_fix",
- ],
- help="Name of the dataset.",
- )
-
- parser.add_argument("--root", type=str, help="root path of dataset")
-
- parser.add_argument(
- "--save", action="store_true", help=("write out a fixed dataset of samples")
- )
-
- parser.add_argument("--target", type=str, default="vocals")
- parser.add_argument("--seed", type=int, default=42)
- parser.add_argument(
- "--audio-backend",
- type=str,
- default="soundfile",
- help="Set torchaudio backend (`sox_io` or `soundfile`",
- )
-
- # I/O Parameters
- parser.add_argument(
- "--seq-dur",
- type=float,
- default=5.0,
- help="Duration of <=0.0 will result in the full audio",
- )
-
- parser.add_argument("--batch-size", type=int, default=16)
-
- args, _ = parser.parse_known_args()
-
- torchaudio.USE_SOUNDFILE_LEGACY_INTERFACE = False
- torchaudio.set_audio_backend(args.audio_backend)
-
- train_dataset, valid_dataset, args = load_datasets(parser, args)
- print("Audio Backend: ", torchaudio.get_audio_backend())
-
- # Iterate over training dataset and compute statistics
- total_training_duration = 0
- for k in tqdm.tqdm(range(len(train_dataset))):
- x, y = train_dataset[k]
- total_training_duration += x.shape[1] / train_dataset.sample_rate
- if args.save:
- torchaudio.save("test/" + str(k) + "x.wav", x.T, train_dataset.sample_rate)
- torchaudio.save("test/" + str(k) + "y.wav", y.T, train_dataset.sample_rate)
-
- print("Total training duration (h): ", total_training_duration / 3600)
- print("Number of train samples: ", len(train_dataset))
- print("Number of validation samples: ", len(valid_dataset))
-
- # iterate over dataloader
- train_dataset.seq_duration = args.seq_dur
-
- train_sampler = torch.utils.data.DataLoader(
- train_dataset,
- batch_size=args.batch_size,
- shuffle=True,
- num_workers=4,
- )
-
- train_sampler = bg_iterator(train_sampler, 4)
- for x, y in tqdm.tqdm(train_sampler):
- pass</code></pre>
-</details>
-</section>
-<section>
-</section>
-<section>
-</section>
-<section>
-<h2 class="section-title" id="header-functions">Functions</h2>
-<dl>
-<dt id="openunmix.data.aug_from_str"><code class="name flex">
-<span>def <span class="ident">aug_from_str</span></span>(<span>list_of_function_names:Â list)</span>
-</code></dt>
-<dd>
-<div class="desc"></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L70-L74" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def aug_from_str(list_of_function_names: list):
- if list_of_function_names:
- return Compose([globals()["_augment_" + aug] for aug in list_of_function_names])
- else:
- return lambda audio: audio</code></pre>
-</details>
-</dd>
-<dt id="openunmix.data.load_audio"><code class="name flex">
-<span>def <span class="ident">load_audio</span></span>(<span>path: str, start: float = 0.0, dur: Union[float, NoneType] = None, info: Union[dict, NoneType] = None)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Load audio file</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>path</code></strong></dt>
-<dd>Path of audio file</dd>
-<dt><strong><code>start</code></strong></dt>
-<dd>start position in seconds, defaults on the beginning.</dd>
-<dt><strong><code>dur</code></strong></dt>
-<dd>end position in seconds, defaults to <code>None</code> (full file).</dd>
-<dt><strong><code>info</code></strong></dt>
-<dd>metadata object as called from <code><a title="openunmix.data.load_info" href="#openunmix.data.load_info">load_info()</a></code>.</dd>
-</dl>
-<h2 id="returns">Returns</h2>
-<dl>
-<dt><code>Tensor</code></dt>
-<dd>torch tensor waveform of shape <code>(num_channels, num_samples)</code></dd>
-</dl></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L38-L67" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def load_audio(
- path: str,
- start: float = 0.0,
- dur: Optional[float] = None,
- info: Optional[dict] = None,
-):
- """Load audio file
-
- Args:
- path: Path of audio file
- start: start position in seconds, defaults on the beginning.
- dur: end position in seconds, defaults to `None` (full file).
- info: metadata object as called from `load_info`.
-
- Returns:
- Tensor: torch tensor waveform of shape `(num_channels, num_samples)`
- """
- # loads the full track duration
- if dur is None:
- # we ignore the case where start!=0 and dur=None
- # since we have to deal with fixed length audio
- sig, rate = torchaudio.load(path)
- return sig, rate
- else:
- if info is None:
- info = load_info(path)
- num_frames = int(dur * info["samplerate"])
- frame_offset = int(start * info["samplerate"])
- sig, rate = torchaudio.load(path, num_frames=num_frames, frame_offset=frame_offset)
- return sig, rate</code></pre>
-</details>
-</dd>
-<dt id="openunmix.data.load_datasets"><code class="name flex">
-<span>def <span class="ident">load_datasets</span></span>(<span>parser: argparse.ArgumentParser, args: argparse.Namespace) ‑> Tuple[<a title="openunmix.data.UnmixDataset" href="#openunmix.data.UnmixDataset">UnmixDataset</a>, <a title="openunmix.data.UnmixDataset" href="#openunmix.data.UnmixDataset">UnmixDataset</a>, argparse.Namespace]</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Loads the specified dataset from commandline arguments</p>
-<h2 id="returns">Returns</h2>
-<p>train_dataset, validation_dataset</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L150-L326" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def load_datasets(
- parser: argparse.ArgumentParser, args: argparse.Namespace
-) -> Tuple[UnmixDataset, UnmixDataset, argparse.Namespace]:
- """Loads the specified dataset from commandline arguments
-
- Returns:
- train_dataset, validation_dataset
- """
- if args.dataset == "aligned":
- parser.add_argument("--input-file", type=str)
- parser.add_argument("--output-file", type=str)
-
- args = parser.parse_args()
- # set output target to basename of output file
- args.target = Path(args.output_file).stem
-
- dataset_kwargs = {
- "root": Path(args.root),
- "seq_duration": args.seq_dur,
- "input_file": args.input_file,
- "output_file": args.output_file,
- }
- args.target = Path(args.output_file).stem
- train_dataset = AlignedDataset(
- split="train", random_chunks=True, **dataset_kwargs
- ) # type: UnmixDataset
- valid_dataset = AlignedDataset(split="valid", **dataset_kwargs) # type: UnmixDataset
-
- elif args.dataset == "sourcefolder":
- parser.add_argument("--interferer-dirs", type=str, nargs="+")
- parser.add_argument("--target-dir", type=str)
- parser.add_argument("--ext", type=str, default=".wav")
- parser.add_argument("--nb-train-samples", type=int, default=1000)
- parser.add_argument("--nb-valid-samples", type=int, default=100)
- parser.add_argument("--source-augmentations", type=str, nargs="+")
- args = parser.parse_args()
- args.target = args.target_dir
-
- dataset_kwargs = {
- "root": Path(args.root),
- "interferer_dirs": args.interferer_dirs,
- "target_dir": args.target_dir,
- "ext": args.ext,
- }
-
- source_augmentations = aug_from_str(args.source_augmentations)
-
- train_dataset = SourceFolderDataset(
- split="train",
- source_augmentations=source_augmentations,
- random_chunks=True,
- nb_samples=args.nb_train_samples,
- seq_duration=args.seq_dur,
- **dataset_kwargs,
- )
-
- valid_dataset = SourceFolderDataset(
- split="valid",
- random_chunks=True,
- seq_duration=args.seq_dur,
- nb_samples=args.nb_valid_samples,
- **dataset_kwargs,
- )
-
- elif args.dataset == "trackfolder_fix":
- parser.add_argument("--target-file", type=str)
- parser.add_argument("--interferer-files", type=str, nargs="+")
- parser.add_argument(
- "--random-track-mix",
- action="store_true",
- default=False,
- help="Apply random track mixing augmentation",
- )
- parser.add_argument("--source-augmentations", type=str, nargs="+")
-
- args = parser.parse_args()
- args.target = Path(args.target_file).stem
-
- dataset_kwargs = {
- "root": Path(args.root),
- "interferer_files": args.interferer_files,
- "target_file": args.target_file,
- }
-
- source_augmentations = aug_from_str(args.source_augmentations)
-
- train_dataset = FixedSourcesTrackFolderDataset(
- split="train",
- source_augmentations=source_augmentations,
- random_track_mix=args.random_track_mix,
- random_chunks=True,
- seq_duration=args.seq_dur,
- **dataset_kwargs,
- )
- valid_dataset = FixedSourcesTrackFolderDataset(
- split="valid", seq_duration=None, **dataset_kwargs
- )
-
- elif args.dataset == "trackfolder_var":
- parser.add_argument("--ext", type=str, default=".wav")
- parser.add_argument("--target-file", type=str)
- parser.add_argument("--source-augmentations", type=str, nargs="+")
- parser.add_argument(
- "--random-interferer-mix",
- action="store_true",
- default=False,
- help="Apply random interferer mixing augmentation",
- )
- parser.add_argument(
- "--silence-missing",
- action="store_true",
- default=False,
- help="silence missing targets",
- )
-
- args = parser.parse_args()
- args.target = Path(args.target_file).stem
-
- dataset_kwargs = {
- "root": Path(args.root),
- "target_file": args.target_file,
- "ext": args.ext,
- "silence_missing_targets": args.silence_missing,
- }
-
- source_augmentations = Compose(
- [globals()["_augment_" + aug] for aug in args.source_augmentations]
- )
-
- train_dataset = VariableSourcesTrackFolderDataset(
- split="train",
- source_augmentations=source_augmentations,
- random_interferer_mix=args.random_interferer_mix,
- random_chunks=True,
- seq_duration=args.seq_dur,
- **dataset_kwargs,
- )
- valid_dataset = VariableSourcesTrackFolderDataset(
- split="valid", seq_duration=None, **dataset_kwargs
- )
-
- else:
- parser.add_argument(
- "--is-wav",
- action="store_true",
- default=False,
- help="loads wav instead of STEMS",
- )
- parser.add_argument("--samples-per-track", type=int, default=64)
- parser.add_argument("--source-augmentations", type=str, nargs="+")
-
- args = parser.parse_args()
- dataset_kwargs = {
- "root": args.root,
- "is_wav": args.is_wav,
- "subsets": "train",
- "target": args.target,
- "download": args.root is None,
- "seed": args.seed,
- }
-
- source_augmentations = aug_from_str(args.source_augmentations)
-
- train_dataset = MUSDBDataset(
- split="train",
- samples_per_track=args.samples_per_track,
- seq_duration=args.seq_dur,
- source_augmentations=source_augmentations,
- random_track_mix=True,
- **dataset_kwargs,
- )
-
- valid_dataset = MUSDBDataset(
- split="valid", samples_per_track=1, seq_duration=None, **dataset_kwargs
- )
-
- return train_dataset, valid_dataset, args</code></pre>
-</details>
-</dd>
-<dt id="openunmix.data.load_info"><code class="name flex">
-<span>def <span class="ident">load_info</span></span>(<span>path: str) ‑> dict</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Load audio metadata</p>
-<p>this is a backend_independent wrapper around torchaudio.info</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>path</code></strong></dt>
-<dd>Path of filename</dd>
-</dl>
-<h2 id="returns">Returns</h2>
-<dl>
-<dt><code>Dict</code></dt>
-<dd>Metadata with</dd>
-</dl>
-<p><code>samplerate</code>, <code>samples</code> and <code>duration</code> in seconds</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L13-L35" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def load_info(path: str) -> dict:
- """Load audio metadata
-
- this is a backend_independent wrapper around torchaudio.info
-
- Args:
- path: Path of filename
- Returns:
- Dict: Metadata with
- `samplerate`, `samples` and `duration` in seconds
-
- """
- # get length of file in samples
- if torchaudio.get_audio_backend() == "sox":
- raise RuntimeError("Deprecated backend is not supported")
-
- info = {}
- si = torchaudio.info(str(path))
- info["samplerate"] = si.sample_rate
- info["samples"] = si.num_frames
- info["channels"] = si.num_channels
- info["duration"] = info["samples"] / info["samplerate"]
- return info</code></pre>
-</details>
-</dd>
-</dl>
-</section>
-<section>
-<h2 class="section-title" id="header-classes">Classes</h2>
-<dl>
-<dt id="openunmix.data.AlignedDataset"><code class="flex name class">
-<span>class <span class="ident">AlignedDataset</span></span>
-<span>(</span><span>root: str, split: str = 'train', input_file: str = 'mixture.wav', output_file: str = 'vocals.wav', seq_duration: Union[float, NoneType] = None, random_chunks: bool = False, sample_rate: float = 44100.0, source_augmentations: Union[Callable, NoneType] = None, seed: int = 42)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>An abstract class representing a :class:<code>Dataset</code>.</p>
-<p>All datasets that represent a map from keys to data samples should subclass
-it. All subclasses should overwrite :meth:<code>__getitem__</code>, supporting fetching a
-data sample for a given key. Subclasses could also optionally overwrite
-:meth:<code>__len__</code>, which is expected to return the size of the dataset by many
-:class:<code>~torch.utils.data.Sampler</code> implementations and the default options
-of :class:<code>~torch.utils.data.DataLoader</code>.</p>
-<div class="admonition note">
-<p class="admonition-title">Note</p>
-<p>:class:<code>~torch.utils.data.DataLoader</code> by default constructs a index
-sampler that yields integral indices.
-To make it work with a map-style
-dataset with non-integral indices/keys, a custom sampler must be provided.</p>
-</div>
-<p>A dataset of that assumes multiple track folders
-where each track includes and input and an output file
-which directly corresponds to the the input and the
-output of the model. This dataset is the most basic of
-all datasets provided here, due to the least amount of
-preprocessing, it is also the fastest option, however,
-it lacks any kind of source augmentations or custum mixing.</p>
-<p>Typical use cases:</p>
-<ul>
-<li>Source Separation (Mixture -> Target)</li>
-<li>Denoising (Noisy -> Clean)</li>
-<li>Bandwidth Extension (Low Bandwidth -> High Bandwidth)</li>
-</ul>
-<h1 id="example">Example</h1>
-<p>data/train/01/mixture.wav –> input
-data/train/01/vocals.wav —> output</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L329-L411" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class AlignedDataset(UnmixDataset):
- def __init__(
- self,
- root: str,
- split: str = "train",
- input_file: str = "mixture.wav",
- output_file: str = "vocals.wav",
- seq_duration: Optional[float] = None,
- random_chunks: bool = False,
- sample_rate: float = 44100.0,
- source_augmentations: Optional[Callable] = None,
- seed: int = 42,
- ) -> None:
- """A dataset of that assumes multiple track folders
- where each track includes and input and an output file
- which directly corresponds to the the input and the
- output of the model. This dataset is the most basic of
- all datasets provided here, due to the least amount of
- preprocessing, it is also the fastest option, however,
- it lacks any kind of source augmentations or custum mixing.
-
- Typical use cases:
-
- * Source Separation (Mixture -> Target)
- * Denoising (Noisy -> Clean)
- * Bandwidth Extension (Low Bandwidth -> High Bandwidth)
-
- Example
- =======
- data/train/01/mixture.wav --> input
- data/train/01/vocals.wav ---> output
-
- """
- self.root = Path(root).expanduser()
- self.split = split
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.random_chunks = random_chunks
- # set the input and output files (accept glob)
- self.input_file = input_file
- self.output_file = output_file
- self.tuple_paths = list(self._get_paths())
- if not self.tuple_paths:
- raise RuntimeError("Dataset is empty, please check parameters")
- self.seed = seed
- random.seed(self.seed)
-
- def __getitem__(self, index):
- input_path, output_path = self.tuple_paths[index]
-
- if self.random_chunks:
- input_info = load_info(input_path)
- output_info = load_info(output_path)
- duration = min(input_info["duration"], output_info["duration"])
- start = random.uniform(0, duration - self.seq_duration)
- else:
- start = 0
-
- X_audio, _ = load_audio(input_path, start=start, dur=self.seq_duration)
- Y_audio, _ = load_audio(output_path, start=start, dur=self.seq_duration)
- # return torch tensors
- return X_audio, Y_audio
-
- def __len__(self):
- return len(self.tuple_paths)
-
- def _get_paths(self):
- """Loads input and output tracks"""
- p = Path(self.root, self.split)
- for track_path in tqdm.tqdm(p.iterdir()):
- if track_path.is_dir():
- input_path = list(track_path.glob(self.input_file))
- output_path = list(track_path.glob(self.output_file))
- if input_path and output_path:
- if self.seq_duration is not None:
- input_info = load_info(input_path[0])
- output_info = load_info(output_path[0])
- min_duration = min(input_info["duration"], output_info["duration"])
- # check if both targets are available in the subfolder
- if min_duration > self.seq_duration:
- yield input_path[0], output_path[0]
- else:
- yield input_path[0], output_path[0]</code></pre>
-</details>
-<h3>Ancestors</h3>
-<ul class="hlist">
-<li><a title="openunmix.data.UnmixDataset" href="#openunmix.data.UnmixDataset">UnmixDataset</a></li>
-<li>torch.utils.data.dataset.Dataset</li>
-<li>typing.Generic</li>
-</ul>
-</dd>
-<dt id="openunmix.data.Compose"><code class="flex name class">
-<span>class <span class="ident">Compose</span></span>
-<span>(</span><span>transforms)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Composes several augmentation transforms.</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>augmentations</code></strong></dt>
-<dd>list of augmentations to compose.</dd>
-</dl></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L77-L89" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class Compose(object):
- """Composes several augmentation transforms.
- Args:
- augmentations: list of augmentations to compose.
- """
-
- def __init__(self, transforms):
- self.transforms = transforms
-
- def __call__(self, audio: torch.Tensor) -> torch.Tensor:
- for t in self.transforms:
- audio = t(audio)
- return audio</code></pre>
-</details>
-</dd>
-<dt id="openunmix.data.FixedSourcesTrackFolderDataset"><code class="flex name class">
-<span>class <span class="ident">FixedSourcesTrackFolderDataset</span></span>
-<span>(</span><span>root: str, split: str = 'train', target_file: str = 'vocals.wav', interferer_files: List[str] = ['bass.wav', 'drums.wav'], seq_duration: Union[float, NoneType] = None, random_chunks: bool = False, random_track_mix: bool = False, source_augmentations: Union[Callable, NoneType] = <function FixedSourcesTrackFolderDataset.<lambda>>, sample_rate: float = 44100.0, seed: int = 42)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>An abstract class representing a :class:<code>Dataset</code>.</p>
-<p>All datasets that represent a map from keys to data samples should subclass
-it. All subclasses should overwrite :meth:<code>__getitem__</code>, supporting fetching a
-data sample for a given key. Subclasses could also optionally overwrite
-:meth:<code>__len__</code>, which is expected to return the size of the dataset by many
-:class:<code>~torch.utils.data.Sampler</code> implementations and the default options
-of :class:<code>~torch.utils.data.DataLoader</code>.</p>
-<div class="admonition note">
-<p class="admonition-title">Note</p>
-<p>:class:<code>~torch.utils.data.DataLoader</code> by default constructs a index
-sampler that yields integral indices.
-To make it work with a map-style
-dataset with non-integral indices/keys, a custom sampler must be provided.</p>
-</div>
-<p>A dataset that assumes audio sources to be stored
-in track folder where each track has a fixed number of sources.
-For each track the users specifies the target file-name (<code>target_file</code>)
-and a list of interferences files (<code>interferer_files</code>).
-A linear mix is performed on the fly by summing the target and
-the inferers up.</p>
-<p>Due to the fact that all tracks comprise the exact same set
-of sources, the random track mixing augmentation technique
-can be used, where sources from different tracks are mixed
-together. Setting <code>random_track_mix=True</code> results in an
-unaligned dataset.
-When random track mixing is enabled, we define an epoch as
-when the the target source from all tracks has been seen and only once
-with whatever interfering sources has randomly been drawn.</p>
-<p>This dataset is recommended to be used for small/medium size
-for example like the MUSDB18 or other custom source separation
-datasets.</p>
-<h1 id="example">Example</h1>
-<p>train/1/vocals.wav ---------------
-train/1/drums.wav (interferer1) —+–> input
-train/1/bass.wav -(interferer2) –/</p>
-<p>train/1/vocals.wav -------------------> output</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L514-L634" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class FixedSourcesTrackFolderDataset(UnmixDataset):
- def __init__(
- self,
- root: str,
- split: str = "train",
- target_file: str = "vocals.wav",
- interferer_files: List[str] = ["bass.wav", "drums.wav"],
- seq_duration: Optional[float] = None,
- random_chunks: bool = False,
- random_track_mix: bool = False,
- source_augmentations: Optional[Callable] = lambda audio: audio,
- sample_rate: float = 44100.0,
- seed: int = 42,
- ) -> None:
- """A dataset that assumes audio sources to be stored
- in track folder where each track has a fixed number of sources.
- For each track the users specifies the target file-name (`target_file`)
- and a list of interferences files (`interferer_files`).
- A linear mix is performed on the fly by summing the target and
- the inferers up.
-
- Due to the fact that all tracks comprise the exact same set
- of sources, the random track mixing augmentation technique
- can be used, where sources from different tracks are mixed
- together. Setting `random_track_mix=True` results in an
- unaligned dataset.
- When random track mixing is enabled, we define an epoch as
- when the the target source from all tracks has been seen and only once
- with whatever interfering sources has randomly been drawn.
-
- This dataset is recommended to be used for small/medium size
- for example like the MUSDB18 or other custom source separation
- datasets.
-
- Example
- =======
- train/1/vocals.wav ---------------\
- train/1/drums.wav (interferer1) ---+--> input
- train/1/bass.wav -(interferer2) --/
-
- train/1/vocals.wav -------------------> output
-
- """
- self.root = Path(root).expanduser()
- self.split = split
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.random_track_mix = random_track_mix
- self.random_chunks = random_chunks
- self.source_augmentations = source_augmentations
- # set the input and output files (accept glob)
- self.target_file = target_file
- self.interferer_files = interferer_files
- self.source_files = self.interferer_files + [self.target_file]
- self.seed = seed
- random.seed(self.seed)
-
- self.tracks = list(self.get_tracks())
- if not len(self.tracks):
- raise RuntimeError("No tracks found")
-
- def __getitem__(self, index):
- # first, get target track
- track_path = self.tracks[index]["path"]
- min_duration = self.tracks[index]["min_duration"]
- if self.random_chunks:
- # determine start seek by target duration
- start = random.uniform(0, min_duration - self.seq_duration)
- else:
- start = 0
-
- # assemble the mixture of target and interferers
- audio_sources = []
- # load target
- target_audio, _ = load_audio(
- track_path / self.target_file, start=start, dur=self.seq_duration
- )
- target_audio = self.source_augmentations(target_audio)
- audio_sources.append(target_audio)
- # load interferers
- for source in self.interferer_files:
- # optionally select a random track for each source
- if self.random_track_mix:
- random_idx = random.choice(range(len(self.tracks)))
- track_path = self.tracks[random_idx]["path"]
- if self.random_chunks:
- min_duration = self.tracks[random_idx]["min_duration"]
- start = random.uniform(0, min_duration - self.seq_duration)
-
- audio, _ = load_audio(track_path / source, start=start, dur=self.seq_duration)
- audio = self.source_augmentations(audio)
- audio_sources.append(audio)
-
- stems = torch.stack(audio_sources)
- # # apply linear mix over source index=0
- x = stems.sum(0)
- # target is always the first element in the list
- y = stems[0]
- return x, y
-
- def __len__(self):
- return len(self.tracks)
-
- def get_tracks(self):
- """Loads input and output tracks"""
- p = Path(self.root, self.split)
- for track_path in tqdm.tqdm(p.iterdir()):
- if track_path.is_dir():
- source_paths = [track_path / s for s in self.source_files]
- if not all(sp.exists() for sp in source_paths):
- print("Exclude track ", track_path)
- continue
-
- if self.seq_duration is not None:
- infos = list(map(load_info, source_paths))
- # get minimum duration of track
- min_duration = min(i["duration"] for i in infos)
- if min_duration > self.seq_duration:
- yield ({"path": track_path, "min_duration": min_duration})
- else:
- yield ({"path": track_path, "min_duration": None})</code></pre>
-</details>
-<h3>Ancestors</h3>
-<ul class="hlist">
-<li><a title="openunmix.data.UnmixDataset" href="#openunmix.data.UnmixDataset">UnmixDataset</a></li>
-<li>torch.utils.data.dataset.Dataset</li>
-<li>typing.Generic</li>
-</ul>
-<h3>Methods</h3>
-<dl>
-<dt id="openunmix.data.FixedSourcesTrackFolderDataset.get_tracks"><code class="name flex">
-<span>def <span class="ident">get_tracks</span></span>(<span>self)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Loads input and output tracks</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L617-L634" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def get_tracks(self):
- """Loads input and output tracks"""
- p = Path(self.root, self.split)
- for track_path in tqdm.tqdm(p.iterdir()):
- if track_path.is_dir():
- source_paths = [track_path / s for s in self.source_files]
- if not all(sp.exists() for sp in source_paths):
- print("Exclude track ", track_path)
- continue
-
- if self.seq_duration is not None:
- infos = list(map(load_info, source_paths))
- # get minimum duration of track
- min_duration = min(i["duration"] for i in infos)
- if min_duration > self.seq_duration:
- yield ({"path": track_path, "min_duration": min_duration})
- else:
- yield ({"path": track_path, "min_duration": None})</code></pre>
-</details>
-</dd>
-</dl>
-</dd>
-<dt id="openunmix.data.MUSDBDataset"><code class="flex name class">
-<span>class <span class="ident">MUSDBDataset</span></span>
-<span>(</span><span>target: str = 'vocals', root: str = None, download: bool = False, is_wav: bool = False, subsets: str = 'train', split: str = 'train', seq_duration: Union[float, NoneType] = 6.0, samples_per_track: int = 64, source_augmentations: Union[Callable, NoneType] = <function MUSDBDataset.<lambda>>, random_track_mix: bool = False, seed: int = 42, *args, **kwargs)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>An abstract class representing a :class:<code>Dataset</code>.</p>
-<p>All datasets that represent a map from keys to data samples should subclass
-it. All subclasses should overwrite :meth:<code>__getitem__</code>, supporting fetching a
-data sample for a given key. Subclasses could also optionally overwrite
-:meth:<code>__len__</code>, which is expected to return the size of the dataset by many
-:class:<code>~torch.utils.data.Sampler</code> implementations and the default options
-of :class:<code>~torch.utils.data.DataLoader</code>.</p>
-<div class="admonition note">
-<p class="admonition-title">Note</p>
-<p>:class:<code>~torch.utils.data.DataLoader</code> by default constructs a index
-sampler that yields integral indices.
-To make it work with a map-style
-dataset with non-integral indices/keys, a custom sampler must be provided.</p>
-</div>
-<p>MUSDB18 torch.data.Dataset that samples from the MUSDB tracks
-using track and excerpts with replacement.</p>
-<h2 id="parameters">Parameters</h2>
-<dl>
-<dt><strong><code>target</code></strong> : <code>str</code></dt>
-<dd>target name of the source to be separated, defaults to <code>vocals</code>.</dd>
-<dt><strong><code>root</code></strong> : <code>str</code></dt>
-<dd>root path of MUSDB</dd>
-<dt><strong><code>download</code></strong> : <code>boolean</code></dt>
-<dd>automatically download 7s preview version of MUSDB</dd>
-<dt><strong><code>is_wav</code></strong> : <code>boolean</code></dt>
-<dd>specify if the WAV version (instead of the MP4 STEMS) are used</dd>
-<dt><strong><code>subsets</code></strong> : <code>list-like [str]</code></dt>
-<dd>subset str or list of subset. Defaults to <code>train</code>.</dd>
-<dt><strong><code>split</code></strong> : <code>str</code></dt>
-<dd>use (stratified) track splits for validation split (<code>valid</code>),
-defaults to <code>train</code>.</dd>
-<dt><strong><code>seq_duration</code></strong> : <code>float</code></dt>
-<dd>training is performed in chunks of <code>seq_duration</code> (in seconds,
-defaults to <code>None</code> which loads the full audio track</dd>
-<dt><strong><code>samples_per_track</code></strong> : <code>int</code></dt>
-<dd>sets the number of samples, yielded from each track per epoch.
-Defaults to 64</dd>
-<dt><strong><code>source_augmentations</code></strong> : <code>list[callables]</code></dt>
-<dd>provide list of augmentation function that take a multi-channel
-audio file of shape (src, samples) as input and output. Defaults to
-no-augmentations (input = output)</dd>
-<dt><strong><code>random_track_mix</code></strong> : <code>boolean</code></dt>
-<dd>randomly mixes sources from different tracks to assemble a
-custom mix. This augmenation is only applied for the train subset.</dd>
-<dt><strong><code>seed</code></strong> : <code>int</code></dt>
-<dd>control randomness of dataset iterations</dd>
-<dt><strong><code>args</code></strong>, <strong><code>kwargs</code></strong> : <code>additional keyword arguments</code></dt>
-<dd>used to add further control for the musdb dataset
-initialization function.</dd>
-</dl></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L769-L898" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class MUSDBDataset(UnmixDataset):
- def __init__(
- self,
- target: str = "vocals",
- root: str = None,
- download: bool = False,
- is_wav: bool = False,
- subsets: str = "train",
- split: str = "train",
- seq_duration: Optional[float] = 6.0,
- samples_per_track: int = 64,
- source_augmentations: Optional[Callable] = lambda audio: audio,
- random_track_mix: bool = False,
- seed: int = 42,
- *args,
- **kwargs,
- ) -> None:
- """MUSDB18 torch.data.Dataset that samples from the MUSDB tracks
- using track and excerpts with replacement.
-
- Parameters
- ----------
- target : str
- target name of the source to be separated, defaults to ``vocals``.
- root : str
- root path of MUSDB
- download : boolean
- automatically download 7s preview version of MUSDB
- is_wav : boolean
- specify if the WAV version (instead of the MP4 STEMS) are used
- subsets : list-like [str]
- subset str or list of subset. Defaults to ``train``.
- split : str
- use (stratified) track splits for validation split (``valid``),
- defaults to ``train``.
- seq_duration : float
- training is performed in chunks of ``seq_duration`` (in seconds,
- defaults to ``None`` which loads the full audio track
- samples_per_track : int
- sets the number of samples, yielded from each track per epoch.
- Defaults to 64
- source_augmentations : list[callables]
- provide list of augmentation function that take a multi-channel
- audio file of shape (src, samples) as input and output. Defaults to
- no-augmentations (input = output)
- random_track_mix : boolean
- randomly mixes sources from different tracks to assemble a
- custom mix. This augmenation is only applied for the train subset.
- seed : int
- control randomness of dataset iterations
- args, kwargs : additional keyword arguments
- used to add further control for the musdb dataset
- initialization function.
-
- """
- import musdb
-
- self.seed = seed
- random.seed(seed)
- self.is_wav = is_wav
- self.seq_duration = seq_duration
- self.target = target
- self.subsets = subsets
- self.split = split
- self.samples_per_track = samples_per_track
- self.source_augmentations = source_augmentations
- self.random_track_mix = random_track_mix
- self.mus = musdb.DB(
- root=root,
- is_wav=is_wav,
- split=split,
- subsets=subsets,
- download=download,
- *args,
- **kwargs,
- )
- self.sample_rate = 44100.0 # musdb is fixed sample rate
-
- def __getitem__(self, index):
- audio_sources = []
- target_ind = None
-
- # select track
- track = self.mus.tracks[index // self.samples_per_track]
-
- # at training time we assemble a custom mix
- if self.split == "train" and self.seq_duration:
- for k, source in enumerate(self.mus.setup["sources"]):
- # memorize index of target source
- if source == self.target:
- target_ind = k
-
- # select a random track
- if self.random_track_mix:
- track = random.choice(self.mus.tracks)
-
- # set the excerpt duration
-
- track.chunk_duration = self.seq_duration
- # set random start position
- track.chunk_start = random.uniform(0, track.duration - self.seq_duration)
- # load source audio and apply time domain source_augmentations
- audio = torch.as_tensor(track.sources[source].audio.T, dtype=torch.float32)
- audio = self.source_augmentations(audio)
- audio_sources.append(audio)
-
- # create stem tensor of shape (source, channel, samples)
- stems = torch.stack(audio_sources, dim=0)
- # # apply linear mix over source index=0
- x = stems.sum(0)
- # get the target stem
- if target_ind is not None:
- y = stems[target_ind]
- # assuming vocal/accompaniment scenario if target!=source
- else:
- vocind = list(self.mus.setup["sources"].keys()).index("vocals")
- # apply time domain subtraction
- y = x - stems[vocind]
-
- # for validation and test, we deterministically yield the full
- # pre-mixed musdb track
- else:
- # get the non-linear source mix straight from musdb
- x = torch.as_tensor(track.audio.T, dtype=torch.float32)
- y = torch.as_tensor(track.targets[self.target].audio.T, dtype=torch.float32)
-
- return x, y
-
- def __len__(self):
- return len(self.mus.tracks) * self.samples_per_track</code></pre>
-</details>
-<h3>Ancestors</h3>
-<ul class="hlist">
-<li><a title="openunmix.data.UnmixDataset" href="#openunmix.data.UnmixDataset">UnmixDataset</a></li>
-<li>torch.utils.data.dataset.Dataset</li>
-<li>typing.Generic</li>
-</ul>
-</dd>
-<dt id="openunmix.data.SourceFolderDataset"><code class="flex name class">
-<span>class <span class="ident">SourceFolderDataset</span></span>
-<span>(</span><span>root: str, split: str = 'train', target_dir: str = 'vocals', interferer_dirs: List[str] = ['bass', 'drums'], ext: str = '.wav', nb_samples: int = 1000, seq_duration: Union[float, NoneType] = None, random_chunks: bool = True, sample_rate: float = 44100.0, source_augmentations: Union[Callable, NoneType] = <function SourceFolderDataset.<lambda>>, seed: int = 42)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>An abstract class representing a :class:<code>Dataset</code>.</p>
-<p>All datasets that represent a map from keys to data samples should subclass
-it. All subclasses should overwrite :meth:<code>__getitem__</code>, supporting fetching a
-data sample for a given key. Subclasses could also optionally overwrite
-:meth:<code>__len__</code>, which is expected to return the size of the dataset by many
-:class:<code>~torch.utils.data.Sampler</code> implementations and the default options
-of :class:<code>~torch.utils.data.DataLoader</code>.</p>
-<div class="admonition note">
-<p class="admonition-title">Note</p>
-<p>:class:<code>~torch.utils.data.DataLoader</code> by default constructs a index
-sampler that yields integral indices.
-To make it work with a map-style
-dataset with non-integral indices/keys, a custom sampler must be provided.</p>
-</div>
-<p>A dataset that assumes folders of sources,
-instead of track folders. This is a common
-format for speech and environmental sound datasets
-such das DCASE. For each source a variable number of
-tracks/sounds is available, therefore the dataset
-is unaligned by design.
-By default, for each sample, sources from random track are drawn
-to assemble the mixture.</p>
-<h1 id="example">Example</h1>
-<p>train/vocals/track11.wav -----------------
-train/drums/track202.wav
-(interferer1) —+–> input
-train/bass/track007a.wav
-(interferer2) –/</p>
-<p>train/vocals/track11.wav ---------------------> output</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L414-L511" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class SourceFolderDataset(UnmixDataset):
- def __init__(
- self,
- root: str,
- split: str = "train",
- target_dir: str = "vocals",
- interferer_dirs: List[str] = ["bass", "drums"],
- ext: str = ".wav",
- nb_samples: int = 1000,
- seq_duration: Optional[float] = None,
- random_chunks: bool = True,
- sample_rate: float = 44100.0,
- source_augmentations: Optional[Callable] = lambda audio: audio,
- seed: int = 42,
- ) -> None:
- """A dataset that assumes folders of sources,
- instead of track folders. This is a common
- format for speech and environmental sound datasets
- such das DCASE. For each source a variable number of
- tracks/sounds is available, therefore the dataset
- is unaligned by design.
- By default, for each sample, sources from random track are drawn
- to assemble the mixture.
-
- Example
- =======
- train/vocals/track11.wav -----------------\
- train/drums/track202.wav (interferer1) ---+--> input
- train/bass/track007a.wav (interferer2) --/
-
- train/vocals/track11.wav ---------------------> output
-
- """
- self.root = Path(root).expanduser()
- self.split = split
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.ext = ext
- self.random_chunks = random_chunks
- self.source_augmentations = source_augmentations
- self.target_dir = target_dir
- self.interferer_dirs = interferer_dirs
- self.source_folders = self.interferer_dirs + [self.target_dir]
- self.source_tracks = self.get_tracks()
- self.nb_samples = nb_samples
- self.seed = seed
- random.seed(self.seed)
-
- def __getitem__(self, index):
- # For each source draw a random sound and mix them together
- audio_sources = []
- for source in self.source_folders:
- if self.split == "valid":
- # provide deterministic behaviour for validation so that
- # each epoch, the same tracks are yielded
- random.seed(index)
-
- # select a random track for each source
- source_path = random.choice(self.source_tracks[source])
- duration = load_info(source_path)["duration"]
- if self.random_chunks:
- # for each source, select a random chunk
- start = random.uniform(0, duration - self.seq_duration)
- else:
- # use center segment
- start = max(duration // 2 - self.seq_duration // 2, 0)
-
- audio, _ = load_audio(source_path, start=start, dur=self.seq_duration)
- audio = self.source_augmentations(audio)
- audio_sources.append(audio)
-
- stems = torch.stack(audio_sources)
- # # apply linear mix over source index=0
- x = stems.sum(0)
- # target is always the last element in the list
- y = stems[-1]
- return x, y
-
- def __len__(self):
- return self.nb_samples
-
- def get_tracks(self):
- """Loads input and output tracks"""
- p = Path(self.root, self.split)
- source_tracks = {}
- for source_folder in tqdm.tqdm(self.source_folders):
- tracks = []
- source_path = p / source_folder
- for source_track_path in sorted(source_path.glob("*" + self.ext)):
- if self.seq_duration is not None:
- info = load_info(source_track_path)
- # get minimum duration of track
- if info["duration"] > self.seq_duration:
- tracks.append(source_track_path)
- else:
- tracks.append(source_track_path)
- source_tracks[source_folder] = tracks
- return source_tracks</code></pre>
-</details>
-<h3>Ancestors</h3>
-<ul class="hlist">
-<li><a title="openunmix.data.UnmixDataset" href="#openunmix.data.UnmixDataset">UnmixDataset</a></li>
-<li>torch.utils.data.dataset.Dataset</li>
-<li>typing.Generic</li>
-</ul>
-<h3>Methods</h3>
-<dl>
-<dt id="openunmix.data.SourceFolderDataset.get_tracks"><code class="name flex">
-<span>def <span class="ident">get_tracks</span></span>(<span>self)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Loads input and output tracks</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L495-L511" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def get_tracks(self):
- """Loads input and output tracks"""
- p = Path(self.root, self.split)
- source_tracks = {}
- for source_folder in tqdm.tqdm(self.source_folders):
- tracks = []
- source_path = p / source_folder
- for source_track_path in sorted(source_path.glob("*" + self.ext)):
- if self.seq_duration is not None:
- info = load_info(source_track_path)
- # get minimum duration of track
- if info["duration"] > self.seq_duration:
- tracks.append(source_track_path)
- else:
- tracks.append(source_track_path)
- source_tracks[source_folder] = tracks
- return source_tracks</code></pre>
-</details>
-</dd>
-</dl>
-</dd>
-<dt id="openunmix.data.UnmixDataset"><code class="flex name class">
-<span>class <span class="ident">UnmixDataset</span></span>
-<span>(</span><span>root: Union[pathlib.Path, str], sample_rate: float, seq_duration: Union[float, NoneType] = None, source_augmentations: Union[Callable, NoneType] = None)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>An abstract class representing a :class:<code>Dataset</code>.</p>
-<p>All datasets that represent a map from keys to data samples should subclass
-it. All subclasses should overwrite :meth:<code>__getitem__</code>, supporting fetching a
-data sample for a given key. Subclasses could also optionally overwrite
-:meth:<code>__len__</code>, which is expected to return the size of the dataset by many
-:class:<code>~torch.utils.data.Sampler</code> implementations and the default options
-of :class:<code>~torch.utils.data.DataLoader</code>.</p>
-<div class="admonition note">
-<p class="admonition-title">Note</p>
-<p>:class:<code>~torch.utils.data.DataLoader</code> by default constructs a index
-sampler that yields integral indices.
-To make it work with a map-style
-dataset with non-integral indices/keys, a custom sampler must be provided.</p>
-</div></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L118-L147" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class UnmixDataset(torch.utils.data.Dataset):
- _repr_indent = 4
-
- def __init__(
- self,
- root: Union[Path, str],
- sample_rate: float,
- seq_duration: Optional[float] = None,
- source_augmentations: Optional[Callable] = None,
- ) -> None:
- self.root = Path(args.root).expanduser()
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.source_augmentations = source_augmentations
-
- def __getitem__(self, index: int) -> Any:
- raise NotImplementedError
-
- def __len__(self) -> int:
- raise NotImplementedError
-
- def __repr__(self) -> str:
- head = "Dataset " + self.__class__.__name__
- body = ["Number of datapoints: {}".format(self.__len__())]
- body += self.extra_repr().splitlines()
- lines = [head] + [" " * self._repr_indent + line for line in body]
- return "\n".join(lines)
-
- def extra_repr(self) -> str:
- return ""</code></pre>
-</details>
-<h3>Ancestors</h3>
-<ul class="hlist">
-<li>torch.utils.data.dataset.Dataset</li>
-<li>typing.Generic</li>
-</ul>
-<h3>Subclasses</h3>
-<ul class="hlist">
-<li><a title="openunmix.data.AlignedDataset" href="#openunmix.data.AlignedDataset">AlignedDataset</a></li>
-<li><a title="openunmix.data.FixedSourcesTrackFolderDataset" href="#openunmix.data.FixedSourcesTrackFolderDataset">FixedSourcesTrackFolderDataset</a></li>
-<li><a title="openunmix.data.MUSDBDataset" href="#openunmix.data.MUSDBDataset">MUSDBDataset</a></li>
-<li><a title="openunmix.data.SourceFolderDataset" href="#openunmix.data.SourceFolderDataset">SourceFolderDataset</a></li>
-<li><a title="openunmix.data.VariableSourcesTrackFolderDataset" href="#openunmix.data.VariableSourcesTrackFolderDataset">VariableSourcesTrackFolderDataset</a></li>
-</ul>
-<h3>Methods</h3>
-<dl>
-<dt id="openunmix.data.UnmixDataset.extra_repr"><code class="name flex">
-<span>def <span class="ident">extra_repr</span></span>(<span>self) ‑> str</span>
-</code></dt>
-<dd>
-<div class="desc"></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L146-L147" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def extra_repr(self) -> str:
- return ""</code></pre>
-</details>
-</dd>
-</dl>
-</dd>
-<dt id="openunmix.data.VariableSourcesTrackFolderDataset"><code class="flex name class">
-<span>class <span class="ident">VariableSourcesTrackFolderDataset</span></span>
-<span>(</span><span>root: str, split: str = 'train', target_file: str = 'vocals.wav', ext: str = '.wav', seq_duration: Union[float, NoneType] = None, random_chunks: bool = False, random_interferer_mix: bool = False, sample_rate: float = 44100.0, source_augmentations: Union[Callable, NoneType] = <function VariableSourcesTrackFolderDataset.<lambda>>, silence_missing_targets: bool = False)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>An abstract class representing a :class:<code>Dataset</code>.</p>
-<p>All datasets that represent a map from keys to data samples should subclass
-it. All subclasses should overwrite :meth:<code>__getitem__</code>, supporting fetching a
-data sample for a given key. Subclasses could also optionally overwrite
-:meth:<code>__len__</code>, which is expected to return the size of the dataset by many
-:class:<code>~torch.utils.data.Sampler</code> implementations and the default options
-of :class:<code>~torch.utils.data.DataLoader</code>.</p>
-<div class="admonition note">
-<p class="admonition-title">Note</p>
-<p>:class:<code>~torch.utils.data.DataLoader</code> by default constructs a index
-sampler that yields integral indices.
-To make it work with a map-style
-dataset with non-integral indices/keys, a custom sampler must be provided.</p>
-</div>
-<p>A dataset that assumes audio sources to be stored
-in track folder where each track has a <em>variable</em> number of sources.
-The users specifies the target file-name (<code>target_file</code>)
-and the extension of sources to used for mixing.
-A linear mix is performed on the fly by summing all sources in a
-track folder.</p>
-<p>Since the number of sources differ per track,
-while target is fixed, a random track mix
-augmentation cannot be used. Instead, a random track
-can be used to load the interfering sources.</p>
-<p>Also make sure, that you do not provide the mixture
-file among the sources!</p>
-<h1 id="example">Example</h1>
-<p>train/1/vocals.wav –> input target
-train/1/drums.wav –> input target
-|
-train/1/bass.wav –> input target
-–+–> input
-train/1/accordion.wav –> input target |
-train/1/marimba.wav –> input target
-/</p>
-<p>train/1/vocals.wav -----------------------> output</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L637-L766" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class VariableSourcesTrackFolderDataset(UnmixDataset):
- def __init__(
- self,
- root: str,
- split: str = "train",
- target_file: str = "vocals.wav",
- ext: str = ".wav",
- seq_duration: Optional[float] = None,
- random_chunks: bool = False,
- random_interferer_mix: bool = False,
- sample_rate: float = 44100.0,
- source_augmentations: Optional[Callable] = lambda audio: audio,
- silence_missing_targets: bool = False,
- ) -> None:
- """A dataset that assumes audio sources to be stored
- in track folder where each track has a _variable_ number of sources.
- The users specifies the target file-name (`target_file`)
- and the extension of sources to used for mixing.
- A linear mix is performed on the fly by summing all sources in a
- track folder.
-
- Since the number of sources differ per track,
- while target is fixed, a random track mix
- augmentation cannot be used. Instead, a random track
- can be used to load the interfering sources.
-
- Also make sure, that you do not provide the mixture
- file among the sources!
-
- Example
- =======
- train/1/vocals.wav --> input target \
- train/1/drums.wav --> input target |
- train/1/bass.wav --> input target --+--> input
- train/1/accordion.wav --> input target |
- train/1/marimba.wav --> input target /
-
- train/1/vocals.wav -----------------------> output
-
- """
- self.root = Path(root).expanduser()
- self.split = split
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.random_chunks = random_chunks
- self.random_interferer_mix = random_interferer_mix
- self.source_augmentations = source_augmentations
- self.target_file = target_file
- self.ext = ext
- self.silence_missing_targets = silence_missing_targets
- self.tracks = list(self.get_tracks())
-
- def __getitem__(self, index):
- # select the target based on the dataset index
- target_track_path = self.tracks[index]["path"]
- if self.random_chunks:
- target_min_duration = self.tracks[index]["min_duration"]
- target_start = random.uniform(0, target_min_duration - self.seq_duration)
- else:
- target_start = 0
-
- # optionally select a random interferer track
- if self.random_interferer_mix:
- random_idx = random.choice(range(len(self.tracks)))
- intfr_track_path = self.tracks[random_idx]["path"]
- if self.random_chunks:
- intfr_min_duration = self.tracks[random_idx]["min_duration"]
- intfr_start = random.uniform(0, intfr_min_duration - self.seq_duration)
- else:
- intfr_start = 0
- else:
- intfr_track_path = target_track_path
- intfr_start = target_start
-
- # get sources from interferer track
- sources = sorted(list(intfr_track_path.glob("*" + self.ext)))
-
- # load sources
- x = 0
- for source_path in sources:
- # skip target file and load it later
- if source_path == intfr_track_path / self.target_file:
- continue
-
- try:
- audio, _ = load_audio(source_path, start=intfr_start, dur=self.seq_duration)
- except RuntimeError:
- index = index - 1 if index > 0 else index + 1
- return self.__getitem__(index)
- x += self.source_augmentations(audio)
-
- # load the selected track target
- if Path(target_track_path / self.target_file).exists():
- y, _ = load_audio(
- target_track_path / self.target_file,
- start=target_start,
- dur=self.seq_duration,
- )
- y = self.source_augmentations(y)
- x += y
-
- # Use silence if target does not exist
- else:
- y = torch.zeros(audio.shape)
-
- return x, y
-
- def __len__(self):
- return len(self.tracks)
-
- def get_tracks(self):
- p = Path(self.root, self.split)
- for track_path in tqdm.tqdm(p.iterdir()):
- if track_path.is_dir():
- # check if target exists
- if Path(track_path, self.target_file).exists() or self.silence_missing_targets:
- sources = sorted(list(track_path.glob("*" + self.ext)))
- if not sources:
- # in case of empty folder
- print("empty track: ", track_path)
- continue
- if self.seq_duration is not None:
- # check sources
- infos = list(map(load_info, sources))
- # get minimum duration of source
- min_duration = min(i["duration"] for i in infos)
- if min_duration > self.seq_duration:
- yield ({"path": track_path, "min_duration": min_duration})
- else:
- yield ({"path": track_path, "min_duration": None})</code></pre>
-</details>
-<h3>Ancestors</h3>
-<ul class="hlist">
-<li><a title="openunmix.data.UnmixDataset" href="#openunmix.data.UnmixDataset">UnmixDataset</a></li>
-<li>torch.utils.data.dataset.Dataset</li>
-<li>typing.Generic</li>
-</ul>
-<h3>Methods</h3>
-<dl>
-<dt id="openunmix.data.VariableSourcesTrackFolderDataset.get_tracks"><code class="name flex">
-<span>def <span class="ident">get_tracks</span></span>(<span>self)</span>
-</code></dt>
-<dd>
-<div class="desc"></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/data.py#L747-L766" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def get_tracks(self):
- p = Path(self.root, self.split)
- for track_path in tqdm.tqdm(p.iterdir()):
- if track_path.is_dir():
- # check if target exists
- if Path(track_path, self.target_file).exists() or self.silence_missing_targets:
- sources = sorted(list(track_path.glob("*" + self.ext)))
- if not sources:
- # in case of empty folder
- print("empty track: ", track_path)
- continue
- if self.seq_duration is not None:
- # check sources
- infos = list(map(load_info, sources))
- # get minimum duration of source
- min_duration = min(i["duration"] for i in infos)
- if min_duration > self.seq_duration:
- yield ({"path": track_path, "min_duration": min_duration})
- else:
- yield ({"path": track_path, "min_duration": None})</code></pre>
-</details>
-</dd>
-</dl>
-</dd>
-</dl>
-</section>
-</article>
-<nav id="sidebar">
-<h1>Index</h1>
-<div class="toc">
-<ul></ul>
-</div>
-<ul id="index">
-<li><h3>Super-module</h3>
-<ul>
-<li><code><a title="openunmix" href="index.html">openunmix</a></code></li>
-</ul>
-</li>
-<li><h3><a href="#header-functions">Functions</a></h3>
-<ul class="">
-<li><code><a title="openunmix.data.aug_from_str" href="#openunmix.data.aug_from_str">aug_from_str</a></code></li>
-<li><code><a title="openunmix.data.load_audio" href="#openunmix.data.load_audio">load_audio</a></code></li>
-<li><code><a title="openunmix.data.load_datasets" href="#openunmix.data.load_datasets">load_datasets</a></code></li>
-<li><code><a title="openunmix.data.load_info" href="#openunmix.data.load_info">load_info</a></code></li>
-</ul>
-</li>
-<li><h3><a href="#header-classes">Classes</a></h3>
-<ul>
-<li>
-<h4><code><a title="openunmix.data.AlignedDataset" href="#openunmix.data.AlignedDataset">AlignedDataset</a></code></h4>
-</li>
-<li>
-<h4><code><a title="openunmix.data.Compose" href="#openunmix.data.Compose">Compose</a></code></h4>
-</li>
-<li>
-<h4><code><a title="openunmix.data.FixedSourcesTrackFolderDataset" href="#openunmix.data.FixedSourcesTrackFolderDataset">FixedSourcesTrackFolderDataset</a></code></h4>
-<ul class="">
-<li><code><a title="openunmix.data.FixedSourcesTrackFolderDataset.get_tracks" href="#openunmix.data.FixedSourcesTrackFolderDataset.get_tracks">get_tracks</a></code></li>
-</ul>
-</li>
-<li>
-<h4><code><a title="openunmix.data.MUSDBDataset" href="#openunmix.data.MUSDBDataset">MUSDBDataset</a></code></h4>
-</li>
-<li>
-<h4><code><a title="openunmix.data.SourceFolderDataset" href="#openunmix.data.SourceFolderDataset">SourceFolderDataset</a></code></h4>
-<ul class="">
-<li><code><a title="openunmix.data.SourceFolderDataset.get_tracks" href="#openunmix.data.SourceFolderDataset.get_tracks">get_tracks</a></code></li>
-</ul>
-</li>
-<li>
-<h4><code><a title="openunmix.data.UnmixDataset" href="#openunmix.data.UnmixDataset">UnmixDataset</a></code></h4>
-<ul class="">
-<li><code><a title="openunmix.data.UnmixDataset.extra_repr" href="#openunmix.data.UnmixDataset.extra_repr">extra_repr</a></code></li>
-</ul>
-</li>
-<li>
-<h4><code><a title="openunmix.data.VariableSourcesTrackFolderDataset" href="#openunmix.data.VariableSourcesTrackFolderDataset">VariableSourcesTrackFolderDataset</a></code></h4>
-<ul class="">
-<li><code><a title="openunmix.data.VariableSourcesTrackFolderDataset.get_tracks" href="#openunmix.data.VariableSourcesTrackFolderDataset.get_tracks">get_tracks</a></code></li>
-</ul>
-</li>
-</ul>
-</li>
-</ul>
-</nav>
-</main>
-<footer id="footer">
-<p>Generated by <a href="https://pdoc3.github.io/pdoc"><cite>pdoc</cite> 0.9.2</a>.</p>
-</footer>
-</body>
-</html>
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/evaluate.html b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/evaluate.html
deleted file mode 100644
index 98250793772e51922c64c0188bfb73c7a08de399..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/evaluate.html
+++ /dev/null
@@ -1,319 +0,0 @@
-<!doctype html>
-<html lang="en">
-<head>
-<meta charset="utf-8">
-<meta name="viewport" content="width=device-width, initial-scale=1, minimum-scale=1" />
-<meta name="generator" content="pdoc 0.9.2" />
-<title>openunmix.evaluate API documentation</title>
-<meta name="description" content="" />
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/sanitize.min.css" integrity="sha256-PK9q560IAAa6WVRRh76LtCaI8pjTJ2z11v0miyNNjrs=" crossorigin>
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/typography.min.css" integrity="sha256-7l/o7C8jubJiy74VsKTidCy1yBkRtiUGbVkYBylBqUg=" crossorigin>
-<link rel="stylesheet preload" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/styles/github.min.css" crossorigin>
-<style>:root{--highlight-color:#fe9}.flex{display:flex !important}body{line-height:1.5em}#content{padding:20px}#sidebar{padding:30px;overflow:hidden}#sidebar > *:last-child{margin-bottom:2cm}.http-server-breadcrumbs{font-size:130%;margin:0 0 15px 0}#footer{font-size:.75em;padding:5px 30px;border-top:1px solid #ddd;text-align:right}#footer p{margin:0 0 0 1em;display:inline-block}#footer p:last-child{margin-right:30px}h1,h2,h3,h4,h5{font-weight:300}h1{font-size:2.5em;line-height:1.1em}h2{font-size:1.75em;margin:1em 0 .50em 0}h3{font-size:1.4em;margin:25px 0 10px 0}h4{margin:0;font-size:105%}h1:target,h2:target,h3:target,h4:target,h5:target,h6:target{background:var(--highlight-color);padding:.2em 0}a{color:#058;text-decoration:none;transition:color .3s ease-in-out}a:hover{color:#e82}.title code{font-weight:bold}h2[id^="header-"]{margin-top:2em}.ident{color:#900}pre code{background:#f8f8f8;font-size:.8em;line-height:1.4em}code{background:#f2f2f1;padding:1px 4px;overflow-wrap:break-word}h1 code{background:transparent}pre{background:#f8f8f8;border:0;border-top:1px solid #ccc;border-bottom:1px solid #ccc;margin:1em 0;padding:1ex}#http-server-module-list{display:flex;flex-flow:column}#http-server-module-list div{display:flex}#http-server-module-list dt{min-width:10%}#http-server-module-list p{margin-top:0}.toc ul,#index{list-style-type:none;margin:0;padding:0}#index code{background:transparent}#index h3{border-bottom:1px solid #ddd}#index ul{padding:0}#index h4{margin-top:.6em;font-weight:bold}@media (min-width:200ex){#index .two-column{column-count:2}}@media (min-width:300ex){#index .two-column{column-count:3}}dl{margin-bottom:2em}dl dl:last-child{margin-bottom:4em}dd{margin:0 0 1em 3em}#header-classes + dl > dd{margin-bottom:3em}dd dd{margin-left:2em}dd p{margin:10px 0}.name{background:#eee;font-weight:bold;font-size:.85em;padding:5px 10px;display:inline-block;min-width:40%}.name:hover{background:#e0e0e0}dt:target .name{background:var(--highlight-color)}.name > span:first-child{white-space:nowrap}.name.class > span:nth-child(2){margin-left:.4em}.inherited{color:#999;border-left:5px solid #eee;padding-left:1em}.inheritance em{font-style:normal;font-weight:bold}.desc h2{font-weight:400;font-size:1.25em}.desc h3{font-size:1em}.desc dt code{background:inherit}.source summary,.git-link-div{color:#666;text-align:right;font-weight:400;font-size:.8em;text-transform:uppercase}.source summary > *{white-space:nowrap;cursor:pointer}.git-link{color:inherit;margin-left:1em}.source pre{max-height:500px;overflow:auto;margin:0}.source pre code{font-size:12px;overflow:visible}.hlist{list-style:none}.hlist li{display:inline}.hlist li:after{content:',\2002'}.hlist li:last-child:after{content:none}.hlist .hlist{display:inline;padding-left:1em}img{max-width:100%}td{padding:0 .5em}.admonition{padding:.1em .5em;margin-bottom:1em}.admonition-title{font-weight:bold}.admonition.note,.admonition.info,.admonition.important{background:#aef}.admonition.todo,.admonition.versionadded,.admonition.tip,.admonition.hint{background:#dfd}.admonition.warning,.admonition.versionchanged,.admonition.deprecated{background:#fd4}.admonition.error,.admonition.danger,.admonition.caution{background:lightpink}</style>
-<style media="screen and (min-width: 700px)">@media screen and (min-width:700px){#sidebar{width:30%;height:100vh;overflow:auto;position:sticky;top:0}#content{width:70%;max-width:100ch;padding:3em 4em;border-left:1px solid #ddd}pre code{font-size:1em}.item .name{font-size:1em}main{display:flex;flex-direction:row-reverse;justify-content:flex-end}.toc ul ul,#index ul{padding-left:1.5em}.toc > ul > li{margin-top:.5em}}</style>
-<style media="print">@media print{#sidebar h1{page-break-before:always}.source{display:none}}@media print{*{background:transparent !important;color:#000 !important;box-shadow:none !important;text-shadow:none !important}a[href]:after{content:" (" attr(href) ")";font-size:90%}a[href][title]:after{content:none}abbr[title]:after{content:" (" attr(title) ")"}.ir a:after,a[href^="javascript:"]:after,a[href^="#"]:after{content:""}pre,blockquote{border:1px solid #999;page-break-inside:avoid}thead{display:table-header-group}tr,img{page-break-inside:avoid}img{max-width:100% !important}@page{margin:0.5cm}p,h2,h3{orphans:3;widows:3}h1,h2,h3,h4,h5,h6{page-break-after:avoid}}</style>
-<script async src="https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.7/latest.js?config=TeX-AMS_CHTML" integrity="sha256-kZafAc6mZvK3W3v1pHOcUix30OHQN6pU/NO2oFkqZVw=" crossorigin></script>
-<script defer src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/highlight.min.js" integrity="sha256-Uv3H6lx7dJmRfRvH8TH6kJD1TSK1aFcwgx+mdg3epi8=" crossorigin></script>
-<script>window.addEventListener('DOMContentLoaded', () => hljs.initHighlighting())</script>
-</head>
-<body>
-<main>
-<article id="content">
-<header>
-<h1 class="title">Module <code>openunmix.evaluate</code></h1>
-</header>
-<section id="section-intro">
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/evaluate.py#L0-L196" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">import argparse
-import functools
-import json
-import multiprocessing
-from typing import Optional, Union
-
-import musdb
-import museval
-import torch
-import tqdm
-
-from openunmix import utils
-
-
-def separate_and_evaluate(
- track: musdb.MultiTrack,
- targets: list,
- model_str_or_path: str,
- niter: int,
- output_dir: str,
- eval_dir: str,
- residual: bool,
- mus,
- aggregate_dict: dict = None,
- device: Union[str, torch.device] = "cpu",
- wiener_win_len: Optional[int] = None,
- filterbank="torch",
-) -> str:
-
- separator = utils.load_separator(
- model_str_or_path=model_str_or_path,
- targets=targets,
- niter=niter,
- residual=residual,
- wiener_win_len=wiener_win_len,
- device=device,
- pretrained=True,
- filterbank=filterbank,
- )
-
- separator.freeze()
- separator.to(device)
-
- audio = torch.as_tensor(track.audio, dtype=torch.float32, device=device)
- audio = utils.preprocess(audio, track.rate, separator.sample_rate)
-
- estimates = separator(audio)
- estimates = separator.to_dict(estimates, aggregate_dict=aggregate_dict)
-
- for key in estimates:
- estimates[key] = estimates[key][0].cpu().detach().numpy().T
- if output_dir:
- mus.save_estimates(estimates, track, output_dir)
-
- scores = museval.eval_mus_track(track, estimates, output_dir=eval_dir)
- return scores
-
-
-if __name__ == "__main__":
- # Training settings
- parser = argparse.ArgumentParser(description="MUSDB18 Evaluation", add_help=False)
-
- parser.add_argument(
- "--targets",
- nargs="+",
- default=["vocals", "drums", "bass", "other"],
- type=str,
- help="provide targets to be processed. \
- If none, all available targets will be computed",
- )
-
- parser.add_argument(
- "--model",
- default="umxhq",
- type=str,
- help="path to mode base directory of pretrained models",
- )
-
- parser.add_argument(
- "--outdir",
- type=str,
- help="Results path where audio evaluation results are stored",
- )
-
- parser.add_argument("--evaldir", type=str, help="Results path for museval estimates")
-
- parser.add_argument("--root", type=str, help="Path to MUSDB18")
-
- parser.add_argument("--subset", type=str, default="test", help="MUSDB subset (`train`/`test`)")
-
- parser.add_argument("--cores", type=int, default=1)
-
- parser.add_argument(
- "--no-cuda", action="store_true", default=False, help="disables CUDA inference"
- )
-
- parser.add_argument(
- "--is-wav",
- action="store_true",
- default=False,
- help="flags wav version of the dataset",
- )
-
- parser.add_argument(
- "--niter",
- type=int,
- default=1,
- help="number of iterations for refining results.",
- )
-
- parser.add_argument(
- "--wiener-win-len",
- type=int,
- default=300,
- help="Number of frames on which to apply filtering independently",
- )
-
- parser.add_argument(
- "--residual",
- type=str,
- default=None,
- help="if provided, build a source with given name"
- "for the mix minus all estimated targets",
- )
-
- parser.add_argument(
- "--aggregate",
- type=str,
- default=None,
- help="if provided, must be a string containing a valid expression for "
- "a dictionary, with keys as output target names, and values "
- "a list of targets that are used to build it. For instance: "
- '\'{"vocals":["vocals"], "accompaniment":["drums",'
- '"bass","other"]}\'',
- )
-
- args = parser.parse_args()
-
- use_cuda = not args.no_cuda and torch.cuda.is_available()
- device = torch.device("cuda" if use_cuda else "cpu")
-
- mus = musdb.DB(
- root=args.root,
- download=args.root is None,
- subsets=args.subset,
- is_wav=args.is_wav,
- )
- aggregate_dict = None if args.aggregate is None else json.loads(args.aggregate)
-
- if args.cores > 1:
- pool = multiprocessing.Pool(args.cores)
- results = museval.EvalStore()
- scores_list = list(
- pool.imap_unordered(
- func=functools.partial(
- separate_and_evaluate,
- targets=args.targets,
- model_str_or_path=args.model,
- niter=args.niter,
- residual=args.residual,
- mus=mus,
- aggregate_dict=aggregate_dict,
- output_dir=args.outdir,
- eval_dir=args.evaldir,
- device=device,
- ),
- iterable=mus.tracks,
- chunksize=1,
- )
- )
- pool.close()
- pool.join()
- for scores in scores_list:
- results.add_track(scores)
-
- else:
- results = museval.EvalStore()
- for track in tqdm.tqdm(mus.tracks):
- scores = separate_and_evaluate(
- track,
- targets=args.targets,
- model_str_or_path=args.model,
- niter=args.niter,
- residual=args.residual,
- mus=mus,
- aggregate_dict=aggregate_dict,
- output_dir=args.outdir,
- eval_dir=args.evaldir,
- device=device,
- )
- print(track, "\n", scores)
- results.add_track(scores)
-
- print(results)
- method = museval.MethodStore()
- method.add_evalstore(results, args.model)
- method.save(args.model + ".pandas")</code></pre>
-</details>
-</section>
-<section>
-</section>
-<section>
-</section>
-<section>
-<h2 class="section-title" id="header-functions">Functions</h2>
-<dl>
-<dt id="openunmix.evaluate.separate_and_evaluate"><code class="name flex">
-<span>def <span class="ident">separate_and_evaluate</span></span>(<span>track: musdb.audio_classes.MultiTrack, targets: list, model_str_or_path: str, niter: int, output_dir: str, eval_dir: str, residual: bool, mus, aggregate_dict: dict = None, device: Union[str, torch.device] = 'cpu', wiener_win_len: Union[int, NoneType] = None, filterbank='torch') ‑> str</span>
-</code></dt>
-<dd>
-<div class="desc"></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/evaluate.py#L15-L56" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def separate_and_evaluate(
- track: musdb.MultiTrack,
- targets: list,
- model_str_or_path: str,
- niter: int,
- output_dir: str,
- eval_dir: str,
- residual: bool,
- mus,
- aggregate_dict: dict = None,
- device: Union[str, torch.device] = "cpu",
- wiener_win_len: Optional[int] = None,
- filterbank="torch",
-) -> str:
-
- separator = utils.load_separator(
- model_str_or_path=model_str_or_path,
- targets=targets,
- niter=niter,
- residual=residual,
- wiener_win_len=wiener_win_len,
- device=device,
- pretrained=True,
- filterbank=filterbank,
- )
-
- separator.freeze()
- separator.to(device)
-
- audio = torch.as_tensor(track.audio, dtype=torch.float32, device=device)
- audio = utils.preprocess(audio, track.rate, separator.sample_rate)
-
- estimates = separator(audio)
- estimates = separator.to_dict(estimates, aggregate_dict=aggregate_dict)
-
- for key in estimates:
- estimates[key] = estimates[key][0].cpu().detach().numpy().T
- if output_dir:
- mus.save_estimates(estimates, track, output_dir)
-
- scores = museval.eval_mus_track(track, estimates, output_dir=eval_dir)
- return scores</code></pre>
-</details>
-</dd>
-</dl>
-</section>
-<section>
-</section>
-</article>
-<nav id="sidebar">
-<h1>Index</h1>
-<div class="toc">
-<ul></ul>
-</div>
-<ul id="index">
-<li><h3>Super-module</h3>
-<ul>
-<li><code><a title="openunmix" href="index.html">openunmix</a></code></li>
-</ul>
-</li>
-<li><h3><a href="#header-functions">Functions</a></h3>
-<ul class="">
-<li><code><a title="openunmix.evaluate.separate_and_evaluate" href="#openunmix.evaluate.separate_and_evaluate">separate_and_evaluate</a></code></li>
-</ul>
-</li>
-</ul>
-</nav>
-</main>
-<footer id="footer">
-<p>Generated by <a href="https://pdoc3.github.io/pdoc"><cite>pdoc</cite> 0.9.2</a>.</p>
-</footer>
-</body>
-</html>
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/extensions.md b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/extensions.md
deleted file mode 100644
index c0bf2feaf631017e830489da998e5233c600bc9b..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/extensions.md
+++ /dev/null
@@ -1,162 +0,0 @@
-# Extending Open-Unmix
-
-
-One of the key aspects of _Open-Unmix_ is that it was made to be easily extensible and thus is a good starting point for new research on music source separation. In fact, the open-unmix training code is based on the [pytorch MNIST example](https://github.com/pytorch/examples/blob/master/mnist/main.py). In this document we provide a short overview of ways to extend open-unmix.
-
-## Code Structure
-
-* `data.py` includes several torch datasets that can all be used to train _open-unmix_.
-* `train.py` includes all code that is necessary to start a training.
-* `model.py` includes the open-unmix torch modules.
-* `test.py` includes code to predict/unmix from audio files.
-* `eval.py` includes all code to run the objective evaluation using museval on the MUSDB18 dataset.
-* `utils.py` includes additional tools like audio loading and metadata loading.
-
-## Provide a custom dataset
-
-Users of open-unmix that have their own datasets and could not fit one of our predefined datasets might want to implement or use their own `torch.utils.data.Dataset` to be used for the training. Such a modification is very simple since our dataset.
-
-### Template Dataset
-
-In case you want to create your own dataset we provide a template for the open-unmix API. You can use our efficient torchaudio or libsndfile based `load_audio` audio loaders or just use your own files. Since currently (pytorch<=1.1) is using index based datasets (instead of iterable based datasets), the best way to load audio is to assign the index to one audio track. However, there are possible applications where the index is ignored and the `__len__()` method just returns arbitrary number of samples.
-
-```python
-from utils import load_audio, load_info
-class TemplateDataset(UnmixDataset):
- """A template dataset class for you to implement custom datasets."""
-
- def __init__(self, root, split='train', sample_rate=44100, seq_dur=None):
- """Initialize the dataset
- """
- self.root = root
- self.tracks = get_tracks(root, split)
-
- def __getitem__(self, index):
- """Returns a time domain audio example
- of shape=(channel, sample)
- """
- path = self.tracks[index]
- x = load_audio(path)
- y = load_audio(path)
- return x, y
-
- def __len__(self):
- """Return the number of audio samples"""
- return len(self.tracks)
-```
-
-## Provide a custom model
-
-We think that recurrent models provide the best trade-off between good results, fast training and flexibility of training due to its ability to learn from arbitrary durations of audio and different audio representations. If you want to try different models you can easily build upon our model template below:
-
-### Template Spectrogram Model
-
-```python
-from model import Spectrogram, STFT
-class Model(nn.Module):
- def __init__(
- self,
- n_fft=4096,
- n_hop=1024,
- nb_channels=2,
- input_is_spectrogram=False,
- sample_rate=44100.0,
- ):
- """
- Input: (batch, channel, sample)
- or (frame, batch, channels, frequency)
- Output: (frame, batch, channels, frequency)
- """
-
- super(OpenUnmix, self).__init__()
-
- def forward(self, mix):
- # transform to spectrogram on the fly
- X = self.transform(mix)
- nb_frames, nb_samples, nb_channels, nb_bins = x.data.shape
-
- # transform X to estimate
- # ....
-
- return X
-```
-
-## Jointly train targets
-
-We designed _open-unmix_ so that the training of multiple targets is handled in separate models. We think that this has several benefits such as:
-
-* single source models can leverage unbalanced data where for each source different size of training data is available/
-* training can easily distributed by training multiple models on different nodes in parallel.
-* at test time the selection of different models can be adjusted for specific applications.
-
-However, we acknowledge the fact that there might be reasons to train a model jointly for all sources to improve the separation performance. These changes can easily be made in _open-unmix_ with the following modifications based the way how pytorch handles single-input-multiple-outputs models.
-
-### 1. Extend `data.py`
-
-The dataset should be able to yield a list of tensors (one for each target): E.g. the `musdb` dataset can be extended with:
-
-```python
-y = [stems[ind] for ind, _ in enumerate(self.targets)]
-```
-
-### 2. Extend `model.py`
-
-The _open-unmix_ model can be left unchanged but instead a "supermodel" can be added that joins the forward paths of all targets:
-
-```python
-class OpenUnmixJoint(nn.Module):
- def __init__(
- self,
- targets,
- *args, **kwargs
- ):
- super(OpenUnmixJoint, self).__init__()
- self.models = nn.ModuleList(
- [OpenUnmix(*args, **kwargs) for target in targets]
- )
-
- def forward(self, x):
- return [model(x) for model in self.models]
-```
-
-### 3. Extend `train.py`
-
-The training should be updated so that the total loss is an aggregation of the individual target losses. For the mean squared error, the following modifications should be sufficient:
-
-```python
-criteria = [torch.nn.MSELoss() for t in args.targets]
-# ...
-for x, y in tqdm.tqdm(train_sampler, disable=args.quiet):
- x = x.to(device)
- y = [i.to(device) for i in y]
- optimizer.zero_grad()
- Y_hats = unmix(x)
- loss = 0
- for Y_hat, target, criterion in zip(Y_hats, y, criteria):
- loss = loss + criterion(Y_hat, unmix.models[0].transform(target))
-```
-
-## End-to-End time-domain models
-
-If you want to evaluate models that work in the time domain such as WaveNet or WaveRNN, the training code would have to modified. Instead of spectrogram output `Y` the output is simply a time domain signal `y` that can directly be compared with `x`. E.g. going from:
-
-```python
-Y_hat = unmix(x)
-Y = unmix.transform(y)
-loss = criterion(Y_hat, Y)
-```
-
-to:
-
-```python
-y_hat = unmix(x)
-loss = criterion(y_hat, y)
-```
-
-Inference, in that case, would then have to drop the spectral wiener filter and instead directly save the time domain signal (and maybe its residual):
-
-```python
-est = unmix(audio_torch).cpu().detach().numpy()
-estimates[target] = est[0].T
-estimates['residual'] = audio - est[0].T
-```
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/faq.md b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/faq.md
deleted file mode 100644
index 9cd107a3cdca64eb7af215c91e4abeb8cd1de8ce..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/faq.md
+++ /dev/null
@@ -1,58 +0,0 @@
-# Frequently Asked Questions
-
-## Separating tracks crashes because it used too much memory
-
-First, separating an audio track into four separation models `vocals`, `drums`, `bass` and `other` is requires a significant amount of RAM to load all four separate models.
-Furthermore, another computationally important step in the separation is the post-processing, controlled by the parameter `niter`.
-For faster and less memory intensive inference (at the expense of separation quality) it is advised to use `niter 0`.
-Another way to improve performance is to apply separation on smaller excerpts using the `start` and `duration`, arguments. We suggest to only perform separation of ~30s stereo excerpts on machines with less 8GB of memory.
-
-## Why is the training so slow?
-
-In the default configuration using the stems dataset, yielding a single batch from the dataset is very slow. This is a known issue of decoding mp4 stems since native decoders for pytorch or numpy are not available.
-
-There are two ways to speed up the training:
-
-### 1. Increase the number of workers
-
-The default configuration does not use multiprocessing to yield the batches. You can increase the number of workers using the `--nb-workers k` configuration. E.g. `k=8` workers batch loading can get down to 1 batch per second.
-
-### 2. Use WAV instead of MP4
-
-Convert the MUSDB18 dataset to wav using the builtin `musdb` cli tool
-
-```
-musdbconvert path/to/musdb-stems-root path/to/new/musdb-wav-root
-```
-
-or alternatively use the [MUSDB18-HQ](https://zenodo.org/record/3338373) dataset that is already stored and distributed as WAV files. Note that __if you want to compare to SiSEC 2018 participants, you should use the standard (Stems) MUSDB18 dataset and decode it to WAV, instead.__
-
-Training on wav files can be launched using the `--is-wav` flag:
-
-```
-python scripts/train.py --root path/to/musdb18-wav --is-wav --target vocals
-```
-
-This will get you down to 0.6s per batch on 4 workers, likely hitting the bandwidth of standard hard-drives. It can be further improved using an SSD, which brings it down to 0.4s per batch on a GTX1080Ti which this leads to 95% GPU utilization. thus data-loading will not be the bottleneck anymore.
-
-## Can I use the pre-trained models without torchhub?
-
-for some reason the torchub automatic download might not work and you want to download the files offline and use them. For that you can download [umx](https://zenodo.org/record/3340804) or [umxhq](https://zenodo.org/record/3267291) from Zenodo and create a local folder of your choice (e.g. `umx-weights`) where the model is stored in a flat file hierarchy:
-
-```
-umx-weights/vocals-*.pth
-umx-weights/drums-*.pth
-umx-weights/bass-*.pth
-umx-weights/other-*.pth
-umx-weights/vocals.json
-umx-weights/drums.json
-umx-weights/bass.json
-umx-weights/other.json
-umx-weights/separator.json
-```
-
-Test and eval can then be started using:
-
-```bash
-umx --model umx-weights --input test.wav
-```
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/filtering.html b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/filtering.html
deleted file mode 100644
index 54a15251cbd56a6ba7cd31932c99a13a59384e9a..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/filtering.html
+++ /dev/null
@@ -1,1142 +0,0 @@
-<!doctype html>
-<html lang="en">
-<head>
-<meta charset="utf-8">
-<meta name="viewport" content="width=device-width, initial-scale=1, minimum-scale=1" />
-<meta name="generator" content="pdoc 0.9.2" />
-<title>openunmix.filtering API documentation</title>
-<meta name="description" content="" />
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/sanitize.min.css" integrity="sha256-PK9q560IAAa6WVRRh76LtCaI8pjTJ2z11v0miyNNjrs=" crossorigin>
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/typography.min.css" integrity="sha256-7l/o7C8jubJiy74VsKTidCy1yBkRtiUGbVkYBylBqUg=" crossorigin>
-<link rel="stylesheet preload" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/styles/github.min.css" crossorigin>
-<style>:root{--highlight-color:#fe9}.flex{display:flex !important}body{line-height:1.5em}#content{padding:20px}#sidebar{padding:30px;overflow:hidden}#sidebar > *:last-child{margin-bottom:2cm}.http-server-breadcrumbs{font-size:130%;margin:0 0 15px 0}#footer{font-size:.75em;padding:5px 30px;border-top:1px solid #ddd;text-align:right}#footer p{margin:0 0 0 1em;display:inline-block}#footer p:last-child{margin-right:30px}h1,h2,h3,h4,h5{font-weight:300}h1{font-size:2.5em;line-height:1.1em}h2{font-size:1.75em;margin:1em 0 .50em 0}h3{font-size:1.4em;margin:25px 0 10px 0}h4{margin:0;font-size:105%}h1:target,h2:target,h3:target,h4:target,h5:target,h6:target{background:var(--highlight-color);padding:.2em 0}a{color:#058;text-decoration:none;transition:color .3s ease-in-out}a:hover{color:#e82}.title code{font-weight:bold}h2[id^="header-"]{margin-top:2em}.ident{color:#900}pre code{background:#f8f8f8;font-size:.8em;line-height:1.4em}code{background:#f2f2f1;padding:1px 4px;overflow-wrap:break-word}h1 code{background:transparent}pre{background:#f8f8f8;border:0;border-top:1px solid #ccc;border-bottom:1px solid #ccc;margin:1em 0;padding:1ex}#http-server-module-list{display:flex;flex-flow:column}#http-server-module-list div{display:flex}#http-server-module-list dt{min-width:10%}#http-server-module-list p{margin-top:0}.toc ul,#index{list-style-type:none;margin:0;padding:0}#index code{background:transparent}#index h3{border-bottom:1px solid #ddd}#index ul{padding:0}#index h4{margin-top:.6em;font-weight:bold}@media (min-width:200ex){#index .two-column{column-count:2}}@media (min-width:300ex){#index .two-column{column-count:3}}dl{margin-bottom:2em}dl dl:last-child{margin-bottom:4em}dd{margin:0 0 1em 3em}#header-classes + dl > dd{margin-bottom:3em}dd dd{margin-left:2em}dd p{margin:10px 0}.name{background:#eee;font-weight:bold;font-size:.85em;padding:5px 10px;display:inline-block;min-width:40%}.name:hover{background:#e0e0e0}dt:target .name{background:var(--highlight-color)}.name > span:first-child{white-space:nowrap}.name.class > span:nth-child(2){margin-left:.4em}.inherited{color:#999;border-left:5px solid #eee;padding-left:1em}.inheritance em{font-style:normal;font-weight:bold}.desc h2{font-weight:400;font-size:1.25em}.desc h3{font-size:1em}.desc dt code{background:inherit}.source summary,.git-link-div{color:#666;text-align:right;font-weight:400;font-size:.8em;text-transform:uppercase}.source summary > *{white-space:nowrap;cursor:pointer}.git-link{color:inherit;margin-left:1em}.source pre{max-height:500px;overflow:auto;margin:0}.source pre code{font-size:12px;overflow:visible}.hlist{list-style:none}.hlist li{display:inline}.hlist li:after{content:',\2002'}.hlist li:last-child:after{content:none}.hlist .hlist{display:inline;padding-left:1em}img{max-width:100%}td{padding:0 .5em}.admonition{padding:.1em .5em;margin-bottom:1em}.admonition-title{font-weight:bold}.admonition.note,.admonition.info,.admonition.important{background:#aef}.admonition.todo,.admonition.versionadded,.admonition.tip,.admonition.hint{background:#dfd}.admonition.warning,.admonition.versionchanged,.admonition.deprecated{background:#fd4}.admonition.error,.admonition.danger,.admonition.caution{background:lightpink}</style>
-<style media="screen and (min-width: 700px)">@media screen and (min-width:700px){#sidebar{width:30%;height:100vh;overflow:auto;position:sticky;top:0}#content{width:70%;max-width:100ch;padding:3em 4em;border-left:1px solid #ddd}pre code{font-size:1em}.item .name{font-size:1em}main{display:flex;flex-direction:row-reverse;justify-content:flex-end}.toc ul ul,#index ul{padding-left:1.5em}.toc > ul > li{margin-top:.5em}}</style>
-<style media="print">@media print{#sidebar h1{page-break-before:always}.source{display:none}}@media print{*{background:transparent !important;color:#000 !important;box-shadow:none !important;text-shadow:none !important}a[href]:after{content:" (" attr(href) ")";font-size:90%}a[href][title]:after{content:none}abbr[title]:after{content:" (" attr(title) ")"}.ir a:after,a[href^="javascript:"]:after,a[href^="#"]:after{content:""}pre,blockquote{border:1px solid #999;page-break-inside:avoid}thead{display:table-header-group}tr,img{page-break-inside:avoid}img{max-width:100% !important}@page{margin:0.5cm}p,h2,h3{orphans:3;widows:3}h1,h2,h3,h4,h5,h6{page-break-after:avoid}}</style>
-<script async src="https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.7/latest.js?config=TeX-AMS_CHTML" integrity="sha256-kZafAc6mZvK3W3v1pHOcUix30OHQN6pU/NO2oFkqZVw=" crossorigin></script>
-<script defer src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/highlight.min.js" integrity="sha256-Uv3H6lx7dJmRfRvH8TH6kJD1TSK1aFcwgx+mdg3epi8=" crossorigin></script>
-<script>window.addEventListener('DOMContentLoaded', () => hljs.initHighlighting())</script>
-</head>
-<body>
-<main>
-<article id="content">
-<header>
-<h1 class="title">Module <code>openunmix.filtering</code></h1>
-</header>
-<section id="section-intro">
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/filtering.py#L0-L503" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">from typing import Optional
-
-import torch
-import torch.nn as nn
-from torch import Tensor
-from torch.utils.data import DataLoader
-
-
-def atan2(y, x):
- r"""Element-wise arctangent function of y/x.
- Returns a new tensor with signed angles in radians.
- It is an alternative implementation of torch.atan2
-
- Args:
- y (Tensor): First input tensor
- x (Tensor): Second input tensor [shape=y.shape]
-
- Returns:
- Tensor: [shape=y.shape].
- """
- pi = 2 * torch.asin(torch.tensor(1.0))
- x += ((x == 0) & (y == 0)) * 1.0
- out = torch.atan(y / x)
- out += ((y >= 0) & (x < 0)) * pi
- out -= ((y < 0) & (x < 0)) * pi
- out *= 1 - ((y > 0) & (x == 0)) * 1.0
- out += ((y > 0) & (x == 0)) * (pi / 2)
- out *= 1 - ((y < 0) & (x == 0)) * 1.0
- out += ((y < 0) & (x == 0)) * (-pi / 2)
- return out
-
-
-# Define basic complex operations on torch.Tensor objects whose last dimension
-# consists in the concatenation of the real and imaginary parts.
-
-
-def _norm(x: torch.Tensor) -> torch.Tensor:
- r"""Computes the norm value of a torch Tensor, assuming that it
- comes as real and imaginary part in its last dimension.
-
- Args:
- x (Tensor): Input Tensor of shape [shape=(..., 2)]
-
- Returns:
- Tensor: shape as x excluding the last dimension.
- """
- return torch.abs(x[..., 0]) ** 2 + torch.abs(x[..., 1]) ** 2
-
-
-def _mul_add(a: torch.Tensor, b: torch.Tensor, out: Optional[torch.Tensor] = None) -> torch.Tensor:
- """Element-wise multiplication of two complex Tensors described
- through their real and imaginary parts.
- The result is added to the `out` tensor"""
-
- # check `out` and allocate it if needed
- target_shape = torch.Size([max(sa, sb) for (sa, sb) in zip(a.shape, b.shape)])
- if out is None or out.shape != target_shape:
- out = torch.zeros(target_shape, dtype=a.dtype, device=a.device)
- if out is a:
- real_a = a[..., 0]
- out[..., 0] = out[..., 0] + (real_a * b[..., 0] - a[..., 1] * b[..., 1])
- out[..., 1] = out[..., 1] + (real_a * b[..., 1] + a[..., 1] * b[..., 0])
- else:
- out[..., 0] = out[..., 0] + (a[..., 0] * b[..., 0] - a[..., 1] * b[..., 1])
- out[..., 1] = out[..., 1] + (a[..., 0] * b[..., 1] + a[..., 1] * b[..., 0])
- return out
-
-
-def _mul(a: torch.Tensor, b: torch.Tensor, out: Optional[torch.Tensor] = None) -> torch.Tensor:
- """Element-wise multiplication of two complex Tensors described
- through their real and imaginary parts
- can work in place in case out is a only"""
- target_shape = torch.Size([max(sa, sb) for (sa, sb) in zip(a.shape, b.shape)])
- if out is None or out.shape != target_shape:
- out = torch.zeros(target_shape, dtype=a.dtype, device=a.device)
- if out is a:
- real_a = a[..., 0]
- out[..., 0] = real_a * b[..., 0] - a[..., 1] * b[..., 1]
- out[..., 1] = real_a * b[..., 1] + a[..., 1] * b[..., 0]
- else:
- out[..., 0] = a[..., 0] * b[..., 0] - a[..., 1] * b[..., 1]
- out[..., 1] = a[..., 0] * b[..., 1] + a[..., 1] * b[..., 0]
- return out
-
-
-def _inv(z: torch.Tensor, out: Optional[torch.Tensor] = None) -> torch.Tensor:
- """Element-wise multiplicative inverse of a Tensor with complex
- entries described through their real and imaginary parts.
- can work in place in case out is z"""
- ez = _norm(z)
- if out is None or out.shape != z.shape:
- out = torch.zeros_like(z)
- out[..., 0] = z[..., 0] / ez
- out[..., 1] = -z[..., 1] / ez
- return out
-
-
-def _conj(z, out: Optional[torch.Tensor] = None) -> torch.Tensor:
- """Element-wise complex conjugate of a Tensor with complex entries
- described through their real and imaginary parts.
- can work in place in case out is z"""
- if out is None or out.shape != z.shape:
- out = torch.zeros_like(z)
- out[..., 0] = z[..., 0]
- out[..., 1] = -z[..., 1]
- return out
-
-
-def _invert(M: torch.Tensor, out: Optional[torch.Tensor] = None) -> torch.Tensor:
- """
- Invert 1x1 or 2x2 matrices
-
- Will generate errors if the matrices are singular: user must handle this
- through his own regularization schemes.
-
- Args:
- M (Tensor): [shape=(..., nb_channels, nb_channels, 2)]
- matrices to invert: must be square along dimensions -3 and -2
-
- Returns:
- invM (Tensor): [shape=M.shape]
- inverses of M
- """
- nb_channels = M.shape[-2]
-
- if out is None or out.shape != M.shape:
- out = torch.empty_like(M)
-
- if nb_channels == 1:
- # scalar case
- out = _inv(M, out)
- elif nb_channels == 2:
- # two channels case: analytical expression
-
- # first compute the determinent
- det = _mul(M[..., 0, 0, :], M[..., 1, 1, :])
- det = det - _mul(M[..., 0, 1, :], M[..., 1, 0, :])
- # invert it
- invDet = _inv(det)
-
- # then fill out the matrix with the inverse
- out[..., 0, 0, :] = _mul(invDet, M[..., 1, 1, :], out[..., 0, 0, :])
- out[..., 1, 0, :] = _mul(-invDet, M[..., 1, 0, :], out[..., 1, 0, :])
- out[..., 0, 1, :] = _mul(-invDet, M[..., 0, 1, :], out[..., 0, 1, :])
- out[..., 1, 1, :] = _mul(invDet, M[..., 0, 0, :], out[..., 1, 1, :])
- else:
- raise Exception("Only 2 channels are supported for the torch version.")
- return out
-
-
-# Now define the signal-processing low-level functions used by the Separator
-
-
-def expectation_maximization(
- y: torch.Tensor,
- x: torch.Tensor,
- iterations: int = 2,
- eps: float = 1e-10,
- batch_size: int = 200,
-):
- r"""Expectation maximization algorithm, for refining source separation
- estimates.
-
- This algorithm allows to make source separation results better by
- enforcing multichannel consistency for the estimates. This usually means
- a better perceptual quality in terms of spatial artifacts.
-
- The implementation follows the details presented in [1]_, taking
- inspiration from the original EM algorithm proposed in [2]_ and its
- weighted refinement proposed in [3]_, [4]_.
- It works by iteratively:
-
- * Re-estimate source parameters (power spectral densities and spatial
- covariance matrices) through :func:`get_local_gaussian_model`.
-
- * Separate again the mixture with the new parameters by first computing
- the new modelled mixture covariance matrices with :func:`get_mix_model`,
- prepare the Wiener filters through :func:`wiener_gain` and apply them
- with :func:`apply_filter``.
-
- References
- ----------
- .. [1] S. Uhlich and M. Porcu and F. Giron and M. Enenkl and T. Kemp and
- N. Takahashi and Y. Mitsufuji, "Improving music source separation based
- on deep neural networks through data augmentation and network
- blending." 2017 IEEE International Conference on Acoustics, Speech
- and Signal Processing (ICASSP). IEEE, 2017.
-
- .. [2] N.Q. Duong and E. Vincent and R.Gribonval. "Under-determined
- reverberant audio source separation using a full-rank spatial
- covariance model." IEEE Transactions on Audio, Speech, and Language
- Processing 18.7 (2010): 1830-1840.
-
- .. [3] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel audio source
- separation with deep neural networks." IEEE/ACM Transactions on Audio,
- Speech, and Language Processing 24.9 (2016): 1652-1664.
-
- .. [4] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel music
- separation with deep neural networks." 2016 24th European Signal
- Processing Conference (EUSIPCO). IEEE, 2016.
-
- .. [5] A. Liutkus and R. Badeau and G. Richard "Kernel additive models for
- source separation." IEEE Transactions on Signal Processing
- 62.16 (2014): 4298-4310.
-
- Args:
- y (Tensor): [shape=(nb_frames, nb_bins, nb_channels, 2, nb_sources)]
- initial estimates for the sources
- x (Tensor): [shape=(nb_frames, nb_bins, nb_channels, 2)]
- complex STFT of the mixture signal
- iterations (int): [scalar]
- number of iterations for the EM algorithm.
- eps (float or None): [scalar]
- The epsilon value to use for regularization and filters.
-
- Returns:
- y (Tensor): [shape=(nb_frames, nb_bins, nb_channels, 2, nb_sources)]
- estimated sources after iterations
- v (Tensor): [shape=(nb_frames, nb_bins, nb_sources)]
- estimated power spectral densities
- R (Tensor): [shape=(nb_bins, nb_channels, nb_channels, 2, nb_sources)]
- estimated spatial covariance matrices
-
- Notes:
- * You need an initial estimate for the sources to apply this
- algorithm. This is precisely what the :func:`wiener` function does.
- * This algorithm *is not* an implementation of the "exact" EM
- proposed in [1]_. In particular, it does compute the posterior
- covariance matrices the same (exact) way. Instead, it uses the
- simplified approximate scheme initially proposed in [5]_ and further
- refined in [3]_, [4]_, that boils down to just take the empirical
- covariance of the recent source estimates, followed by a weighted
- average for the update of the spatial covariance matrix. It has been
- empirically demonstrated that this simplified algorithm is more
- robust for music separation.
-
- Warning:
- It is *very* important to make sure `x.dtype` is `torch.float64`
- if you want double precision, because this function will **not**
- do such conversion for you from `torch.complex32`, in case you want the
- smaller RAM usage on purpose.
-
- It is usually always better in terms of quality to have double
- precision, by e.g. calling :func:`expectation_maximization`
- with ``x.to(torch.float64)``.
- """
- # dimensions
- (nb_frames, nb_bins, nb_channels) = x.shape[:-1]
- nb_sources = y.shape[-1]
-
- regularization = torch.cat(
- (
- torch.eye(nb_channels, dtype=x.dtype, device=x.device)[..., None],
- torch.zeros((nb_channels, nb_channels, 1), dtype=x.dtype, device=x.device),
- ),
- dim=2,
- )
- regularization = torch.sqrt(torch.as_tensor(eps)) * (
- regularization[None, None, ...].expand((-1, nb_bins, -1, -1, -1))
- )
-
- # allocate the spatial covariance matrices
- R = [
- torch.zeros((nb_bins, nb_channels, nb_channels, 2), dtype=x.dtype, device=x.device)
- for j in range(nb_sources)
- ]
- weight: torch.Tensor = torch.zeros((nb_bins,), dtype=x.dtype, device=x.device)
-
- v: torch.Tensor = torch.zeros((nb_frames, nb_bins, nb_sources), dtype=x.dtype, device=x.device)
- for it in range(iterations):
- # constructing the mixture covariance matrix. Doing it with a loop
- # to avoid storing anytime in RAM the whole 6D tensor
-
- # update the PSD as the average spectrogram over channels
- v = torch.mean(torch.abs(y[..., 0, :]) ** 2 + torch.abs(y[..., 1, :]) ** 2, dim=-2)
-
- # update spatial covariance matrices (weighted update)
- for j in range(nb_sources):
- R[j] = torch.tensor(0.0, device=x.device)
- weight = torch.tensor(eps, device=x.device)
- pos: int = 0
- batch_size = batch_size if batch_size else nb_frames
- while pos < nb_frames:
- t = torch.arange(pos, min(nb_frames, pos + batch_size))
- pos = int(t[-1]) + 1
-
- R[j] = R[j] + torch.sum(_covariance(y[t, ..., j]), dim=0)
- weight = weight + torch.sum(v[t, ..., j], dim=0)
- R[j] = R[j] / weight[..., None, None, None]
- weight = torch.zeros_like(weight)
-
- # cloning y if we track gradient, because we're going to update it
- if y.requires_grad:
- y = y.clone()
-
- pos = 0
- while pos < nb_frames:
- t = torch.arange(pos, min(nb_frames, pos + batch_size))
- pos = int(t[-1]) + 1
-
- y[t, ...] = torch.tensor(0.0, device=x.device)
-
- # compute mix covariance matrix
- Cxx = regularization
- for j in range(nb_sources):
- Cxx = Cxx + (v[t, ..., j, None, None, None] * R[j][None, ...].clone())
-
- # invert it
- inv_Cxx = _invert(Cxx)
-
- # separate the sources
- for j in range(nb_sources):
-
- # create a wiener gain for this source
- gain = torch.zeros_like(inv_Cxx)
-
- # computes multichannel Wiener gain as v_j R_j inv_Cxx
- indices = torch.cartesian_prod(
- torch.arange(nb_channels),
- torch.arange(nb_channels),
- torch.arange(nb_channels),
- )
- for index in indices:
- gain[:, :, index[0], index[1], :] = _mul_add(
- R[j][None, :, index[0], index[2], :].clone(),
- inv_Cxx[:, :, index[2], index[1], :],
- gain[:, :, index[0], index[1], :],
- )
- gain = gain * v[t, ..., None, None, None, j]
-
- # apply it to the mixture
- for i in range(nb_channels):
- y[t, ..., j] = _mul_add(gain[..., i, :], x[t, ..., i, None, :], y[t, ..., j])
-
- return y, v, R
-
-
-def wiener(
- targets_spectrograms: torch.Tensor,
- mix_stft: torch.Tensor,
- iterations: int = 1,
- softmask: bool = False,
- residual: bool = False,
- scale_factor: float = 10.0,
- eps: float = 1e-10,
-):
- """Wiener-based separation for multichannel audio.
-
- The method uses the (possibly multichannel) spectrograms of the
- sources to separate the (complex) Short Term Fourier Transform of the
- mix. Separation is done in a sequential way by:
-
- * Getting an initial estimate. This can be done in two ways: either by
- directly using the spectrograms with the mixture phase, or
- by using a softmasking strategy. This initial phase is controlled
- by the `softmask` flag.
-
- * If required, adding an additional residual target as the mix minus
- all targets.
-
- * Refinining these initial estimates through a call to
- :func:`expectation_maximization` if the number of iterations is nonzero.
-
- This implementation also allows to specify the epsilon value used for
- regularization. It is based on [1]_, [2]_, [3]_, [4]_.
-
- References
- ----------
- .. [1] S. Uhlich and M. Porcu and F. Giron and M. Enenkl and T. Kemp and
- N. Takahashi and Y. Mitsufuji, "Improving music source separation based
- on deep neural networks through data augmentation and network
- blending." 2017 IEEE International Conference on Acoustics, Speech
- and Signal Processing (ICASSP). IEEE, 2017.
-
- .. [2] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel audio source
- separation with deep neural networks." IEEE/ACM Transactions on Audio,
- Speech, and Language Processing 24.9 (2016): 1652-1664.
-
- .. [3] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel music
- separation with deep neural networks." 2016 24th European Signal
- Processing Conference (EUSIPCO). IEEE, 2016.
-
- .. [4] A. Liutkus and R. Badeau and G. Richard "Kernel additive models for
- source separation." IEEE Transactions on Signal Processing
- 62.16 (2014): 4298-4310.
-
- Args:
- targets_spectrograms (Tensor): spectrograms of the sources
- [shape=(nb_frames, nb_bins, nb_channels, nb_sources)].
- This is a nonnegative tensor that is
- usually the output of the actual separation method of the user. The
- spectrograms may be mono, but they need to be 4-dimensional in all
- cases.
- mix_stft (Tensor): [shape=(nb_frames, nb_bins, nb_channels, complex=2)]
- STFT of the mixture signal.
- iterations (int): [scalar]
- number of iterations for the EM algorithm
- softmask (bool): Describes how the initial estimates are obtained.
- * if `False`, then the mixture phase will directly be used with the
- spectrogram as initial estimates.
- * if `True`, initial estimates are obtained by multiplying the
- complex mix element-wise with the ratio of each target spectrogram
- with the sum of them all. This strategy is better if the model are
- not really good, and worse otherwise.
- residual (bool): if `True`, an additional target is created, which is
- equal to the mixture minus the other targets, before application of
- expectation maximization
- eps (float): Epsilon value to use for computing the separations.
- This is used whenever division with a model energy is
- performed, i.e. when softmasking and when iterating the EM.
- It can be understood as the energy of the additional white noise
- that is taken out when separating.
-
- Returns:
- Tensor: shape=(nb_frames, nb_bins, nb_channels, complex=2, nb_sources)
- STFT of estimated sources
-
- Notes:
- * Be careful that you need *magnitude spectrogram estimates* for the
- case `softmask==False`.
- * `softmask=False` is recommended
- * The epsilon value will have a huge impact on performance. If it's
- large, only the parts of the signal with a significant energy will
- be kept in the sources. This epsilon then directly controls the
- energy of the reconstruction error.
-
- Warning:
- As in :func:`expectation_maximization`, we recommend converting the
- mixture `x` to double precision `torch.float64` *before* calling
- :func:`wiener`.
- """
- if softmask:
- # if we use softmask, we compute the ratio mask for all targets and
- # multiply by the mix stft
- y = (
- mix_stft[..., None]
- * (
- targets_spectrograms
- / (eps + torch.sum(targets_spectrograms, dim=-1, keepdim=True).to(mix_stft.dtype))
- )[..., None, :]
- )
- else:
- # otherwise, we just multiply the targets spectrograms with mix phase
- # we tacitly assume that we have magnitude estimates.
- angle = atan2(mix_stft[..., 1], mix_stft[..., 0])[..., None]
- nb_sources = targets_spectrograms.shape[-1]
- y = torch.zeros(
- mix_stft.shape + (nb_sources,), dtype=mix_stft.dtype, device=mix_stft.device
- )
- y[..., 0, :] = targets_spectrograms * torch.cos(angle)
- y[..., 1, :] = targets_spectrograms * torch.sin(angle)
-
- if residual:
- # if required, adding an additional target as the mix minus
- # available targets
- y = torch.cat([y, mix_stft[..., None] - y.sum(dim=-1, keepdim=True)], dim=-1)
-
- if iterations == 0:
- return y
-
- # we need to refine the estimates. Scales down the estimates for
- # numerical stability
- max_abs = torch.max(
- torch.as_tensor(1.0, dtype=mix_stft.dtype, device=mix_stft.device),
- torch.sqrt(_norm(mix_stft)).max() / scale_factor,
- )
-
- mix_stft = mix_stft / max_abs
- y = y / max_abs
-
- # call expectation maximization
- y = expectation_maximization(y, mix_stft, iterations, eps=eps)[0]
-
- # scale estimates up again
- y = y * max_abs
- return y
-
-
-def _covariance(y_j):
- """
- Compute the empirical covariance for a source.
-
- Args:
- y_j (Tensor): complex stft of the source.
- [shape=(nb_frames, nb_bins, nb_channels, 2)].
-
- Returns:
- Cj (Tensor): [shape=(nb_frames, nb_bins, nb_channels, nb_channels, 2)]
- just y_j * conj(y_j.T): empirical covariance for each TF bin.
- """
- (nb_frames, nb_bins, nb_channels) = y_j.shape[:-1]
- Cj = torch.zeros(
- (nb_frames, nb_bins, nb_channels, nb_channels, 2),
- dtype=y_j.dtype,
- device=y_j.device,
- )
- indices = torch.cartesian_prod(torch.arange(nb_channels), torch.arange(nb_channels))
- for index in indices:
- Cj[:, :, index[0], index[1], :] = _mul_add(
- y_j[:, :, index[0], :],
- _conj(y_j[:, :, index[1], :]),
- Cj[:, :, index[0], index[1], :],
- )
- return Cj</code></pre>
-</details>
-</section>
-<section>
-</section>
-<section>
-</section>
-<section>
-<h2 class="section-title" id="header-functions">Functions</h2>
-<dl>
-<dt id="openunmix.filtering.atan2"><code class="name flex">
-<span>def <span class="ident">atan2</span></span>(<span>y, x)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Element-wise arctangent function of y/x.
-Returns a new tensor with signed angles in radians.
-It is an alternative implementation of torch.atan2</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>y</code></strong> : <code>Tensor</code></dt>
-<dd>First input tensor</dd>
-<dt><strong><code>x</code></strong> : <code>Tensor</code></dt>
-<dd>Second input tensor [shape=y.shape]</dd>
-</dl>
-<h2 id="returns">Returns</h2>
-<dl>
-<dt><code>Tensor</code></dt>
-<dd>[shape=y.shape].</dd>
-</dl></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/filtering.py#L9-L30" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def atan2(y, x):
- r"""Element-wise arctangent function of y/x.
- Returns a new tensor with signed angles in radians.
- It is an alternative implementation of torch.atan2
-
- Args:
- y (Tensor): First input tensor
- x (Tensor): Second input tensor [shape=y.shape]
-
- Returns:
- Tensor: [shape=y.shape].
- """
- pi = 2 * torch.asin(torch.tensor(1.0))
- x += ((x == 0) & (y == 0)) * 1.0
- out = torch.atan(y / x)
- out += ((y >= 0) & (x < 0)) * pi
- out -= ((y < 0) & (x < 0)) * pi
- out *= 1 - ((y > 0) & (x == 0)) * 1.0
- out += ((y > 0) & (x == 0)) * (pi / 2)
- out *= 1 - ((y < 0) & (x == 0)) * 1.0
- out += ((y < 0) & (x == 0)) * (-pi / 2)
- return out</code></pre>
-</details>
-</dd>
-<dt id="openunmix.filtering.expectation_maximization"><code class="name flex">
-<span>def <span class="ident">expectation_maximization</span></span>(<span>y: torch.Tensor, x: torch.Tensor, iterations: int = 2, eps: float = 1e-10, batch_size: int = 200)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Expectation maximization algorithm, for refining source separation
-estimates.</p>
-<p>This algorithm allows to make source separation results better by
-enforcing multichannel consistency for the estimates. This usually means
-a better perceptual quality in terms of spatial artifacts.</p>
-<p>The implementation follows the details presented in [1]<em>, taking
-inspiration from the original EM algorithm proposed in [2]</em> and its
-weighted refinement proposed in [3]<em>, [4]</em>.
-It works by iteratively:</p>
-<ul>
-<li>
-<p>Re-estimate source parameters (power spectral densities and spatial
-covariance matrices) through :func:<code>get_local_gaussian_model</code>.</p>
-</li>
-<li>
-<p>Separate again the mixture with the new parameters by first computing
-the new modelled mixture covariance matrices with :func:<code>get_mix_model</code>,
-prepare the Wiener filters through :func:<code>wiener_gain</code> and apply them
-with :func:`apply_filter``.</p>
-</li>
-</ul>
-<h2 id="references">References</h2>
-<p>.. [1] S. Uhlich and M. Porcu and F. Giron and M. Enenkl and T. Kemp and
-N. Takahashi and Y. Mitsufuji, "Improving music source separation based
-on deep neural networks through data augmentation and network
-blending." 2017 IEEE International Conference on Acoustics, Speech
-and Signal Processing (ICASSP). IEEE, 2017.</p>
-<p>.. [2] N.Q. Duong and E. Vincent and R.Gribonval. "Under-determined
-reverberant audio source separation using a full-rank spatial
-covariance model." IEEE Transactions on Audio, Speech, and Language
-Processing 18.7 (2010): 1830-1840.</p>
-<p>.. [3] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel audio source
-separation with deep neural networks." IEEE/ACM Transactions on Audio,
-Speech, and Language Processing 24.9 (2016): 1652-1664.</p>
-<p>.. [4] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel music
-separation with deep neural networks." 2016 24th European Signal
-Processing Conference (EUSIPCO). IEEE, 2016.</p>
-<p>.. [5] A. Liutkus and R. Badeau and G. Richard "Kernel additive models for
-source separation." IEEE Transactions on Signal Processing
-62.16 (2014): 4298-4310.</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>y</code></strong> : <code>Tensor</code></dt>
-<dd>[shape=(nb_frames, nb_bins, nb_channels, 2, nb_sources)]
-initial estimates for the sources</dd>
-<dt><strong><code>x</code></strong> : <code>Tensor</code></dt>
-<dd>[shape=(nb_frames, nb_bins, nb_channels, 2)]
-complex STFT of the mixture signal</dd>
-<dt><strong><code>iterations</code></strong> : <code>int</code></dt>
-<dd>[scalar]
-number of iterations for the EM algorithm.</dd>
-<dt><strong><code>eps</code></strong> : <code>float</code> or <code>None</code></dt>
-<dd>[scalar]
-The epsilon value to use for regularization and filters.</dd>
-</dl>
-<h2 id="returns">Returns</h2>
-<p>y (Tensor): [shape=(nb_frames, nb_bins, nb_channels, 2, nb_sources)]
-estimated sources after iterations
-v (Tensor): [shape=(nb_frames, nb_bins, nb_sources)]
-estimated power spectral densities
-R (Tensor): [shape=(nb_bins, nb_channels, nb_channels, 2, nb_sources)]
-estimated spatial covariance matrices</p>
-<h2 id="notes">Notes</h2>
-<ul>
-<li>You need an initial estimate for the sources to apply this
-algorithm. This is precisely what the :func:<code><a title="openunmix.filtering.wiener" href="#openunmix.filtering.wiener">wiener()</a></code> function does.</li>
-<li>This algorithm <em>is not</em> an implementation of the "exact" EM
-proposed in [1]<em>. In particular, it does compute the posterior
-covariance matrices the same (exact) way. Instead, it uses the
-simplified approximate scheme initially proposed in [5]</em> and further
-refined in [3]<em>, [4]</em>, that boils down to just take the empirical
-covariance of the recent source estimates, followed by a weighted
-average for the update of the spatial covariance matrix. It has been
-empirically demonstrated that this simplified algorithm is more
-robust for music separation.</li>
-</ul>
-<h2 id="warning">Warning</h2>
-<p>It is <em>very</em> important to make sure <code>x.dtype</code> is <code>torch.float64</code>
-if you want double precision, because this function will <strong>not</strong>
-do such conversion for you from <code>torch.complex32</code>, in case you want the
-smaller RAM usage on purpose.</p>
-<p>It is usually always better in terms of quality to have double
-precision, by e.g. calling :func:<code><a title="openunmix.filtering.expectation_maximization" href="#openunmix.filtering.expectation_maximization">expectation_maximization()</a></code>
-with <code>x.to(torch.float64)</code>.</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/filtering.py#L154-L335" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def expectation_maximization(
- y: torch.Tensor,
- x: torch.Tensor,
- iterations: int = 2,
- eps: float = 1e-10,
- batch_size: int = 200,
-):
- r"""Expectation maximization algorithm, for refining source separation
- estimates.
-
- This algorithm allows to make source separation results better by
- enforcing multichannel consistency for the estimates. This usually means
- a better perceptual quality in terms of spatial artifacts.
-
- The implementation follows the details presented in [1]_, taking
- inspiration from the original EM algorithm proposed in [2]_ and its
- weighted refinement proposed in [3]_, [4]_.
- It works by iteratively:
-
- * Re-estimate source parameters (power spectral densities and spatial
- covariance matrices) through :func:`get_local_gaussian_model`.
-
- * Separate again the mixture with the new parameters by first computing
- the new modelled mixture covariance matrices with :func:`get_mix_model`,
- prepare the Wiener filters through :func:`wiener_gain` and apply them
- with :func:`apply_filter``.
-
- References
- ----------
- .. [1] S. Uhlich and M. Porcu and F. Giron and M. Enenkl and T. Kemp and
- N. Takahashi and Y. Mitsufuji, "Improving music source separation based
- on deep neural networks through data augmentation and network
- blending." 2017 IEEE International Conference on Acoustics, Speech
- and Signal Processing (ICASSP). IEEE, 2017.
-
- .. [2] N.Q. Duong and E. Vincent and R.Gribonval. "Under-determined
- reverberant audio source separation using a full-rank spatial
- covariance model." IEEE Transactions on Audio, Speech, and Language
- Processing 18.7 (2010): 1830-1840.
-
- .. [3] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel audio source
- separation with deep neural networks." IEEE/ACM Transactions on Audio,
- Speech, and Language Processing 24.9 (2016): 1652-1664.
-
- .. [4] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel music
- separation with deep neural networks." 2016 24th European Signal
- Processing Conference (EUSIPCO). IEEE, 2016.
-
- .. [5] A. Liutkus and R. Badeau and G. Richard "Kernel additive models for
- source separation." IEEE Transactions on Signal Processing
- 62.16 (2014): 4298-4310.
-
- Args:
- y (Tensor): [shape=(nb_frames, nb_bins, nb_channels, 2, nb_sources)]
- initial estimates for the sources
- x (Tensor): [shape=(nb_frames, nb_bins, nb_channels, 2)]
- complex STFT of the mixture signal
- iterations (int): [scalar]
- number of iterations for the EM algorithm.
- eps (float or None): [scalar]
- The epsilon value to use for regularization and filters.
-
- Returns:
- y (Tensor): [shape=(nb_frames, nb_bins, nb_channels, 2, nb_sources)]
- estimated sources after iterations
- v (Tensor): [shape=(nb_frames, nb_bins, nb_sources)]
- estimated power spectral densities
- R (Tensor): [shape=(nb_bins, nb_channels, nb_channels, 2, nb_sources)]
- estimated spatial covariance matrices
-
- Notes:
- * You need an initial estimate for the sources to apply this
- algorithm. This is precisely what the :func:`wiener` function does.
- * This algorithm *is not* an implementation of the "exact" EM
- proposed in [1]_. In particular, it does compute the posterior
- covariance matrices the same (exact) way. Instead, it uses the
- simplified approximate scheme initially proposed in [5]_ and further
- refined in [3]_, [4]_, that boils down to just take the empirical
- covariance of the recent source estimates, followed by a weighted
- average for the update of the spatial covariance matrix. It has been
- empirically demonstrated that this simplified algorithm is more
- robust for music separation.
-
- Warning:
- It is *very* important to make sure `x.dtype` is `torch.float64`
- if you want double precision, because this function will **not**
- do such conversion for you from `torch.complex32`, in case you want the
- smaller RAM usage on purpose.
-
- It is usually always better in terms of quality to have double
- precision, by e.g. calling :func:`expectation_maximization`
- with ``x.to(torch.float64)``.
- """
- # dimensions
- (nb_frames, nb_bins, nb_channels) = x.shape[:-1]
- nb_sources = y.shape[-1]
-
- regularization = torch.cat(
- (
- torch.eye(nb_channels, dtype=x.dtype, device=x.device)[..., None],
- torch.zeros((nb_channels, nb_channels, 1), dtype=x.dtype, device=x.device),
- ),
- dim=2,
- )
- regularization = torch.sqrt(torch.as_tensor(eps)) * (
- regularization[None, None, ...].expand((-1, nb_bins, -1, -1, -1))
- )
-
- # allocate the spatial covariance matrices
- R = [
- torch.zeros((nb_bins, nb_channels, nb_channels, 2), dtype=x.dtype, device=x.device)
- for j in range(nb_sources)
- ]
- weight: torch.Tensor = torch.zeros((nb_bins,), dtype=x.dtype, device=x.device)
-
- v: torch.Tensor = torch.zeros((nb_frames, nb_bins, nb_sources), dtype=x.dtype, device=x.device)
- for it in range(iterations):
- # constructing the mixture covariance matrix. Doing it with a loop
- # to avoid storing anytime in RAM the whole 6D tensor
-
- # update the PSD as the average spectrogram over channels
- v = torch.mean(torch.abs(y[..., 0, :]) ** 2 + torch.abs(y[..., 1, :]) ** 2, dim=-2)
-
- # update spatial covariance matrices (weighted update)
- for j in range(nb_sources):
- R[j] = torch.tensor(0.0, device=x.device)
- weight = torch.tensor(eps, device=x.device)
- pos: int = 0
- batch_size = batch_size if batch_size else nb_frames
- while pos < nb_frames:
- t = torch.arange(pos, min(nb_frames, pos + batch_size))
- pos = int(t[-1]) + 1
-
- R[j] = R[j] + torch.sum(_covariance(y[t, ..., j]), dim=0)
- weight = weight + torch.sum(v[t, ..., j], dim=0)
- R[j] = R[j] / weight[..., None, None, None]
- weight = torch.zeros_like(weight)
-
- # cloning y if we track gradient, because we're going to update it
- if y.requires_grad:
- y = y.clone()
-
- pos = 0
- while pos < nb_frames:
- t = torch.arange(pos, min(nb_frames, pos + batch_size))
- pos = int(t[-1]) + 1
-
- y[t, ...] = torch.tensor(0.0, device=x.device)
-
- # compute mix covariance matrix
- Cxx = regularization
- for j in range(nb_sources):
- Cxx = Cxx + (v[t, ..., j, None, None, None] * R[j][None, ...].clone())
-
- # invert it
- inv_Cxx = _invert(Cxx)
-
- # separate the sources
- for j in range(nb_sources):
-
- # create a wiener gain for this source
- gain = torch.zeros_like(inv_Cxx)
-
- # computes multichannel Wiener gain as v_j R_j inv_Cxx
- indices = torch.cartesian_prod(
- torch.arange(nb_channels),
- torch.arange(nb_channels),
- torch.arange(nb_channels),
- )
- for index in indices:
- gain[:, :, index[0], index[1], :] = _mul_add(
- R[j][None, :, index[0], index[2], :].clone(),
- inv_Cxx[:, :, index[2], index[1], :],
- gain[:, :, index[0], index[1], :],
- )
- gain = gain * v[t, ..., None, None, None, j]
-
- # apply it to the mixture
- for i in range(nb_channels):
- y[t, ..., j] = _mul_add(gain[..., i, :], x[t, ..., i, None, :], y[t, ..., j])
-
- return y, v, R</code></pre>
-</details>
-</dd>
-<dt id="openunmix.filtering.wiener"><code class="name flex">
-<span>def <span class="ident">wiener</span></span>(<span>targets_spectrograms: torch.Tensor, mix_stft: torch.Tensor, iterations: int = 1, softmask: bool = False, residual: bool = False, scale_factor: float = 10.0, eps: float = 1e-10)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Wiener-based separation for multichannel audio.</p>
-<p>The method uses the (possibly multichannel) spectrograms
-of the
-sources to separate the (complex) Short Term Fourier Transform
-of the
-mix. Separation is done in a sequential way by:</p>
-<ul>
-<li>
-<p>Getting an initial estimate. This can be done in two ways: either by
-directly using the spectrograms with the mixture phase, or
-by using a softmasking strategy. This initial phase is controlled
-by the <code>softmask</code> flag.</p>
-</li>
-<li>
-<p>If required, adding an additional residual target as the mix minus
-all targets.</p>
-</li>
-<li>
-<p>Refinining these initial estimates through a call to
-:func:<code><a title="openunmix.filtering.expectation_maximization" href="#openunmix.filtering.expectation_maximization">expectation_maximization()</a></code> if the number of iterations is nonzero.</p>
-</li>
-</ul>
-<p>This implementation also allows to specify the epsilon value used for
-regularization. It is based on [1]<em>, [2]</em>, [3]<em>, [4]</em>.</p>
-<h2 id="references">References</h2>
-<p>.. [1] S. Uhlich and M. Porcu and F. Giron and M. Enenkl and T. Kemp and
-N. Takahashi and Y. Mitsufuji, "Improving music source separation based
-on deep neural networks through data augmentation and network
-blending." 2017 IEEE International Conference on Acoustics, Speech
-and Signal Processing (ICASSP). IEEE, 2017.</p>
-<p>.. [2] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel audio source
-separation with deep neural networks." IEEE/ACM Transactions on Audio,
-Speech, and Language Processing 24.9 (2016): 1652-1664.</p>
-<p>.. [3] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel music
-separation with deep neural networks." 2016 24th European Signal
-Processing Conference (EUSIPCO). IEEE, 2016.</p>
-<p>.. [4] A. Liutkus and R. Badeau and G. Richard "Kernel additive models for
-source separation." IEEE Transactions on Signal Processing
-62.16 (2014): 4298-4310.</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>targets_spectrograms</code></strong> : <code>Tensor</code></dt>
-<dd>spectrograms of the sources
-[shape=(nb_frames, nb_bins, nb_channels, nb_sources)].
-This is a nonnegative tensor that is
-usually the output of the actual separation method of the user. The
-spectrograms may be mono, but they need to be 4-dimensional in all
-cases.</dd>
-<dt><strong><code>mix_stft</code></strong> : <code>Tensor</code></dt>
-<dd>[shape=(nb_frames, nb_bins, nb_channels, complex=2)]
-STFT of the mixture signal.</dd>
-<dt><strong><code>iterations</code></strong> : <code>int</code></dt>
-<dd>[scalar]
-number of iterations for the EM algorithm</dd>
-<dt><strong><code>softmask</code></strong> : <code>bool</code></dt>
-<dd>Describes how the initial estimates are obtained.
-* if <code>False</code>, then the mixture phase will directly be used with the
-spectrogram as initial estimates.
-* if <code>True</code>, initial estimates are obtained by multiplying the
-complex mix element-wise with the ratio of each target spectrogram
-with the sum of them all. This strategy is better if the model are
-not really good, and worse otherwise.</dd>
-<dt><strong><code>residual</code></strong> : <code>bool</code></dt>
-<dd>if <code>True</code>, an additional target is created, which is
-equal to the mixture minus the other targets, before application of
-expectation maximization</dd>
-<dt><strong><code>eps</code></strong> : <code>float</code></dt>
-<dd>Epsilon value to use for computing the separations.
-This is used whenever division with a model energy is
-performed, i.e. when softmasking and when iterating the EM.
-It can be understood as the energy of the additional white noise
-that is taken out when separating.</dd>
-</dl>
-<h2 id="returns">Returns</h2>
-<dl>
-<dt><code>Tensor</code></dt>
-<dd>shape=(nb_frames, nb_bins, nb_channels, complex=2, nb_sources)
-STFT of estimated sources</dd>
-</dl>
-<h2 id="notes">Notes</h2>
-<ul>
-<li>Be careful that you need <em>magnitude spectrogram estimates</em> for the
-case <code>softmask==False</code>.</li>
-<li><code>softmask=False</code> is recommended</li>
-<li>The epsilon value will have a huge impact on performance. If it's
-large, only the parts of the signal with a significant energy will
-be kept in the sources. This epsilon then directly controls the
-energy of the reconstruction error.</li>
-</ul>
-<h2 id="warning">Warning</h2>
-<p>As in :func:<code><a title="openunmix.filtering.expectation_maximization" href="#openunmix.filtering.expectation_maximization">expectation_maximization()</a></code>, we recommend converting the
-mixture <code>x</code> to double precision <code>torch.float64</code> <em>before</em> calling
-:func:<code><a title="openunmix.filtering.wiener" href="#openunmix.filtering.wiener">wiener()</a></code>.</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/filtering.py#L338-L476" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def wiener(
- targets_spectrograms: torch.Tensor,
- mix_stft: torch.Tensor,
- iterations: int = 1,
- softmask: bool = False,
- residual: bool = False,
- scale_factor: float = 10.0,
- eps: float = 1e-10,
-):
- """Wiener-based separation for multichannel audio.
-
- The method uses the (possibly multichannel) spectrograms of the
- sources to separate the (complex) Short Term Fourier Transform of the
- mix. Separation is done in a sequential way by:
-
- * Getting an initial estimate. This can be done in two ways: either by
- directly using the spectrograms with the mixture phase, or
- by using a softmasking strategy. This initial phase is controlled
- by the `softmask` flag.
-
- * If required, adding an additional residual target as the mix minus
- all targets.
-
- * Refinining these initial estimates through a call to
- :func:`expectation_maximization` if the number of iterations is nonzero.
-
- This implementation also allows to specify the epsilon value used for
- regularization. It is based on [1]_, [2]_, [3]_, [4]_.
-
- References
- ----------
- .. [1] S. Uhlich and M. Porcu and F. Giron and M. Enenkl and T. Kemp and
- N. Takahashi and Y. Mitsufuji, "Improving music source separation based
- on deep neural networks through data augmentation and network
- blending." 2017 IEEE International Conference on Acoustics, Speech
- and Signal Processing (ICASSP). IEEE, 2017.
-
- .. [2] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel audio source
- separation with deep neural networks." IEEE/ACM Transactions on Audio,
- Speech, and Language Processing 24.9 (2016): 1652-1664.
-
- .. [3] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel music
- separation with deep neural networks." 2016 24th European Signal
- Processing Conference (EUSIPCO). IEEE, 2016.
-
- .. [4] A. Liutkus and R. Badeau and G. Richard "Kernel additive models for
- source separation." IEEE Transactions on Signal Processing
- 62.16 (2014): 4298-4310.
-
- Args:
- targets_spectrograms (Tensor): spectrograms of the sources
- [shape=(nb_frames, nb_bins, nb_channels, nb_sources)].
- This is a nonnegative tensor that is
- usually the output of the actual separation method of the user. The
- spectrograms may be mono, but they need to be 4-dimensional in all
- cases.
- mix_stft (Tensor): [shape=(nb_frames, nb_bins, nb_channels, complex=2)]
- STFT of the mixture signal.
- iterations (int): [scalar]
- number of iterations for the EM algorithm
- softmask (bool): Describes how the initial estimates are obtained.
- * if `False`, then the mixture phase will directly be used with the
- spectrogram as initial estimates.
- * if `True`, initial estimates are obtained by multiplying the
- complex mix element-wise with the ratio of each target spectrogram
- with the sum of them all. This strategy is better if the model are
- not really good, and worse otherwise.
- residual (bool): if `True`, an additional target is created, which is
- equal to the mixture minus the other targets, before application of
- expectation maximization
- eps (float): Epsilon value to use for computing the separations.
- This is used whenever division with a model energy is
- performed, i.e. when softmasking and when iterating the EM.
- It can be understood as the energy of the additional white noise
- that is taken out when separating.
-
- Returns:
- Tensor: shape=(nb_frames, nb_bins, nb_channels, complex=2, nb_sources)
- STFT of estimated sources
-
- Notes:
- * Be careful that you need *magnitude spectrogram estimates* for the
- case `softmask==False`.
- * `softmask=False` is recommended
- * The epsilon value will have a huge impact on performance. If it's
- large, only the parts of the signal with a significant energy will
- be kept in the sources. This epsilon then directly controls the
- energy of the reconstruction error.
-
- Warning:
- As in :func:`expectation_maximization`, we recommend converting the
- mixture `x` to double precision `torch.float64` *before* calling
- :func:`wiener`.
- """
- if softmask:
- # if we use softmask, we compute the ratio mask for all targets and
- # multiply by the mix stft
- y = (
- mix_stft[..., None]
- * (
- targets_spectrograms
- / (eps + torch.sum(targets_spectrograms, dim=-1, keepdim=True).to(mix_stft.dtype))
- )[..., None, :]
- )
- else:
- # otherwise, we just multiply the targets spectrograms with mix phase
- # we tacitly assume that we have magnitude estimates.
- angle = atan2(mix_stft[..., 1], mix_stft[..., 0])[..., None]
- nb_sources = targets_spectrograms.shape[-1]
- y = torch.zeros(
- mix_stft.shape + (nb_sources,), dtype=mix_stft.dtype, device=mix_stft.device
- )
- y[..., 0, :] = targets_spectrograms * torch.cos(angle)
- y[..., 1, :] = targets_spectrograms * torch.sin(angle)
-
- if residual:
- # if required, adding an additional target as the mix minus
- # available targets
- y = torch.cat([y, mix_stft[..., None] - y.sum(dim=-1, keepdim=True)], dim=-1)
-
- if iterations == 0:
- return y
-
- # we need to refine the estimates. Scales down the estimates for
- # numerical stability
- max_abs = torch.max(
- torch.as_tensor(1.0, dtype=mix_stft.dtype, device=mix_stft.device),
- torch.sqrt(_norm(mix_stft)).max() / scale_factor,
- )
-
- mix_stft = mix_stft / max_abs
- y = y / max_abs
-
- # call expectation maximization
- y = expectation_maximization(y, mix_stft, iterations, eps=eps)[0]
-
- # scale estimates up again
- y = y * max_abs
- return y</code></pre>
-</details>
-</dd>
-</dl>
-</section>
-<section>
-</section>
-</article>
-<nav id="sidebar">
-<h1>Index</h1>
-<div class="toc">
-<ul></ul>
-</div>
-<ul id="index">
-<li><h3>Super-module</h3>
-<ul>
-<li><code><a title="openunmix" href="index.html">openunmix</a></code></li>
-</ul>
-</li>
-<li><h3><a href="#header-functions">Functions</a></h3>
-<ul class="">
-<li><code><a title="openunmix.filtering.atan2" href="#openunmix.filtering.atan2">atan2</a></code></li>
-<li><code><a title="openunmix.filtering.expectation_maximization" href="#openunmix.filtering.expectation_maximization">expectation_maximization</a></code></li>
-<li><code><a title="openunmix.filtering.wiener" href="#openunmix.filtering.wiener">wiener</a></code></li>
-</ul>
-</li>
-</ul>
-</nav>
-</main>
-<footer id="footer">
-<p>Generated by <a href="https://pdoc3.github.io/pdoc"><cite>pdoc</cite> 0.9.2</a>.</p>
-</footer>
-</body>
-</html>
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/index.html b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/index.html
deleted file mode 100644
index 44c833486131d52bfbc692ecd3f8322d8e2ed827..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/index.html
+++ /dev/null
@@ -1,768 +0,0 @@
-<!doctype html>
-<html lang="en">
-<head>
-<meta charset="utf-8">
-<meta name="viewport" content="width=device-width, initial-scale=1, minimum-scale=1" />
-<meta name="generator" content="pdoc 0.9.2" />
-<title>openunmix API documentation</title>
-<meta name="description" content="
-Open-Unmix is a deep neural network reference implementation for music source separation, applicable …" />
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/sanitize.min.css" integrity="sha256-PK9q560IAAa6WVRRh76LtCaI8pjTJ2z11v0miyNNjrs=" crossorigin>
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/typography.min.css" integrity="sha256-7l/o7C8jubJiy74VsKTidCy1yBkRtiUGbVkYBylBqUg=" crossorigin>
-<link rel="stylesheet preload" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/styles/github.min.css" crossorigin>
-<style>:root{--highlight-color:#fe9}.flex{display:flex !important}body{line-height:1.5em}#content{padding:20px}#sidebar{padding:30px;overflow:hidden}#sidebar > *:last-child{margin-bottom:2cm}.http-server-breadcrumbs{font-size:130%;margin:0 0 15px 0}#footer{font-size:.75em;padding:5px 30px;border-top:1px solid #ddd;text-align:right}#footer p{margin:0 0 0 1em;display:inline-block}#footer p:last-child{margin-right:30px}h1,h2,h3,h4,h5{font-weight:300}h1{font-size:2.5em;line-height:1.1em}h2{font-size:1.75em;margin:1em 0 .50em 0}h3{font-size:1.4em;margin:25px 0 10px 0}h4{margin:0;font-size:105%}h1:target,h2:target,h3:target,h4:target,h5:target,h6:target{background:var(--highlight-color);padding:.2em 0}a{color:#058;text-decoration:none;transition:color .3s ease-in-out}a:hover{color:#e82}.title code{font-weight:bold}h2[id^="header-"]{margin-top:2em}.ident{color:#900}pre code{background:#f8f8f8;font-size:.8em;line-height:1.4em}code{background:#f2f2f1;padding:1px 4px;overflow-wrap:break-word}h1 code{background:transparent}pre{background:#f8f8f8;border:0;border-top:1px solid #ccc;border-bottom:1px solid #ccc;margin:1em 0;padding:1ex}#http-server-module-list{display:flex;flex-flow:column}#http-server-module-list div{display:flex}#http-server-module-list dt{min-width:10%}#http-server-module-list p{margin-top:0}.toc ul,#index{list-style-type:none;margin:0;padding:0}#index code{background:transparent}#index h3{border-bottom:1px solid #ddd}#index ul{padding:0}#index h4{margin-top:.6em;font-weight:bold}@media (min-width:200ex){#index .two-column{column-count:2}}@media (min-width:300ex){#index .two-column{column-count:3}}dl{margin-bottom:2em}dl dl:last-child{margin-bottom:4em}dd{margin:0 0 1em 3em}#header-classes + dl > dd{margin-bottom:3em}dd dd{margin-left:2em}dd p{margin:10px 0}.name{background:#eee;font-weight:bold;font-size:.85em;padding:5px 10px;display:inline-block;min-width:40%}.name:hover{background:#e0e0e0}dt:target .name{background:var(--highlight-color)}.name > span:first-child{white-space:nowrap}.name.class > span:nth-child(2){margin-left:.4em}.inherited{color:#999;border-left:5px solid #eee;padding-left:1em}.inheritance em{font-style:normal;font-weight:bold}.desc h2{font-weight:400;font-size:1.25em}.desc h3{font-size:1em}.desc dt code{background:inherit}.source summary,.git-link-div{color:#666;text-align:right;font-weight:400;font-size:.8em;text-transform:uppercase}.source summary > *{white-space:nowrap;cursor:pointer}.git-link{color:inherit;margin-left:1em}.source pre{max-height:500px;overflow:auto;margin:0}.source pre code{font-size:12px;overflow:visible}.hlist{list-style:none}.hlist li{display:inline}.hlist li:after{content:',\2002'}.hlist li:last-child:after{content:none}.hlist .hlist{display:inline;padding-left:1em}img{max-width:100%}td{padding:0 .5em}.admonition{padding:.1em .5em;margin-bottom:1em}.admonition-title{font-weight:bold}.admonition.note,.admonition.info,.admonition.important{background:#aef}.admonition.todo,.admonition.versionadded,.admonition.tip,.admonition.hint{background:#dfd}.admonition.warning,.admonition.versionchanged,.admonition.deprecated{background:#fd4}.admonition.error,.admonition.danger,.admonition.caution{background:lightpink}</style>
-<style media="screen and (min-width: 700px)">@media screen and (min-width:700px){#sidebar{width:30%;height:100vh;overflow:auto;position:sticky;top:0}#content{width:70%;max-width:100ch;padding:3em 4em;border-left:1px solid #ddd}pre code{font-size:1em}.item .name{font-size:1em}main{display:flex;flex-direction:row-reverse;justify-content:flex-end}.toc ul ul,#index ul{padding-left:1.5em}.toc > ul > li{margin-top:.5em}}</style>
-<style media="print">@media print{#sidebar h1{page-break-before:always}.source{display:none}}@media print{*{background:transparent !important;color:#000 !important;box-shadow:none !important;text-shadow:none !important}a[href]:after{content:" (" attr(href) ")";font-size:90%}a[href][title]:after{content:none}abbr[title]:after{content:" (" attr(title) ")"}.ir a:after,a[href^="javascript:"]:after,a[href^="#"]:after{content:""}pre,blockquote{border:1px solid #999;page-break-inside:avoid}thead{display:table-header-group}tr,img{page-break-inside:avoid}img{max-width:100% !important}@page{margin:0.5cm}p,h2,h3{orphans:3;widows:3}h1,h2,h3,h4,h5,h6{page-break-after:avoid}}</style>
-<script async src="https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.7/latest.js?config=TeX-AMS_CHTML" integrity="sha256-kZafAc6mZvK3W3v1pHOcUix30OHQN6pU/NO2oFkqZVw=" crossorigin></script>
-<script defer src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/highlight.min.js" integrity="sha256-Uv3H6lx7dJmRfRvH8TH6kJD1TSK1aFcwgx+mdg3epi8=" crossorigin></script>
-<script>window.addEventListener('DOMContentLoaded', () => hljs.initHighlighting())</script>
-</head>
-<body>
-<main>
-<article id="content">
-<header>
-<h1 class="title">Package <code>openunmix</code></h1>
-</header>
-<section id="section-intro">
-<p><img alt="sigsep logo" src="https://sigsep.github.io/hero.png">
-Open-Unmix is a deep neural network reference implementation for music source separation, applicable for researchers, audio engineers and artists. Open-Unmix provides ready-to-use models that allow users to separate pop music into four stems: vocals, drums, bass and the remaining other instruments. The models were pre-trained on the MUSDB18 dataset. See details at apply pre-trained model.</p>
-<p>This is the python package API documentation.
-Please checkout <a href="https://sigsep.github.io/open-unmix">the open-unmix website</a> for more information.</p>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/__init__.py#L0-L260" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">"""
-
-Open-Unmix is a deep neural network reference implementation for music source separation, applicable for researchers, audio engineers and artists. Open-Unmix provides ready-to-use models that allow users to separate pop music into four stems: vocals, drums, bass and the remaining other instruments. The models were pre-trained on the MUSDB18 dataset. See details at apply pre-trained model.
-
-This is the python package API documentation.
-Please checkout [the open-unmix website](https://sigsep.github.io/open-unmix) for more information.
-"""
-from openunmix import utils
-import torch.hub
-
-
-def umxse_spec(targets=None, device="cpu", pretrained=True):
- target_urls = {
- "speech": "https://zenodo.org/api/files/765b45a3-c70d-48a6-936b-09a7989c349a/speech_f5e0d9f9.pth",
- "noise": "https://zenodo.org/api/files/765b45a3-c70d-48a6-936b-09a7989c349a/noise_04a6fc2d.pth",
- }
-
- from .model import OpenUnmix
-
- if targets is None:
- targets = ["speech", "noise"]
-
- # determine the maximum bin count for a 16khz bandwidth model
- max_bin = utils.bandwidth_to_max_bin(rate=16000.0, n_fft=1024, bandwidth=16000)
-
- # load open unmix models speech enhancement models
- target_models = {}
- for target in targets:
- target_unmix = OpenUnmix(
- nb_bins=1024 // 2 + 1, nb_channels=1, hidden_size=256, max_bin=max_bin
- )
-
- # enable centering of stft to minimize reconstruction error
- if pretrained:
- state_dict = torch.hub.load_state_dict_from_url(
- target_urls[target], map_location=device
- )
- target_unmix.load_state_dict(state_dict, strict=False)
- target_unmix.eval()
-
- target_unmix.to(device)
- target_models[target] = target_unmix
- return target_models
-
-
-def umxse(
- targets=None,
- residual=False,
- niter=1,
- device="cpu",
- pretrained=True,
- filterbank="torch",
-):
- """
- Open Unmix Speech Enhancemennt 1-channel BiLSTM Model
- trained on the 28-speaker version of Voicebank+Demand
- (Sampling rate: 16kHz)
-
- Args:
- targets (str): select the targets for the source to be separated.
- a list including: ['speech', 'noise'].
- If you don't pick them all, you probably want to
- activate the `residual=True` option.
- Defaults to all available targets per model.
- pretrained (bool): If True, returns a model pre-trained on MUSDB18-HQ
- residual (bool): if True, a "garbage" target is created
- niter (int): the number of post-processingiterations, defaults to 0
- device (str): selects device to be used for inference
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
-
- Reference:
- Uhlich, Stefan, & Mitsufuji, Yuki. (2020).
- Open-Unmix for Speech Enhancement (UMX SE).
- Zenodo. http://doi.org/10.5281/zenodo.3786908
- """
- from .model import Separator
-
- target_models = umxse_spec(targets=targets, device=device, pretrained=pretrained)
-
- separator = Separator(
- target_models=target_models,
- niter=niter,
- residual=residual,
- n_fft=1024,
- n_hop=512,
- nb_channels=1,
- sample_rate=16000.0,
- filterbank=filterbank,
- ).to(device)
-
- return separator
-
-
-def umxhq_spec(targets=None, device="cpu", pretrained=True):
- from .model import OpenUnmix
-
- # set urls for weights
- target_urls = {
- "bass": "https://zenodo.org/api/files/1c8f83c5-33a5-4f59-b109-721fdd234875/bass-8d85a5bd.pth",
- "drums": "https://zenodo.org/api/files/1c8f83c5-33a5-4f59-b109-721fdd234875/drums-9619578f.pth",
- "other": "https://zenodo.org/api/files/1c8f83c5-33a5-4f59-b109-721fdd234875/other-b52fbbf7.pth",
- "vocals": "https://zenodo.org/api/files/1c8f83c5-33a5-4f59-b109-721fdd234875/vocals-b62c91ce.pth",
- }
-
- if targets is None:
- targets = ["vocals", "drums", "bass", "other"]
-
- # determine the maximum bin count for a 16khz bandwidth model
- max_bin = utils.bandwidth_to_max_bin(rate=44100.0, n_fft=4096, bandwidth=16000)
-
- target_models = {}
- for target in targets:
- # load open unmix model
- target_unmix = OpenUnmix(
- nb_bins=4096 // 2 + 1, nb_channels=2, hidden_size=512, max_bin=max_bin
- )
-
- # enable centering of stft to minimize reconstruction error
- if pretrained:
- state_dict = torch.hub.load_state_dict_from_url(
- target_urls[target], map_location=device
- )
- target_unmix.load_state_dict(state_dict, strict=False)
- target_unmix.eval()
-
- target_unmix.to(device)
- target_models[target] = target_unmix
- return target_models
-
-
-def umxhq(
- targets=None,
- residual=False,
- niter=1,
- device="cpu",
- pretrained=True,
- filterbank="torch",
-):
- """
- Open Unmix 2-channel/stereo BiLSTM Model trained on MUSDB18-HQ
-
- Args:
- targets (str): select the targets for the source to be separated.
- a list including: ['vocals', 'drums', 'bass', 'other'].
- If you don't pick them all, you probably want to
- activate the `residual=True` option.
- Defaults to all available targets per model.
- pretrained (bool): If True, returns a model pre-trained on MUSDB18-HQ
- residual (bool): if True, a "garbage" target is created
- niter (int): the number of post-processingiterations, defaults to 0
- device (str): selects device to be used for inference
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
- """
-
- from .model import Separator
-
- target_models = umxhq_spec(targets=targets, device=device, pretrained=pretrained)
-
- separator = Separator(
- target_models=target_models,
- niter=niter,
- residual=residual,
- n_fft=4096,
- n_hop=1024,
- nb_channels=2,
- sample_rate=44100.0,
- filterbank=filterbank,
- ).to(device)
-
- return separator
-
-
-def umx_spec(targets=None, device="cpu", pretrained=True):
- from .model import OpenUnmix
-
- # set urls for weights
- target_urls = {
- "bass": "https://zenodo.org/api/files/d6105b95-8c52-430c-84ce-bd14b803faaf/bass-646024d3.pth",
- "drums": "https://zenodo.org/api/files/d6105b95-8c52-430c-84ce-bd14b803faaf/drums-5a48008b.pth",
- "other": "https://zenodo.org/api/files/d6105b95-8c52-430c-84ce-bd14b803faaf/other-f8e132cc.pth",
- "vocals": "https://zenodo.org/api/files/d6105b95-8c52-430c-84ce-bd14b803faaf/vocals-c8df74a5.pth",
- }
-
- if targets is None:
- targets = ["vocals", "drums", "bass", "other"]
-
- # determine the maximum bin count for a 16khz bandwidth model
- max_bin = utils.bandwidth_to_max_bin(rate=44100.0, n_fft=4096, bandwidth=16000)
-
- target_models = {}
- for target in targets:
- # load open unmix model
- target_unmix = OpenUnmix(
- nb_bins=4096 // 2 + 1, nb_channels=2, hidden_size=512, max_bin=max_bin
- )
-
- # enable centering of stft to minimize reconstruction error
- if pretrained:
- state_dict = torch.hub.load_state_dict_from_url(
- target_urls[target], map_location=device
- )
- target_unmix.load_state_dict(state_dict, strict=False)
- target_unmix.eval()
-
- target_unmix.to(device)
- target_models[target] = target_unmix
- return target_models
-
-
-def umx(
- targets=None,
- residual=False,
- niter=1,
- device="cpu",
- pretrained=True,
- filterbank="torch",
-):
- """
- Open Unmix 2-channel/stereo BiLSTM Model trained on MUSDB18
-
- Args:
- targets (str): select the targets for the source to be separated.
- a list including: ['vocals', 'drums', 'bass', 'other'].
- If you don't pick them all, you probably want to
- activate the `residual=True` option.
- Defaults to all available targets per model.
- pretrained (bool): If True, returns a model pre-trained on MUSDB18-HQ
- residual (bool): if True, a "garbage" target is created
- niter (int): the number of post-processingiterations, defaults to 0
- device (str): selects device to be used for inference
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
-
- """
-
- from .model import Separator
-
- target_models = umx_spec(targets=targets, device=device, pretrained=pretrained)
- separator = Separator(
- target_models=target_models,
- niter=niter,
- residual=residual,
- n_fft=4096,
- n_hop=1024,
- nb_channels=2,
- sample_rate=44100.0,
- filterbank=filterbank,
- ).to(device)
-
- return separator</code></pre>
-</details>
-</section>
-<section>
-<h2 class="section-title" id="header-submodules">Sub-modules</h2>
-<dl>
-<dt><code class="name"><a title="openunmix.cli" href="cli.html">openunmix.cli</a></code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-<dt><code class="name"><a title="openunmix.data" href="data.html">openunmix.data</a></code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-<dt><code class="name"><a title="openunmix.evaluate" href="evaluate.html">openunmix.evaluate</a></code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-<dt><code class="name"><a title="openunmix.filtering" href="filtering.html">openunmix.filtering</a></code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-<dt><code class="name"><a title="openunmix.model" href="model.html">openunmix.model</a></code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-<dt><code class="name"><a title="openunmix.predict" href="predict.html">openunmix.predict</a></code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-<dt><code class="name"><a title="openunmix.transforms" href="transforms.html">openunmix.transforms</a></code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-<dt><code class="name"><a title="openunmix.utils" href="utils.html">openunmix.utils</a></code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-</dl>
-</section>
-<section>
-</section>
-<section>
-<h2 class="section-title" id="header-functions">Functions</h2>
-<dl>
-<dt id="openunmix.umx"><code class="name flex">
-<span>def <span class="ident">umx</span></span>(<span>targets=None, residual=False, niter=1, device='cpu', pretrained=True, filterbank='torch')</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Open Unmix 2-channel/stereo BiLSTM Model trained on MUSDB18</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>targets</code></strong> : <code>str</code></dt>
-<dd>select the targets for the source to be separated.
-a list including: ['vocals', 'drums', 'bass', 'other'].
-If you don't pick them all, you probably want to
-activate the <code>residual=True</code> option.
-Defaults to all available targets per model.</dd>
-<dt><strong><code>pretrained</code></strong> : <code>bool</code></dt>
-<dd>If True, returns a model pre-trained on MUSDB18-HQ</dd>
-<dt><strong><code>residual</code></strong> : <code>bool</code></dt>
-<dd>if True, a "garbage" target is created</dd>
-<dt><strong><code>niter</code></strong> : <code>int</code></dt>
-<dd>the number of post-processingiterations, defaults to 0</dd>
-<dt><strong><code>device</code></strong> : <code>str</code></dt>
-<dd>selects device to be used for inference</dd>
-<dt><strong><code>filterbank</code></strong> : <code>str</code></dt>
-<dd>filterbank implementation method.
-Supported are <code>['torch', 'asteroid']</code>. <code>torch</code> is about 30% faster
-compared to <code>asteroid</code> on large FFT sizes such as 4096. However,
-asteroids stft can be exported to onnx, which makes is practical
-for deployment.</dd>
-</dl></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/__init__.py#L218-L261" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def umx(
- targets=None,
- residual=False,
- niter=1,
- device="cpu",
- pretrained=True,
- filterbank="torch",
-):
- """
- Open Unmix 2-channel/stereo BiLSTM Model trained on MUSDB18
-
- Args:
- targets (str): select the targets for the source to be separated.
- a list including: ['vocals', 'drums', 'bass', 'other'].
- If you don't pick them all, you probably want to
- activate the `residual=True` option.
- Defaults to all available targets per model.
- pretrained (bool): If True, returns a model pre-trained on MUSDB18-HQ
- residual (bool): if True, a "garbage" target is created
- niter (int): the number of post-processingiterations, defaults to 0
- device (str): selects device to be used for inference
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
-
- """
-
- from .model import Separator
-
- target_models = umx_spec(targets=targets, device=device, pretrained=pretrained)
- separator = Separator(
- target_models=target_models,
- niter=niter,
- residual=residual,
- n_fft=4096,
- n_hop=1024,
- nb_channels=2,
- sample_rate=44100.0,
- filterbank=filterbank,
- ).to(device)
-
- return separator</code></pre>
-</details>
-</dd>
-<dt id="openunmix.umx_spec"><code class="name flex">
-<span>def <span class="ident">umx_spec</span></span>(<span>targets=None, device='cpu', pretrained=True)</span>
-</code></dt>
-<dd>
-<div class="desc"></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/__init__.py#L181-L215" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def umx_spec(targets=None, device="cpu", pretrained=True):
- from .model import OpenUnmix
-
- # set urls for weights
- target_urls = {
- "bass": "https://zenodo.org/api/files/d6105b95-8c52-430c-84ce-bd14b803faaf/bass-646024d3.pth",
- "drums": "https://zenodo.org/api/files/d6105b95-8c52-430c-84ce-bd14b803faaf/drums-5a48008b.pth",
- "other": "https://zenodo.org/api/files/d6105b95-8c52-430c-84ce-bd14b803faaf/other-f8e132cc.pth",
- "vocals": "https://zenodo.org/api/files/d6105b95-8c52-430c-84ce-bd14b803faaf/vocals-c8df74a5.pth",
- }
-
- if targets is None:
- targets = ["vocals", "drums", "bass", "other"]
-
- # determine the maximum bin count for a 16khz bandwidth model
- max_bin = utils.bandwidth_to_max_bin(rate=44100.0, n_fft=4096, bandwidth=16000)
-
- target_models = {}
- for target in targets:
- # load open unmix model
- target_unmix = OpenUnmix(
- nb_bins=4096 // 2 + 1, nb_channels=2, hidden_size=512, max_bin=max_bin
- )
-
- # enable centering of stft to minimize reconstruction error
- if pretrained:
- state_dict = torch.hub.load_state_dict_from_url(
- target_urls[target], map_location=device
- )
- target_unmix.load_state_dict(state_dict, strict=False)
- target_unmix.eval()
-
- target_unmix.to(device)
- target_models[target] = target_unmix
- return target_models</code></pre>
-</details>
-</dd>
-<dt id="openunmix.umxhq"><code class="name flex">
-<span>def <span class="ident">umxhq</span></span>(<span>targets=None, residual=False, niter=1, device='cpu', pretrained=True, filterbank='torch')</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Open Unmix 2-channel/stereo BiLSTM Model trained on MUSDB18-HQ</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>targets</code></strong> : <code>str</code></dt>
-<dd>select the targets for the source to be separated.
-a list including: ['vocals', 'drums', 'bass', 'other'].
-If you don't pick them all, you probably want to
-activate the <code>residual=True</code> option.
-Defaults to all available targets per model.</dd>
-<dt><strong><code>pretrained</code></strong> : <code>bool</code></dt>
-<dd>If True, returns a model pre-trained on MUSDB18-HQ</dd>
-<dt><strong><code>residual</code></strong> : <code>bool</code></dt>
-<dd>if True, a "garbage" target is created</dd>
-<dt><strong><code>niter</code></strong> : <code>int</code></dt>
-<dd>the number of post-processingiterations, defaults to 0</dd>
-<dt><strong><code>device</code></strong> : <code>str</code></dt>
-<dd>selects device to be used for inference</dd>
-<dt><strong><code>filterbank</code></strong> : <code>str</code></dt>
-<dd>filterbank implementation method.
-Supported are <code>['torch', 'asteroid']</code>. <code>torch</code> is about 30% faster
-compared to <code>asteroid</code> on large FFT sizes such as 4096. However,
-asteroids stft can be exported to onnx, which makes is practical
-for deployment.</dd>
-</dl></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/__init__.py#L135-L178" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def umxhq(
- targets=None,
- residual=False,
- niter=1,
- device="cpu",
- pretrained=True,
- filterbank="torch",
-):
- """
- Open Unmix 2-channel/stereo BiLSTM Model trained on MUSDB18-HQ
-
- Args:
- targets (str): select the targets for the source to be separated.
- a list including: ['vocals', 'drums', 'bass', 'other'].
- If you don't pick them all, you probably want to
- activate the `residual=True` option.
- Defaults to all available targets per model.
- pretrained (bool): If True, returns a model pre-trained on MUSDB18-HQ
- residual (bool): if True, a "garbage" target is created
- niter (int): the number of post-processingiterations, defaults to 0
- device (str): selects device to be used for inference
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
- """
-
- from .model import Separator
-
- target_models = umxhq_spec(targets=targets, device=device, pretrained=pretrained)
-
- separator = Separator(
- target_models=target_models,
- niter=niter,
- residual=residual,
- n_fft=4096,
- n_hop=1024,
- nb_channels=2,
- sample_rate=44100.0,
- filterbank=filterbank,
- ).to(device)
-
- return separator</code></pre>
-</details>
-</dd>
-<dt id="openunmix.umxhq_spec"><code class="name flex">
-<span>def <span class="ident">umxhq_spec</span></span>(<span>targets=None, device='cpu', pretrained=True)</span>
-</code></dt>
-<dd>
-<div class="desc"></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/__init__.py#L98-L132" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def umxhq_spec(targets=None, device="cpu", pretrained=True):
- from .model import OpenUnmix
-
- # set urls for weights
- target_urls = {
- "bass": "https://zenodo.org/api/files/1c8f83c5-33a5-4f59-b109-721fdd234875/bass-8d85a5bd.pth",
- "drums": "https://zenodo.org/api/files/1c8f83c5-33a5-4f59-b109-721fdd234875/drums-9619578f.pth",
- "other": "https://zenodo.org/api/files/1c8f83c5-33a5-4f59-b109-721fdd234875/other-b52fbbf7.pth",
- "vocals": "https://zenodo.org/api/files/1c8f83c5-33a5-4f59-b109-721fdd234875/vocals-b62c91ce.pth",
- }
-
- if targets is None:
- targets = ["vocals", "drums", "bass", "other"]
-
- # determine the maximum bin count for a 16khz bandwidth model
- max_bin = utils.bandwidth_to_max_bin(rate=44100.0, n_fft=4096, bandwidth=16000)
-
- target_models = {}
- for target in targets:
- # load open unmix model
- target_unmix = OpenUnmix(
- nb_bins=4096 // 2 + 1, nb_channels=2, hidden_size=512, max_bin=max_bin
- )
-
- # enable centering of stft to minimize reconstruction error
- if pretrained:
- state_dict = torch.hub.load_state_dict_from_url(
- target_urls[target], map_location=device
- )
- target_unmix.load_state_dict(state_dict, strict=False)
- target_unmix.eval()
-
- target_unmix.to(device)
- target_models[target] = target_unmix
- return target_models</code></pre>
-</details>
-</dd>
-<dt id="openunmix.umxse"><code class="name flex">
-<span>def <span class="ident">umxse</span></span>(<span>targets=None, residual=False, niter=1, device='cpu', pretrained=True, filterbank='torch')</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Open Unmix Speech Enhancemennt 1-channel BiLSTM Model
-trained on the 28-speaker version of Voicebank+Demand
-(Sampling rate: 16kHz)</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>targets</code></strong> : <code>str</code></dt>
-<dd>select the targets for the source to be separated.
-a list including: ['speech', 'noise'].
-If you don't pick them all, you probably want to
-activate the <code>residual=True</code> option.
-Defaults to all available targets per model.</dd>
-<dt><strong><code>pretrained</code></strong> : <code>bool</code></dt>
-<dd>If True, returns a model pre-trained on MUSDB18-HQ</dd>
-<dt><strong><code>residual</code></strong> : <code>bool</code></dt>
-<dd>if True, a "garbage" target is created</dd>
-<dt><strong><code>niter</code></strong> : <code>int</code></dt>
-<dd>the number of post-processingiterations, defaults to 0</dd>
-<dt><strong><code>device</code></strong> : <code>str</code></dt>
-<dd>selects device to be used for inference</dd>
-<dt><strong><code>filterbank</code></strong> : <code>str</code></dt>
-<dd>filterbank implementation method.
-Supported are <code>['torch', 'asteroid']</code>. <code>torch</code> is about 30% faster
-compared to <code>asteroid</code> on large FFT sizes such as 4096. However,
-asteroids stft can be exported to onnx, which makes is practical
-for deployment.</dd>
-</dl>
-<h2 id="reference">Reference</h2>
-<p>Uhlich, Stefan, & Mitsufuji, Yuki. (2020).
-Open-Unmix for Speech Enhancement (UMX SE).
-Zenodo. <a href="http://doi.org/10.5281/zenodo.3786908">http://doi.org/10.5281/zenodo.3786908</a></p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/__init__.py#L46-L95" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def umxse(
- targets=None,
- residual=False,
- niter=1,
- device="cpu",
- pretrained=True,
- filterbank="torch",
-):
- """
- Open Unmix Speech Enhancemennt 1-channel BiLSTM Model
- trained on the 28-speaker version of Voicebank+Demand
- (Sampling rate: 16kHz)
-
- Args:
- targets (str): select the targets for the source to be separated.
- a list including: ['speech', 'noise'].
- If you don't pick them all, you probably want to
- activate the `residual=True` option.
- Defaults to all available targets per model.
- pretrained (bool): If True, returns a model pre-trained on MUSDB18-HQ
- residual (bool): if True, a "garbage" target is created
- niter (int): the number of post-processingiterations, defaults to 0
- device (str): selects device to be used for inference
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
-
- Reference:
- Uhlich, Stefan, & Mitsufuji, Yuki. (2020).
- Open-Unmix for Speech Enhancement (UMX SE).
- Zenodo. http://doi.org/10.5281/zenodo.3786908
- """
- from .model import Separator
-
- target_models = umxse_spec(targets=targets, device=device, pretrained=pretrained)
-
- separator = Separator(
- target_models=target_models,
- niter=niter,
- residual=residual,
- n_fft=1024,
- n_hop=512,
- nb_channels=1,
- sample_rate=16000.0,
- filterbank=filterbank,
- ).to(device)
-
- return separator</code></pre>
-</details>
-</dd>
-<dt id="openunmix.umxse_spec"><code class="name flex">
-<span>def <span class="ident">umxse_spec</span></span>(<span>targets=None, device='cpu', pretrained=True)</span>
-</code></dt>
-<dd>
-<div class="desc"></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/__init__.py#L12-L43" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def umxse_spec(targets=None, device="cpu", pretrained=True):
- target_urls = {
- "speech": "https://zenodo.org/api/files/765b45a3-c70d-48a6-936b-09a7989c349a/speech_f5e0d9f9.pth",
- "noise": "https://zenodo.org/api/files/765b45a3-c70d-48a6-936b-09a7989c349a/noise_04a6fc2d.pth",
- }
-
- from .model import OpenUnmix
-
- if targets is None:
- targets = ["speech", "noise"]
-
- # determine the maximum bin count for a 16khz bandwidth model
- max_bin = utils.bandwidth_to_max_bin(rate=16000.0, n_fft=1024, bandwidth=16000)
-
- # load open unmix models speech enhancement models
- target_models = {}
- for target in targets:
- target_unmix = OpenUnmix(
- nb_bins=1024 // 2 + 1, nb_channels=1, hidden_size=256, max_bin=max_bin
- )
-
- # enable centering of stft to minimize reconstruction error
- if pretrained:
- state_dict = torch.hub.load_state_dict_from_url(
- target_urls[target], map_location=device
- )
- target_unmix.load_state_dict(state_dict, strict=False)
- target_unmix.eval()
-
- target_unmix.to(device)
- target_models[target] = target_unmix
- return target_models</code></pre>
-</details>
-</dd>
-</dl>
-</section>
-<section>
-</section>
-</article>
-<nav id="sidebar">
-<h1>Index</h1>
-<div class="toc">
-<ul></ul>
-</div>
-<ul id="index">
-<li><h3><a href="#header-submodules">Sub-modules</a></h3>
-<ul>
-<li><code><a title="openunmix.cli" href="cli.html">openunmix.cli</a></code></li>
-<li><code><a title="openunmix.data" href="data.html">openunmix.data</a></code></li>
-<li><code><a title="openunmix.evaluate" href="evaluate.html">openunmix.evaluate</a></code></li>
-<li><code><a title="openunmix.filtering" href="filtering.html">openunmix.filtering</a></code></li>
-<li><code><a title="openunmix.model" href="model.html">openunmix.model</a></code></li>
-<li><code><a title="openunmix.predict" href="predict.html">openunmix.predict</a></code></li>
-<li><code><a title="openunmix.transforms" href="transforms.html">openunmix.transforms</a></code></li>
-<li><code><a title="openunmix.utils" href="utils.html">openunmix.utils</a></code></li>
-</ul>
-</li>
-<li><h3><a href="#header-functions">Functions</a></h3>
-<ul class="two-column">
-<li><code><a title="openunmix.umx" href="#openunmix.umx">umx</a></code></li>
-<li><code><a title="openunmix.umx_spec" href="#openunmix.umx_spec">umx_spec</a></code></li>
-<li><code><a title="openunmix.umxhq" href="#openunmix.umxhq">umxhq</a></code></li>
-<li><code><a title="openunmix.umxhq_spec" href="#openunmix.umxhq_spec">umxhq_spec</a></code></li>
-<li><code><a title="openunmix.umxse" href="#openunmix.umxse">umxse</a></code></li>
-<li><code><a title="openunmix.umxse_spec" href="#openunmix.umxse_spec">umxse_spec</a></code></li>
-</ul>
-</li>
-</ul>
-</nav>
-</main>
-<footer id="footer">
-<p>Generated by <a href="https://pdoc3.github.io/pdoc"><cite>pdoc</cite> 0.9.2</a>.</p>
-</footer>
-</body>
-</html>
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/inference.md b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/inference.md
deleted file mode 100644
index 0a82b6fa2c369aaa6579bfd11a25c80a1c9f45c4..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/inference.md
+++ /dev/null
@@ -1,57 +0,0 @@
-# Performing separation
-
-## Interfacing using the command line
-
-The primary interface to separate files is the command line. To separate a mixture file into the four stems you can just run
-
-```bash
-umx input_file.wav
-```
-
-Note that we support all files that can be read by torchaudio, depending on the set backend (either `soundfile` (libsndfile) or `sox`).
-For training, we set the default to `soundfile` as it is faster than `sox`. However for inference users might prefer `mp3` decoding capabilities.
-The separation can be controlled with additional parameters that influence the performance of the separation.
-
-| Command line Argument | Description | Default |
-|----------------------------|---------------------------------------------------------------------------------|-----------------|
-|`--start <float>` | set start in seconds to reduce the duration of the audio being loaded | `0.0` |
-|`--duration <float>` | set duration in seconds to reduce length of the audio being loaded. Negative values will make the full audio being loaded | `-1.0` |
-|`--model <str>` | path or string of model name to select either a self pre-trained model or a model loaded from `torchhub`. | |
-| `--targets list(str)` | Targets to be used for separation. For each target a model file with with same name is required. | `['vocals', 'drums', 'bass', 'other']` |
-| `--niter <int>` | Number of EM steps for refining initial estimates in a post-processing stage. `--niter 0` skips this step altogether (and thus makes separation significantly faster) More iterations can get better interference reduction at the price of more artifacts. | `1` |
-| `--residual` | computes a residual target, for custom separation scenarios when not all targets are available (at the expense of slightly less performance). E.g vocal/accompaniment can be performed with `--targets vocals --residual`. | not set |
-| `--softmask` | if activated, then the initial estimates for the sources will be obtained through a ratio mask of the mixture STFT, and not by using the default behavior of reconstructing waveforms by using the mixture phase. | not set |
-| `--wiener-win-len <int>` | Number of frames on which to apply filtering independently | `300` |
-| `--audio-backend <str>` | choose audio loading backend, either `sox_io`, `soundfile` or `stempeg` (which needs additional installation requirements) | [torchaudio default](https://pytorch.org/audio/stable/backend.html) |
-| `--aggregate <str>` | if provided, must be a string containing a valid expression for a dictionary, with keys as output target names, and values a list of targets that are used to build it. For instance: `{ "vocals": ["vocals"], "accompaniment": ["drums", "bass", "other"]}` | `None` |
-| `--filterbank <str>` | filterbank implementation method. Supported: `['torch', 'asteroid']`. While `torch` is ~30% faster compared to `asteroid` on large FFT sizes such as 4096, asteroids STFT maybe be easier to be exported for deployment. | `torch` |
-
-## Interfacing from python
-
-At the core of the process of separating audio is the `Separator` Module which
-takes a numpy audio array or a `torch.Tensor` as input (the mixture) and separates into `targets` stems.
-Note, that for each target a separate model will be loaded. E.g. for `umx` and `umxhq` the supported targets are
-`['vocals', 'drums', 'bass', 'other']`. The models have to be passed to the separators `target_models` parameter.
-
-Both models `umx`, `umxhq`, `umxl` and `umxse` are downloaded automatically.
-
-Here is an example for constructor for the `Separator` takes the following arguments, with suggested default values:
-
-```python
-seperator = openunmix.Separator(
- target_models: dict,
- niter: int = 0,
- softmask: bool = False,
- residual: bool = False,
- sample_rate: float = 44100.0,
- n_fft: int = 4096,
- n_hop: int = 1024,
- nb_channels: int = 2,
- wiener_win_len: Optional[int] = 300,
- filterbank: str = 'torch'
-):
-```
-
-When passing
-
-> __Caution__ `training` using the EM algorithm (`niter>0`) is not supported. Only plain post-processing is supported right now for gradient computation. This is because the performance overhead of avoiding all the in-places operations is too large.
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/model.html b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/model.html
deleted file mode 100644
index 67d43fb7a9e9bf2823f7ba2baab39c3f3fb12c63..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/model.html
+++ /dev/null
@@ -1,1150 +0,0 @@
-<!doctype html>
-<html lang="en">
-<head>
-<meta charset="utf-8">
-<meta name="viewport" content="width=device-width, initial-scale=1, minimum-scale=1" />
-<meta name="generator" content="pdoc 0.9.2" />
-<title>openunmix.model API documentation</title>
-<meta name="description" content="" />
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/sanitize.min.css" integrity="sha256-PK9q560IAAa6WVRRh76LtCaI8pjTJ2z11v0miyNNjrs=" crossorigin>
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/typography.min.css" integrity="sha256-7l/o7C8jubJiy74VsKTidCy1yBkRtiUGbVkYBylBqUg=" crossorigin>
-<link rel="stylesheet preload" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/styles/github.min.css" crossorigin>
-<style>:root{--highlight-color:#fe9}.flex{display:flex !important}body{line-height:1.5em}#content{padding:20px}#sidebar{padding:30px;overflow:hidden}#sidebar > *:last-child{margin-bottom:2cm}.http-server-breadcrumbs{font-size:130%;margin:0 0 15px 0}#footer{font-size:.75em;padding:5px 30px;border-top:1px solid #ddd;text-align:right}#footer p{margin:0 0 0 1em;display:inline-block}#footer p:last-child{margin-right:30px}h1,h2,h3,h4,h5{font-weight:300}h1{font-size:2.5em;line-height:1.1em}h2{font-size:1.75em;margin:1em 0 .50em 0}h3{font-size:1.4em;margin:25px 0 10px 0}h4{margin:0;font-size:105%}h1:target,h2:target,h3:target,h4:target,h5:target,h6:target{background:var(--highlight-color);padding:.2em 0}a{color:#058;text-decoration:none;transition:color .3s ease-in-out}a:hover{color:#e82}.title code{font-weight:bold}h2[id^="header-"]{margin-top:2em}.ident{color:#900}pre code{background:#f8f8f8;font-size:.8em;line-height:1.4em}code{background:#f2f2f1;padding:1px 4px;overflow-wrap:break-word}h1 code{background:transparent}pre{background:#f8f8f8;border:0;border-top:1px solid #ccc;border-bottom:1px solid #ccc;margin:1em 0;padding:1ex}#http-server-module-list{display:flex;flex-flow:column}#http-server-module-list div{display:flex}#http-server-module-list dt{min-width:10%}#http-server-module-list p{margin-top:0}.toc ul,#index{list-style-type:none;margin:0;padding:0}#index code{background:transparent}#index h3{border-bottom:1px solid #ddd}#index ul{padding:0}#index h4{margin-top:.6em;font-weight:bold}@media (min-width:200ex){#index .two-column{column-count:2}}@media (min-width:300ex){#index .two-column{column-count:3}}dl{margin-bottom:2em}dl dl:last-child{margin-bottom:4em}dd{margin:0 0 1em 3em}#header-classes + dl > dd{margin-bottom:3em}dd dd{margin-left:2em}dd p{margin:10px 0}.name{background:#eee;font-weight:bold;font-size:.85em;padding:5px 10px;display:inline-block;min-width:40%}.name:hover{background:#e0e0e0}dt:target .name{background:var(--highlight-color)}.name > span:first-child{white-space:nowrap}.name.class > span:nth-child(2){margin-left:.4em}.inherited{color:#999;border-left:5px solid #eee;padding-left:1em}.inheritance em{font-style:normal;font-weight:bold}.desc h2{font-weight:400;font-size:1.25em}.desc h3{font-size:1em}.desc dt code{background:inherit}.source summary,.git-link-div{color:#666;text-align:right;font-weight:400;font-size:.8em;text-transform:uppercase}.source summary > *{white-space:nowrap;cursor:pointer}.git-link{color:inherit;margin-left:1em}.source pre{max-height:500px;overflow:auto;margin:0}.source pre code{font-size:12px;overflow:visible}.hlist{list-style:none}.hlist li{display:inline}.hlist li:after{content:',\2002'}.hlist li:last-child:after{content:none}.hlist .hlist{display:inline;padding-left:1em}img{max-width:100%}td{padding:0 .5em}.admonition{padding:.1em .5em;margin-bottom:1em}.admonition-title{font-weight:bold}.admonition.note,.admonition.info,.admonition.important{background:#aef}.admonition.todo,.admonition.versionadded,.admonition.tip,.admonition.hint{background:#dfd}.admonition.warning,.admonition.versionchanged,.admonition.deprecated{background:#fd4}.admonition.error,.admonition.danger,.admonition.caution{background:lightpink}</style>
-<style media="screen and (min-width: 700px)">@media screen and (min-width:700px){#sidebar{width:30%;height:100vh;overflow:auto;position:sticky;top:0}#content{width:70%;max-width:100ch;padding:3em 4em;border-left:1px solid #ddd}pre code{font-size:1em}.item .name{font-size:1em}main{display:flex;flex-direction:row-reverse;justify-content:flex-end}.toc ul ul,#index ul{padding-left:1.5em}.toc > ul > li{margin-top:.5em}}</style>
-<style media="print">@media print{#sidebar h1{page-break-before:always}.source{display:none}}@media print{*{background:transparent !important;color:#000 !important;box-shadow:none !important;text-shadow:none !important}a[href]:after{content:" (" attr(href) ")";font-size:90%}a[href][title]:after{content:none}abbr[title]:after{content:" (" attr(title) ")"}.ir a:after,a[href^="javascript:"]:after,a[href^="#"]:after{content:""}pre,blockquote{border:1px solid #999;page-break-inside:avoid}thead{display:table-header-group}tr,img{page-break-inside:avoid}img{max-width:100% !important}@page{margin:0.5cm}p,h2,h3{orphans:3;widows:3}h1,h2,h3,h4,h5,h6{page-break-after:avoid}}</style>
-<script async src="https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.7/latest.js?config=TeX-AMS_CHTML" integrity="sha256-kZafAc6mZvK3W3v1pHOcUix30OHQN6pU/NO2oFkqZVw=" crossorigin></script>
-<script defer src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/highlight.min.js" integrity="sha256-Uv3H6lx7dJmRfRvH8TH6kJD1TSK1aFcwgx+mdg3epi8=" crossorigin></script>
-<script>window.addEventListener('DOMContentLoaded', () => hljs.initHighlighting())</script>
-</head>
-<body>
-<main>
-<article id="content">
-<header>
-<h1 class="title">Module <code>openunmix.model</code></h1>
-</header>
-<section id="section-intro">
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/model.py#L0-L345" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">from typing import Optional
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from torch import Tensor
-from torch.nn import LSTM, BatchNorm1d, Linear, Parameter
-from .filtering import wiener
-from .transforms import make_filterbanks, ComplexNorm
-
-
-class OpenUnmix(nn.Module):
- """OpenUnmix Core spectrogram based separation module.
-
- Args:
- nb_bins (int): Number of input time-frequency bins (Default: `4096`).
- nb_channels (int): Number of input audio channels (Default: `2`).
- hidden_size (int): Size for bottleneck layers (Default: `512`).
- nb_layers (int): Number of Bi-LSTM layers (Default: `3`).
- unidirectional (bool): Use causal model useful for realtime purpose.
- (Default `False`)
- input_mean (ndarray or None): global data mean of shape `(nb_bins, )`.
- Defaults to zeros(nb_bins)
- input_scale (ndarray or None): global data mean of shape `(nb_bins, )`.
- Defaults to ones(nb_bins)
- max_bin (int or None): Internal frequency bin threshold to
- reduce high frequency content. Defaults to `None` which results
- in `nb_bins`
- """
-
- def __init__(
- self,
- nb_bins=4096,
- nb_channels=2,
- hidden_size=512,
- nb_layers=3,
- unidirectional=False,
- input_mean=None,
- input_scale=None,
- max_bin=None,
- ):
- super(OpenUnmix, self).__init__()
-
- self.nb_output_bins = nb_bins
- if max_bin:
- self.nb_bins = max_bin
- else:
- self.nb_bins = self.nb_output_bins
-
- self.hidden_size = hidden_size
-
- self.fc1 = Linear(self.nb_bins * nb_channels, hidden_size, bias=False)
-
- self.bn1 = BatchNorm1d(hidden_size)
-
- if unidirectional:
- lstm_hidden_size = hidden_size
- else:
- lstm_hidden_size = hidden_size // 2
-
- self.lstm = LSTM(
- input_size=hidden_size,
- hidden_size=lstm_hidden_size,
- num_layers=nb_layers,
- bidirectional=not unidirectional,
- batch_first=False,
- dropout=0.4 if nb_layers > 1 else 0,
- )
-
- fc2_hiddensize = hidden_size * 2
- self.fc2 = Linear(in_features=fc2_hiddensize, out_features=hidden_size, bias=False)
-
- self.bn2 = BatchNorm1d(hidden_size)
-
- self.fc3 = Linear(
- in_features=hidden_size,
- out_features=self.nb_output_bins * nb_channels,
- bias=False,
- )
-
- self.bn3 = BatchNorm1d(self.nb_output_bins * nb_channels)
-
- if input_mean is not None:
- input_mean = torch.from_numpy(-input_mean[: self.nb_bins]).float()
- else:
- input_mean = torch.zeros(self.nb_bins)
-
- if input_scale is not None:
- input_scale = torch.from_numpy(1.0 / input_scale[: self.nb_bins]).float()
- else:
- input_scale = torch.ones(self.nb_bins)
-
- self.input_mean = Parameter(input_mean)
- self.input_scale = Parameter(input_scale)
-
- self.output_scale = Parameter(torch.ones(self.nb_output_bins).float())
- self.output_mean = Parameter(torch.ones(self.nb_output_bins).float())
-
- def freeze(self):
- # set all parameters as not requiring gradient, more RAM-efficient
- # at test time
- for p in self.parameters():
- p.requires_grad = False
- self.eval()
-
- def forward(self, x: Tensor) -> Tensor:
- """
- Args:
- x: input spectrogram of shape
- `(nb_samples, nb_channels, nb_bins, nb_frames)`
-
- Returns:
- Tensor: filtered spectrogram of shape
- `(nb_samples, nb_channels, nb_bins, nb_frames)`
- """
-
- # permute so that batch is last for lstm
- x = x.permute(3, 0, 1, 2)
- # get current spectrogram shape
- nb_frames, nb_samples, nb_channels, nb_bins = x.data.shape
-
- mix = x.detach().clone()
-
- # crop
- x = x[..., : self.nb_bins]
- # shift and scale input to mean=0 std=1 (across all bins)
- x += self.input_mean
- x *= self.input_scale
-
- # to (nb_frames*nb_samples, nb_channels*nb_bins)
- # and encode to (nb_frames*nb_samples, hidden_size)
- x = self.fc1(x.reshape(-1, nb_channels * self.nb_bins))
- # normalize every instance in a batch
- x = self.bn1(x)
- x = x.reshape(nb_frames, nb_samples, self.hidden_size)
- # squash range ot [-1, 1]
- x = torch.tanh(x)
-
- # apply 3-layers of stacked LSTM
- lstm_out = self.lstm(x)
-
- # lstm skip connection
- x = torch.cat([x, lstm_out[0]], -1)
-
- # first dense stage + batch norm
- x = self.fc2(x.reshape(-1, x.shape[-1]))
- x = self.bn2(x)
-
- x = F.relu(x)
-
- # second dense stage + layer norm
- x = self.fc3(x)
- x = self.bn3(x)
-
- # reshape back to original dim
- x = x.reshape(nb_frames, nb_samples, nb_channels, self.nb_output_bins)
-
- # apply output scaling
- x *= self.output_scale
- x += self.output_mean
-
- # since our output is non-negative, we can apply RELU
- x = F.relu(x) * mix
- # permute back to (nb_samples, nb_channels, nb_bins, nb_frames)
- return x.permute(1, 2, 3, 0)
-
-
-class Separator(nn.Module):
- """
- Separator class to encapsulate all the stereo filtering
- as a torch Module, to enable end-to-end learning.
-
- Args:
- targets (dict of str: nn.Module): dictionary of target models
- the spectrogram models to be used by the Separator.
- niter (int): Number of EM steps for refining initial estimates in a
- post-processing stage. Zeroed if only one target is estimated.
- defaults to `1`.
- residual (bool): adds an additional residual target, obtained by
- subtracting the other estimated targets from the mixture,
- before any potential EM post-processing.
- Defaults to `False`.
- wiener_win_len (int or None): The size of the excerpts
- (number of frames) on which to apply filtering
- independently. This means assuming time varying stereo models and
- localization of sources.
- None means not batching but using the whole signal. It comes at the
- price of a much larger memory usage.
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
- """
-
- def __init__(
- self,
- target_models: dict,
- niter: int = 0,
- softmask: bool = False,
- residual: bool = False,
- sample_rate: float = 44100.0,
- n_fft: int = 4096,
- n_hop: int = 1024,
- nb_channels: int = 2,
- wiener_win_len: Optional[int] = 300,
- filterbank: str = "torch",
- ):
- super(Separator, self).__init__()
-
- # saving parameters
- self.niter = niter
- self.residual = residual
- self.softmask = softmask
- self.wiener_win_len = wiener_win_len
-
- self.stft, self.istft = make_filterbanks(
- n_fft=n_fft,
- n_hop=n_hop,
- center=True,
- method=filterbank,
- sample_rate=sample_rate,
- )
- self.complexnorm = ComplexNorm(mono=nb_channels == 1)
-
- # registering the targets models
- self.target_models = nn.ModuleDict(target_models)
- # adding till https://github.com/pytorch/pytorch/issues/38963
- self.nb_targets = len(self.target_models)
- # get the sample_rate as the sample_rate of the first model
- # (tacitly assume it's the same for all targets)
- self.register_buffer("sample_rate", torch.as_tensor(sample_rate))
-
- def freeze(self):
- # set all parameters as not requiring gradient, more RAM-efficient
- # at test time
- for p in self.parameters():
- p.requires_grad = False
- self.eval()
-
- def forward(self, audio: Tensor) -> Tensor:
- """Performing the separation on audio input
-
- Args:
- audio (Tensor): [shape=(nb_samples, nb_channels, nb_timesteps)]
- mixture audio waveform
-
- Returns:
- Tensor: stacked tensor of separated waveforms
- shape `(nb_samples, nb_targets, nb_channels, nb_timesteps)`
- """
-
- nb_sources = self.nb_targets
- nb_samples = audio.shape[0]
-
- # getting the STFT of mix:
- # (nb_samples, nb_channels, nb_bins, nb_frames, 2)
- mix_stft = self.stft(audio)
- X = self.complexnorm(mix_stft)
-
- # initializing spectrograms variable
- spectrograms = torch.zeros(X.shape + (nb_sources,), dtype=audio.dtype, device=X.device)
-
- for j, (target_name, target_module) in enumerate(self.target_models.items()):
- # apply current model to get the source spectrogram
- target_spectrogram = target_module(X.detach().clone())
- spectrograms[..., j] = target_spectrogram
-
- # transposing it as
- # (nb_samples, nb_frames, nb_bins,{1,nb_channels}, nb_sources)
- spectrograms = spectrograms.permute(0, 3, 2, 1, 4)
-
- # rearranging it into:
- # (nb_samples, nb_frames, nb_bins, nb_channels, 2) to feed
- # into filtering methods
- mix_stft = mix_stft.permute(0, 3, 2, 1, 4)
-
- # create an additional target if we need to build a residual
- if self.residual:
- # we add an additional target
- nb_sources += 1
-
- if nb_sources == 1 and self.niter > 0:
- raise Exception(
- "Cannot use EM if only one target is estimated."
- "Provide two targets or create an additional "
- "one with `--residual`"
- )
-
- nb_frames = spectrograms.shape[1]
- targets_stft = torch.zeros(
- mix_stft.shape + (nb_sources,), dtype=audio.dtype, device=mix_stft.device
- )
- for sample in range(nb_samples):
- pos = 0
- if self.wiener_win_len:
- wiener_win_len = self.wiener_win_len
- else:
- wiener_win_len = nb_frames
- while pos < nb_frames:
- cur_frame = torch.arange(pos, min(nb_frames, pos + wiener_win_len))
- pos = int(cur_frame[-1]) + 1
-
- targets_stft[sample, cur_frame] = wiener(
- spectrograms[sample, cur_frame],
- mix_stft[sample, cur_frame],
- self.niter,
- softmask=self.softmask,
- residual=self.residual,
- )
-
- # getting to (nb_samples, nb_targets, channel, fft_size, n_frames, 2)
- targets_stft = targets_stft.permute(0, 5, 3, 2, 1, 4).contiguous()
-
- # inverse STFT
- estimates = self.istft(targets_stft, length=audio.shape[2])
-
- return estimates
-
- def to_dict(self, estimates: Tensor, aggregate_dict: Optional[dict] = None) -> dict:
- """Convert estimates as stacked tensor to dictionary
-
- Args:
- estimates (Tensor): separated targets of shape
- (nb_samples, nb_targets, nb_channels, nb_timesteps)
- aggregate_dict (dict or None)
-
- Returns:
- (dict of str: Tensor):
- """
- estimates_dict = {}
- for k, target in enumerate(self.target_models):
- estimates_dict[target] = estimates[:, k, ...]
-
- # in the case of residual, we added another source
- if self.residual:
- estimates_dict["residual"] = estimates[:, -1, ...]
-
- if aggregate_dict is not None:
- new_estimates = {}
- for key in aggregate_dict:
- new_estimates[key] = torch.tensor(0.0)
- for target in aggregate_dict[key]:
- new_estimates[key] = new_estimates[key] + estimates_dict[target]
- estimates_dict = new_estimates
- return estimates_dict</code></pre>
-</details>
-</section>
-<section>
-</section>
-<section>
-</section>
-<section>
-</section>
-<section>
-<h2 class="section-title" id="header-classes">Classes</h2>
-<dl>
-<dt id="openunmix.model.OpenUnmix"><code class="flex name class">
-<span>class <span class="ident">OpenUnmix</span></span>
-<span>(</span><span>nb_bins=4096, nb_channels=2, hidden_size=512, nb_layers=3, unidirectional=False, input_mean=None, input_scale=None, max_bin=None)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>OpenUnmix Core spectrogram based separation module.</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>nb_bins</code></strong> : <code>int</code></dt>
-<dd>Number of input time-frequency bins (Default: <code>4096</code>).</dd>
-<dt><strong><code>nb_channels</code></strong> : <code>int</code></dt>
-<dd>Number of input audio channels (Default: <code>2</code>).</dd>
-<dt><strong><code>hidden_size</code></strong> : <code>int</code></dt>
-<dd>Size for bottleneck layers (Default: <code>512</code>).</dd>
-<dt><strong><code>nb_layers</code></strong> : <code>int</code></dt>
-<dd>Number of Bi-LSTM layers (Default: <code>3</code>).</dd>
-<dt><strong><code>unidirectional</code></strong> : <code>bool</code></dt>
-<dd>Use causal model useful for realtime purpose.
-(Default <code>False</code>)</dd>
-<dt><strong><code>input_mean</code></strong> : <code>ndarray</code> or <code>None</code></dt>
-<dd>global data mean of shape <code>(nb_bins, )</code>.
-Defaults to zeros(nb_bins)</dd>
-<dt><strong><code>input_scale</code></strong> : <code>ndarray</code> or <code>None</code></dt>
-<dd>global data mean of shape <code>(nb_bins, )</code>.
-Defaults to ones(nb_bins)</dd>
-<dt><strong><code>max_bin</code></strong> : <code>int</code> or <code>None</code></dt>
-<dd>Internal frequency bin threshold to
-reduce high frequency content. Defaults to <code>None</code> which results
-in <code>nb_bins</code></dd>
-</dl>
-<p>Initializes internal Module state, shared by both nn.Module and ScriptModule.</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/model.py#L12-L165" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class OpenUnmix(nn.Module):
- """OpenUnmix Core spectrogram based separation module.
-
- Args:
- nb_bins (int): Number of input time-frequency bins (Default: `4096`).
- nb_channels (int): Number of input audio channels (Default: `2`).
- hidden_size (int): Size for bottleneck layers (Default: `512`).
- nb_layers (int): Number of Bi-LSTM layers (Default: `3`).
- unidirectional (bool): Use causal model useful for realtime purpose.
- (Default `False`)
- input_mean (ndarray or None): global data mean of shape `(nb_bins, )`.
- Defaults to zeros(nb_bins)
- input_scale (ndarray or None): global data mean of shape `(nb_bins, )`.
- Defaults to ones(nb_bins)
- max_bin (int or None): Internal frequency bin threshold to
- reduce high frequency content. Defaults to `None` which results
- in `nb_bins`
- """
-
- def __init__(
- self,
- nb_bins=4096,
- nb_channels=2,
- hidden_size=512,
- nb_layers=3,
- unidirectional=False,
- input_mean=None,
- input_scale=None,
- max_bin=None,
- ):
- super(OpenUnmix, self).__init__()
-
- self.nb_output_bins = nb_bins
- if max_bin:
- self.nb_bins = max_bin
- else:
- self.nb_bins = self.nb_output_bins
-
- self.hidden_size = hidden_size
-
- self.fc1 = Linear(self.nb_bins * nb_channels, hidden_size, bias=False)
-
- self.bn1 = BatchNorm1d(hidden_size)
-
- if unidirectional:
- lstm_hidden_size = hidden_size
- else:
- lstm_hidden_size = hidden_size // 2
-
- self.lstm = LSTM(
- input_size=hidden_size,
- hidden_size=lstm_hidden_size,
- num_layers=nb_layers,
- bidirectional=not unidirectional,
- batch_first=False,
- dropout=0.4 if nb_layers > 1 else 0,
- )
-
- fc2_hiddensize = hidden_size * 2
- self.fc2 = Linear(in_features=fc2_hiddensize, out_features=hidden_size, bias=False)
-
- self.bn2 = BatchNorm1d(hidden_size)
-
- self.fc3 = Linear(
- in_features=hidden_size,
- out_features=self.nb_output_bins * nb_channels,
- bias=False,
- )
-
- self.bn3 = BatchNorm1d(self.nb_output_bins * nb_channels)
-
- if input_mean is not None:
- input_mean = torch.from_numpy(-input_mean[: self.nb_bins]).float()
- else:
- input_mean = torch.zeros(self.nb_bins)
-
- if input_scale is not None:
- input_scale = torch.from_numpy(1.0 / input_scale[: self.nb_bins]).float()
- else:
- input_scale = torch.ones(self.nb_bins)
-
- self.input_mean = Parameter(input_mean)
- self.input_scale = Parameter(input_scale)
-
- self.output_scale = Parameter(torch.ones(self.nb_output_bins).float())
- self.output_mean = Parameter(torch.ones(self.nb_output_bins).float())
-
- def freeze(self):
- # set all parameters as not requiring gradient, more RAM-efficient
- # at test time
- for p in self.parameters():
- p.requires_grad = False
- self.eval()
-
- def forward(self, x: Tensor) -> Tensor:
- """
- Args:
- x: input spectrogram of shape
- `(nb_samples, nb_channels, nb_bins, nb_frames)`
-
- Returns:
- Tensor: filtered spectrogram of shape
- `(nb_samples, nb_channels, nb_bins, nb_frames)`
- """
-
- # permute so that batch is last for lstm
- x = x.permute(3, 0, 1, 2)
- # get current spectrogram shape
- nb_frames, nb_samples, nb_channels, nb_bins = x.data.shape
-
- mix = x.detach().clone()
-
- # crop
- x = x[..., : self.nb_bins]
- # shift and scale input to mean=0 std=1 (across all bins)
- x += self.input_mean
- x *= self.input_scale
-
- # to (nb_frames*nb_samples, nb_channels*nb_bins)
- # and encode to (nb_frames*nb_samples, hidden_size)
- x = self.fc1(x.reshape(-1, nb_channels * self.nb_bins))
- # normalize every instance in a batch
- x = self.bn1(x)
- x = x.reshape(nb_frames, nb_samples, self.hidden_size)
- # squash range ot [-1, 1]
- x = torch.tanh(x)
-
- # apply 3-layers of stacked LSTM
- lstm_out = self.lstm(x)
-
- # lstm skip connection
- x = torch.cat([x, lstm_out[0]], -1)
-
- # first dense stage + batch norm
- x = self.fc2(x.reshape(-1, x.shape[-1]))
- x = self.bn2(x)
-
- x = F.relu(x)
-
- # second dense stage + layer norm
- x = self.fc3(x)
- x = self.bn3(x)
-
- # reshape back to original dim
- x = x.reshape(nb_frames, nb_samples, nb_channels, self.nb_output_bins)
-
- # apply output scaling
- x *= self.output_scale
- x += self.output_mean
-
- # since our output is non-negative, we can apply RELU
- x = F.relu(x) * mix
- # permute back to (nb_samples, nb_channels, nb_bins, nb_frames)
- return x.permute(1, 2, 3, 0)</code></pre>
-</details>
-<h3>Ancestors</h3>
-<ul class="hlist">
-<li>torch.nn.modules.module.Module</li>
-</ul>
-<h3>Class variables</h3>
-<dl>
-<dt id="openunmix.model.OpenUnmix.dump_patches"><code class="name">var <span class="ident">dump_patches</span> :Â bool</code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-<dt id="openunmix.model.OpenUnmix.training"><code class="name">var <span class="ident">training</span> :Â bool</code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-</dl>
-<h3>Methods</h3>
-<dl>
-<dt id="openunmix.model.OpenUnmix.forward"><code class="name flex">
-<span>def <span class="ident">forward</span></span>(<span>self, x: torch.Tensor) ‑> torch.Tensor</span>
-</code></dt>
-<dd>
-<div class="desc"><h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>x</code></strong></dt>
-<dd>input spectrogram of shape
-<code>(nb_samples, nb_channels, nb_bins, nb_frames)</code></dd>
-</dl>
-<h2 id="returns">Returns</h2>
-<dl>
-<dt><code>Tensor</code></dt>
-<dd>filtered spectrogram of shape
-<code>(nb_samples, nb_channels, nb_bins, nb_frames)</code></dd>
-</dl></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/model.py#L106-L165" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def forward(self, x: Tensor) -> Tensor:
- """
- Args:
- x: input spectrogram of shape
- `(nb_samples, nb_channels, nb_bins, nb_frames)`
-
- Returns:
- Tensor: filtered spectrogram of shape
- `(nb_samples, nb_channels, nb_bins, nb_frames)`
- """
-
- # permute so that batch is last for lstm
- x = x.permute(3, 0, 1, 2)
- # get current spectrogram shape
- nb_frames, nb_samples, nb_channels, nb_bins = x.data.shape
-
- mix = x.detach().clone()
-
- # crop
- x = x[..., : self.nb_bins]
- # shift and scale input to mean=0 std=1 (across all bins)
- x += self.input_mean
- x *= self.input_scale
-
- # to (nb_frames*nb_samples, nb_channels*nb_bins)
- # and encode to (nb_frames*nb_samples, hidden_size)
- x = self.fc1(x.reshape(-1, nb_channels * self.nb_bins))
- # normalize every instance in a batch
- x = self.bn1(x)
- x = x.reshape(nb_frames, nb_samples, self.hidden_size)
- # squash range ot [-1, 1]
- x = torch.tanh(x)
-
- # apply 3-layers of stacked LSTM
- lstm_out = self.lstm(x)
-
- # lstm skip connection
- x = torch.cat([x, lstm_out[0]], -1)
-
- # first dense stage + batch norm
- x = self.fc2(x.reshape(-1, x.shape[-1]))
- x = self.bn2(x)
-
- x = F.relu(x)
-
- # second dense stage + layer norm
- x = self.fc3(x)
- x = self.bn3(x)
-
- # reshape back to original dim
- x = x.reshape(nb_frames, nb_samples, nb_channels, self.nb_output_bins)
-
- # apply output scaling
- x *= self.output_scale
- x += self.output_mean
-
- # since our output is non-negative, we can apply RELU
- x = F.relu(x) * mix
- # permute back to (nb_samples, nb_channels, nb_bins, nb_frames)
- return x.permute(1, 2, 3, 0)</code></pre>
-</details>
-</dd>
-<dt id="openunmix.model.OpenUnmix.freeze"><code class="name flex">
-<span>def <span class="ident">freeze</span></span>(<span>self)</span>
-</code></dt>
-<dd>
-<div class="desc"></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/model.py#L99-L104" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def freeze(self):
- # set all parameters as not requiring gradient, more RAM-efficient
- # at test time
- for p in self.parameters():
- p.requires_grad = False
- self.eval()</code></pre>
-</details>
-</dd>
-</dl>
-</dd>
-<dt id="openunmix.model.Separator"><code class="flex name class">
-<span>class <span class="ident">Separator</span></span>
-<span>(</span><span>target_models: dict, niter: int = 0, softmask: bool = False, residual: bool = False, sample_rate: float = 44100.0, n_fft: int = 4096, n_hop: int = 1024, nb_channels: int = 2, wiener_win_len: Union[int, NoneType] = 300, filterbank: str = 'torch')</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Separator class to encapsulate all the stereo filtering
-as a torch Module, to enable end-to-end learning.</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt>targets (dict of str: nn.Module): dictionary of target models</dt>
-<dt>the spectrogram models to be used by the Separator.</dt>
-<dt><strong><code>niter</code></strong> : <code>int</code></dt>
-<dd>Number of EM steps for refining initial estimates in a
-post-processing stage. Zeroed if only one target is estimated.
-defaults to <code>1</code>.</dd>
-<dt><strong><code>residual</code></strong> : <code>bool</code></dt>
-<dd>adds an additional residual target, obtained by
-subtracting the other estimated targets from the mixture,
-before any potential EM post-processing.
-Defaults to <code>False</code>.</dd>
-<dt><strong><code>wiener_win_len</code></strong> : <code>int</code> or <code>None</code></dt>
-<dd>The size of the excerpts
-(number of frames) on which to apply filtering
-independently. This means assuming time varying stereo models and
-localization of sources.
-None means not batching but using the whole signal. It comes at the
-price of a much larger memory usage.</dd>
-<dt><strong><code>filterbank</code></strong> : <code>str</code></dt>
-<dd>filterbank implementation method.
-Supported are <code>['torch', 'asteroid']</code>. <code>torch</code> is about 30% faster
-compared to <code>asteroid</code> on large FFT sizes such as 4096. However,
-asteroids stft can be exported to onnx, which makes is practical
-for deployment.</dd>
-</dl>
-<p>Initializes internal Module state, shared by both nn.Module and ScriptModule.</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/model.py#L168-L346" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class Separator(nn.Module):
- """
- Separator class to encapsulate all the stereo filtering
- as a torch Module, to enable end-to-end learning.
-
- Args:
- targets (dict of str: nn.Module): dictionary of target models
- the spectrogram models to be used by the Separator.
- niter (int): Number of EM steps for refining initial estimates in a
- post-processing stage. Zeroed if only one target is estimated.
- defaults to `1`.
- residual (bool): adds an additional residual target, obtained by
- subtracting the other estimated targets from the mixture,
- before any potential EM post-processing.
- Defaults to `False`.
- wiener_win_len (int or None): The size of the excerpts
- (number of frames) on which to apply filtering
- independently. This means assuming time varying stereo models and
- localization of sources.
- None means not batching but using the whole signal. It comes at the
- price of a much larger memory usage.
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
- """
-
- def __init__(
- self,
- target_models: dict,
- niter: int = 0,
- softmask: bool = False,
- residual: bool = False,
- sample_rate: float = 44100.0,
- n_fft: int = 4096,
- n_hop: int = 1024,
- nb_channels: int = 2,
- wiener_win_len: Optional[int] = 300,
- filterbank: str = "torch",
- ):
- super(Separator, self).__init__()
-
- # saving parameters
- self.niter = niter
- self.residual = residual
- self.softmask = softmask
- self.wiener_win_len = wiener_win_len
-
- self.stft, self.istft = make_filterbanks(
- n_fft=n_fft,
- n_hop=n_hop,
- center=True,
- method=filterbank,
- sample_rate=sample_rate,
- )
- self.complexnorm = ComplexNorm(mono=nb_channels == 1)
-
- # registering the targets models
- self.target_models = nn.ModuleDict(target_models)
- # adding till https://github.com/pytorch/pytorch/issues/38963
- self.nb_targets = len(self.target_models)
- # get the sample_rate as the sample_rate of the first model
- # (tacitly assume it's the same for all targets)
- self.register_buffer("sample_rate", torch.as_tensor(sample_rate))
-
- def freeze(self):
- # set all parameters as not requiring gradient, more RAM-efficient
- # at test time
- for p in self.parameters():
- p.requires_grad = False
- self.eval()
-
- def forward(self, audio: Tensor) -> Tensor:
- """Performing the separation on audio input
-
- Args:
- audio (Tensor): [shape=(nb_samples, nb_channels, nb_timesteps)]
- mixture audio waveform
-
- Returns:
- Tensor: stacked tensor of separated waveforms
- shape `(nb_samples, nb_targets, nb_channels, nb_timesteps)`
- """
-
- nb_sources = self.nb_targets
- nb_samples = audio.shape[0]
-
- # getting the STFT of mix:
- # (nb_samples, nb_channels, nb_bins, nb_frames, 2)
- mix_stft = self.stft(audio)
- X = self.complexnorm(mix_stft)
-
- # initializing spectrograms variable
- spectrograms = torch.zeros(X.shape + (nb_sources,), dtype=audio.dtype, device=X.device)
-
- for j, (target_name, target_module) in enumerate(self.target_models.items()):
- # apply current model to get the source spectrogram
- target_spectrogram = target_module(X.detach().clone())
- spectrograms[..., j] = target_spectrogram
-
- # transposing it as
- # (nb_samples, nb_frames, nb_bins,{1,nb_channels}, nb_sources)
- spectrograms = spectrograms.permute(0, 3, 2, 1, 4)
-
- # rearranging it into:
- # (nb_samples, nb_frames, nb_bins, nb_channels, 2) to feed
- # into filtering methods
- mix_stft = mix_stft.permute(0, 3, 2, 1, 4)
-
- # create an additional target if we need to build a residual
- if self.residual:
- # we add an additional target
- nb_sources += 1
-
- if nb_sources == 1 and self.niter > 0:
- raise Exception(
- "Cannot use EM if only one target is estimated."
- "Provide two targets or create an additional "
- "one with `--residual`"
- )
-
- nb_frames = spectrograms.shape[1]
- targets_stft = torch.zeros(
- mix_stft.shape + (nb_sources,), dtype=audio.dtype, device=mix_stft.device
- )
- for sample in range(nb_samples):
- pos = 0
- if self.wiener_win_len:
- wiener_win_len = self.wiener_win_len
- else:
- wiener_win_len = nb_frames
- while pos < nb_frames:
- cur_frame = torch.arange(pos, min(nb_frames, pos + wiener_win_len))
- pos = int(cur_frame[-1]) + 1
-
- targets_stft[sample, cur_frame] = wiener(
- spectrograms[sample, cur_frame],
- mix_stft[sample, cur_frame],
- self.niter,
- softmask=self.softmask,
- residual=self.residual,
- )
-
- # getting to (nb_samples, nb_targets, channel, fft_size, n_frames, 2)
- targets_stft = targets_stft.permute(0, 5, 3, 2, 1, 4).contiguous()
-
- # inverse STFT
- estimates = self.istft(targets_stft, length=audio.shape[2])
-
- return estimates
-
- def to_dict(self, estimates: Tensor, aggregate_dict: Optional[dict] = None) -> dict:
- """Convert estimates as stacked tensor to dictionary
-
- Args:
- estimates (Tensor): separated targets of shape
- (nb_samples, nb_targets, nb_channels, nb_timesteps)
- aggregate_dict (dict or None)
-
- Returns:
- (dict of str: Tensor):
- """
- estimates_dict = {}
- for k, target in enumerate(self.target_models):
- estimates_dict[target] = estimates[:, k, ...]
-
- # in the case of residual, we added another source
- if self.residual:
- estimates_dict["residual"] = estimates[:, -1, ...]
-
- if aggregate_dict is not None:
- new_estimates = {}
- for key in aggregate_dict:
- new_estimates[key] = torch.tensor(0.0)
- for target in aggregate_dict[key]:
- new_estimates[key] = new_estimates[key] + estimates_dict[target]
- estimates_dict = new_estimates
- return estimates_dict</code></pre>
-</details>
-<h3>Ancestors</h3>
-<ul class="hlist">
-<li>torch.nn.modules.module.Module</li>
-</ul>
-<h3>Class variables</h3>
-<dl>
-<dt id="openunmix.model.Separator.dump_patches"><code class="name">var <span class="ident">dump_patches</span> :Â bool</code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-<dt id="openunmix.model.Separator.training"><code class="name">var <span class="ident">training</span> :Â bool</code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-</dl>
-<h3>Methods</h3>
-<dl>
-<dt id="openunmix.model.Separator.forward"><code class="name flex">
-<span>def <span class="ident">forward</span></span>(<span>self, audio: torch.Tensor) ‑> torch.Tensor</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Performing the separation on audio input</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>audio</code></strong> : <code>Tensor</code></dt>
-<dd>[shape=(nb_samples, nb_channels, nb_timesteps)]
-mixture audio waveform</dd>
-</dl>
-<h2 id="returns">Returns</h2>
-<dl>
-<dt><code>Tensor</code></dt>
-<dd>stacked tensor of separated waveforms
-shape <code>(nb_samples, nb_targets, nb_channels, nb_timesteps)</code></dd>
-</dl></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/model.py#L241-L318" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def forward(self, audio: Tensor) -> Tensor:
- """Performing the separation on audio input
-
- Args:
- audio (Tensor): [shape=(nb_samples, nb_channels, nb_timesteps)]
- mixture audio waveform
-
- Returns:
- Tensor: stacked tensor of separated waveforms
- shape `(nb_samples, nb_targets, nb_channels, nb_timesteps)`
- """
-
- nb_sources = self.nb_targets
- nb_samples = audio.shape[0]
-
- # getting the STFT of mix:
- # (nb_samples, nb_channels, nb_bins, nb_frames, 2)
- mix_stft = self.stft(audio)
- X = self.complexnorm(mix_stft)
-
- # initializing spectrograms variable
- spectrograms = torch.zeros(X.shape + (nb_sources,), dtype=audio.dtype, device=X.device)
-
- for j, (target_name, target_module) in enumerate(self.target_models.items()):
- # apply current model to get the source spectrogram
- target_spectrogram = target_module(X.detach().clone())
- spectrograms[..., j] = target_spectrogram
-
- # transposing it as
- # (nb_samples, nb_frames, nb_bins,{1,nb_channels}, nb_sources)
- spectrograms = spectrograms.permute(0, 3, 2, 1, 4)
-
- # rearranging it into:
- # (nb_samples, nb_frames, nb_bins, nb_channels, 2) to feed
- # into filtering methods
- mix_stft = mix_stft.permute(0, 3, 2, 1, 4)
-
- # create an additional target if we need to build a residual
- if self.residual:
- # we add an additional target
- nb_sources += 1
-
- if nb_sources == 1 and self.niter > 0:
- raise Exception(
- "Cannot use EM if only one target is estimated."
- "Provide two targets or create an additional "
- "one with `--residual`"
- )
-
- nb_frames = spectrograms.shape[1]
- targets_stft = torch.zeros(
- mix_stft.shape + (nb_sources,), dtype=audio.dtype, device=mix_stft.device
- )
- for sample in range(nb_samples):
- pos = 0
- if self.wiener_win_len:
- wiener_win_len = self.wiener_win_len
- else:
- wiener_win_len = nb_frames
- while pos < nb_frames:
- cur_frame = torch.arange(pos, min(nb_frames, pos + wiener_win_len))
- pos = int(cur_frame[-1]) + 1
-
- targets_stft[sample, cur_frame] = wiener(
- spectrograms[sample, cur_frame],
- mix_stft[sample, cur_frame],
- self.niter,
- softmask=self.softmask,
- residual=self.residual,
- )
-
- # getting to (nb_samples, nb_targets, channel, fft_size, n_frames, 2)
- targets_stft = targets_stft.permute(0, 5, 3, 2, 1, 4).contiguous()
-
- # inverse STFT
- estimates = self.istft(targets_stft, length=audio.shape[2])
-
- return estimates</code></pre>
-</details>
-</dd>
-<dt id="openunmix.model.Separator.freeze"><code class="name flex">
-<span>def <span class="ident">freeze</span></span>(<span>self)</span>
-</code></dt>
-<dd>
-<div class="desc"></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/model.py#L234-L239" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def freeze(self):
- # set all parameters as not requiring gradient, more RAM-efficient
- # at test time
- for p in self.parameters():
- p.requires_grad = False
- self.eval()</code></pre>
-</details>
-</dd>
-<dt id="openunmix.model.Separator.to_dict"><code class="name flex">
-<span>def <span class="ident">to_dict</span></span>(<span>self, estimates: torch.Tensor, aggregate_dict: Union[dict, NoneType] = None) ‑> dict</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Convert estimates as stacked tensor to dictionary</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>estimates</code></strong> : <code>Tensor</code></dt>
-<dd>separated targets of shape
-(nb_samples, nb_targets, nb_channels, nb_timesteps)</dd>
-</dl>
-<p>aggregate_dict (dict or None)</p>
-<h2 id="returns">Returns</h2>
-<p>(dict of str: Tensor):</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/model.py#L320-L346" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def to_dict(self, estimates: Tensor, aggregate_dict: Optional[dict] = None) -> dict:
- """Convert estimates as stacked tensor to dictionary
-
- Args:
- estimates (Tensor): separated targets of shape
- (nb_samples, nb_targets, nb_channels, nb_timesteps)
- aggregate_dict (dict or None)
-
- Returns:
- (dict of str: Tensor):
- """
- estimates_dict = {}
- for k, target in enumerate(self.target_models):
- estimates_dict[target] = estimates[:, k, ...]
-
- # in the case of residual, we added another source
- if self.residual:
- estimates_dict["residual"] = estimates[:, -1, ...]
-
- if aggregate_dict is not None:
- new_estimates = {}
- for key in aggregate_dict:
- new_estimates[key] = torch.tensor(0.0)
- for target in aggregate_dict[key]:
- new_estimates[key] = new_estimates[key] + estimates_dict[target]
- estimates_dict = new_estimates
- return estimates_dict</code></pre>
-</details>
-</dd>
-</dl>
-</dd>
-</dl>
-</section>
-</article>
-<nav id="sidebar">
-<h1>Index</h1>
-<div class="toc">
-<ul></ul>
-</div>
-<ul id="index">
-<li><h3>Super-module</h3>
-<ul>
-<li><code><a title="openunmix" href="index.html">openunmix</a></code></li>
-</ul>
-</li>
-<li><h3><a href="#header-classes">Classes</a></h3>
-<ul>
-<li>
-<h4><code><a title="openunmix.model.OpenUnmix" href="#openunmix.model.OpenUnmix">OpenUnmix</a></code></h4>
-<ul class="">
-<li><code><a title="openunmix.model.OpenUnmix.dump_patches" href="#openunmix.model.OpenUnmix.dump_patches">dump_patches</a></code></li>
-<li><code><a title="openunmix.model.OpenUnmix.forward" href="#openunmix.model.OpenUnmix.forward">forward</a></code></li>
-<li><code><a title="openunmix.model.OpenUnmix.freeze" href="#openunmix.model.OpenUnmix.freeze">freeze</a></code></li>
-<li><code><a title="openunmix.model.OpenUnmix.training" href="#openunmix.model.OpenUnmix.training">training</a></code></li>
-</ul>
-</li>
-<li>
-<h4><code><a title="openunmix.model.Separator" href="#openunmix.model.Separator">Separator</a></code></h4>
-<ul class="">
-<li><code><a title="openunmix.model.Separator.dump_patches" href="#openunmix.model.Separator.dump_patches">dump_patches</a></code></li>
-<li><code><a title="openunmix.model.Separator.forward" href="#openunmix.model.Separator.forward">forward</a></code></li>
-<li><code><a title="openunmix.model.Separator.freeze" href="#openunmix.model.Separator.freeze">freeze</a></code></li>
-<li><code><a title="openunmix.model.Separator.to_dict" href="#openunmix.model.Separator.to_dict">to_dict</a></code></li>
-<li><code><a title="openunmix.model.Separator.training" href="#openunmix.model.Separator.training">training</a></code></li>
-</ul>
-</li>
-</ul>
-</li>
-</ul>
-</nav>
-</main>
-<footer id="footer">
-<p>Generated by <a href="https://pdoc3.github.io/pdoc"><cite>pdoc</cite> 0.9.2</a>.</p>
-</footer>
-</body>
-</html>
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/predict.html b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/predict.html
deleted file mode 100644
index 2f8e34eb8a9613dcb2d2aa699706dd327e7d23da..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/predict.html
+++ /dev/null
@@ -1,282 +0,0 @@
-<!doctype html>
-<html lang="en">
-<head>
-<meta charset="utf-8">
-<meta name="viewport" content="width=device-width, initial-scale=1, minimum-scale=1" />
-<meta name="generator" content="pdoc 0.9.2" />
-<title>openunmix.predict API documentation</title>
-<meta name="description" content="" />
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/sanitize.min.css" integrity="sha256-PK9q560IAAa6WVRRh76LtCaI8pjTJ2z11v0miyNNjrs=" crossorigin>
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/typography.min.css" integrity="sha256-7l/o7C8jubJiy74VsKTidCy1yBkRtiUGbVkYBylBqUg=" crossorigin>
-<link rel="stylesheet preload" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/styles/github.min.css" crossorigin>
-<style>:root{--highlight-color:#fe9}.flex{display:flex !important}body{line-height:1.5em}#content{padding:20px}#sidebar{padding:30px;overflow:hidden}#sidebar > *:last-child{margin-bottom:2cm}.http-server-breadcrumbs{font-size:130%;margin:0 0 15px 0}#footer{font-size:.75em;padding:5px 30px;border-top:1px solid #ddd;text-align:right}#footer p{margin:0 0 0 1em;display:inline-block}#footer p:last-child{margin-right:30px}h1,h2,h3,h4,h5{font-weight:300}h1{font-size:2.5em;line-height:1.1em}h2{font-size:1.75em;margin:1em 0 .50em 0}h3{font-size:1.4em;margin:25px 0 10px 0}h4{margin:0;font-size:105%}h1:target,h2:target,h3:target,h4:target,h5:target,h6:target{background:var(--highlight-color);padding:.2em 0}a{color:#058;text-decoration:none;transition:color .3s ease-in-out}a:hover{color:#e82}.title code{font-weight:bold}h2[id^="header-"]{margin-top:2em}.ident{color:#900}pre code{background:#f8f8f8;font-size:.8em;line-height:1.4em}code{background:#f2f2f1;padding:1px 4px;overflow-wrap:break-word}h1 code{background:transparent}pre{background:#f8f8f8;border:0;border-top:1px solid #ccc;border-bottom:1px solid #ccc;margin:1em 0;padding:1ex}#http-server-module-list{display:flex;flex-flow:column}#http-server-module-list div{display:flex}#http-server-module-list dt{min-width:10%}#http-server-module-list p{margin-top:0}.toc ul,#index{list-style-type:none;margin:0;padding:0}#index code{background:transparent}#index h3{border-bottom:1px solid #ddd}#index ul{padding:0}#index h4{margin-top:.6em;font-weight:bold}@media (min-width:200ex){#index .two-column{column-count:2}}@media (min-width:300ex){#index .two-column{column-count:3}}dl{margin-bottom:2em}dl dl:last-child{margin-bottom:4em}dd{margin:0 0 1em 3em}#header-classes + dl > dd{margin-bottom:3em}dd dd{margin-left:2em}dd p{margin:10px 0}.name{background:#eee;font-weight:bold;font-size:.85em;padding:5px 10px;display:inline-block;min-width:40%}.name:hover{background:#e0e0e0}dt:target .name{background:var(--highlight-color)}.name > span:first-child{white-space:nowrap}.name.class > span:nth-child(2){margin-left:.4em}.inherited{color:#999;border-left:5px solid #eee;padding-left:1em}.inheritance em{font-style:normal;font-weight:bold}.desc h2{font-weight:400;font-size:1.25em}.desc h3{font-size:1em}.desc dt code{background:inherit}.source summary,.git-link-div{color:#666;text-align:right;font-weight:400;font-size:.8em;text-transform:uppercase}.source summary > *{white-space:nowrap;cursor:pointer}.git-link{color:inherit;margin-left:1em}.source pre{max-height:500px;overflow:auto;margin:0}.source pre code{font-size:12px;overflow:visible}.hlist{list-style:none}.hlist li{display:inline}.hlist li:after{content:',\2002'}.hlist li:last-child:after{content:none}.hlist .hlist{display:inline;padding-left:1em}img{max-width:100%}td{padding:0 .5em}.admonition{padding:.1em .5em;margin-bottom:1em}.admonition-title{font-weight:bold}.admonition.note,.admonition.info,.admonition.important{background:#aef}.admonition.todo,.admonition.versionadded,.admonition.tip,.admonition.hint{background:#dfd}.admonition.warning,.admonition.versionchanged,.admonition.deprecated{background:#fd4}.admonition.error,.admonition.danger,.admonition.caution{background:lightpink}</style>
-<style media="screen and (min-width: 700px)">@media screen and (min-width:700px){#sidebar{width:30%;height:100vh;overflow:auto;position:sticky;top:0}#content{width:70%;max-width:100ch;padding:3em 4em;border-left:1px solid #ddd}pre code{font-size:1em}.item .name{font-size:1em}main{display:flex;flex-direction:row-reverse;justify-content:flex-end}.toc ul ul,#index ul{padding-left:1.5em}.toc > ul > li{margin-top:.5em}}</style>
-<style media="print">@media print{#sidebar h1{page-break-before:always}.source{display:none}}@media print{*{background:transparent !important;color:#000 !important;box-shadow:none !important;text-shadow:none !important}a[href]:after{content:" (" attr(href) ")";font-size:90%}a[href][title]:after{content:none}abbr[title]:after{content:" (" attr(title) ")"}.ir a:after,a[href^="javascript:"]:after,a[href^="#"]:after{content:""}pre,blockquote{border:1px solid #999;page-break-inside:avoid}thead{display:table-header-group}tr,img{page-break-inside:avoid}img{max-width:100% !important}@page{margin:0.5cm}p,h2,h3{orphans:3;widows:3}h1,h2,h3,h4,h5,h6{page-break-after:avoid}}</style>
-<script async src="https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.7/latest.js?config=TeX-AMS_CHTML" integrity="sha256-kZafAc6mZvK3W3v1pHOcUix30OHQN6pU/NO2oFkqZVw=" crossorigin></script>
-<script defer src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/highlight.min.js" integrity="sha256-Uv3H6lx7dJmRfRvH8TH6kJD1TSK1aFcwgx+mdg3epi8=" crossorigin></script>
-<script>window.addEventListener('DOMContentLoaded', () => hljs.initHighlighting())</script>
-</head>
-<body>
-<main>
-<article id="content">
-<header>
-<h1 class="title">Module <code>openunmix.predict</code></h1>
-</header>
-<section id="section-intro">
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/predict.py#L0-L79" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">from openunmix import utils
-
-
-def separate(
- audio,
- rate=None,
- model_str_or_path="umxhq",
- targets=None,
- niter=1,
- residual=False,
- wiener_win_len=300,
- aggregate_dict=None,
- separator=None,
- device=None,
- filterbank="torch",
-):
- """
- Open Unmix functional interface
-
- Separates a torch.Tensor or the content of an audio file.
-
- If a separator is provided, use it for inference. If not, create one
- and use it afterwards.
-
- Args:
- audio: audio to process
- torch Tensor: shape (channels, length), and
- `rate` must also be provided.
- rate: int or None: only used if audio is a Tensor. Otherwise,
- inferred from the file.
- model_str_or_path: the pretrained model to use
- targets (str): select the targets for the source to be separated.
- a list including: ['vocals', 'drums', 'bass', 'other'].
- If you don't pick them all, you probably want to
- activate the `residual=True` option.
- Defaults to all available targets per model.
- niter (int): the number of post-processingiterations, defaults to 1
- residual (bool): if True, a "garbage" target is created
- wiener_win_len (int): the number of frames to use when batching
- the post-processing step
- aggregate_dict (str): if provided, must be a string containing a '
- 'valid expression for a dictionary, with keys as output '
- 'target names, and values a list of targets that are used to '
- 'build it. For instance: \'{\"vocals\":[\"vocals\"], '
- '\"accompaniment\":[\"drums\",\"bass\",\"other\"]}\'
- separator: if provided, the model.Separator object that will be used
- to perform separation
- device (str): selects device to be used for inference
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
- """
- if separator is None:
- separator = utils.load_separator(
- model_str_or_path=model_str_or_path,
- targets=targets,
- niter=niter,
- residual=residual,
- wiener_win_len=wiener_win_len,
- device=device,
- pretrained=True,
- filterbank=filterbank,
- )
- separator.freeze()
- if device:
- separator.to(device)
-
- if rate is None:
- raise Exception("rate` must be provided.")
-
- if device:
- audio = audio.to(device)
- audio = utils.preprocess(audio, rate, separator.sample_rate)
-
- # getting the separated signals
- estimates = separator(audio)
- estimates = separator.to_dict(estimates, aggregate_dict=aggregate_dict)
- return estimates</code></pre>
-</details>
-</section>
-<section>
-</section>
-<section>
-</section>
-<section>
-<h2 class="section-title" id="header-functions">Functions</h2>
-<dl>
-<dt id="openunmix.predict.separate"><code class="name flex">
-<span>def <span class="ident">separate</span></span>(<span>audio, rate=None, model_str_or_path='umxhq', targets=None, niter=1, residual=False, wiener_win_len=300, aggregate_dict=None, separator=None, device=None, filterbank='torch')</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Open Unmix functional interface</p>
-<p>Separates a torch.Tensor or the content of an audio file.</p>
-<p>If a separator is provided, use it for inference. If not, create one
-and use it afterwards.</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>audio</code></strong></dt>
-<dd>audio to process
-torch Tensor: shape (channels, length), and
-<code>rate</code> must also be provided.</dd>
-<dt><strong><code>rate</code></strong></dt>
-<dd>int or None: only used if audio is a Tensor. Otherwise,
-inferred from the file.</dd>
-<dt><strong><code>model_str_or_path</code></strong></dt>
-<dd>the pretrained model to use</dd>
-<dt><strong><code>targets</code></strong> : <code>str</code></dt>
-<dd>select the targets for the source to be separated.
-a list including: ['vocals', 'drums', 'bass', 'other'].
-If you don't pick them all, you probably want to
-activate the <code>residual=True</code> option.
-Defaults to all available targets per model.</dd>
-<dt><strong><code>niter</code></strong> : <code>int</code></dt>
-<dd>the number of post-processingiterations, defaults to 1</dd>
-<dt><strong><code>residual</code></strong> : <code>bool</code></dt>
-<dd>if True, a "garbage" target is created</dd>
-<dt><strong><code>wiener_win_len</code></strong> : <code>int</code></dt>
-<dd>the number of frames to use when batching
-the post-processing step</dd>
-<dt><strong><code>aggregate_dict</code></strong> : <code>str</code></dt>
-<dd>if provided, must be a string containing a '
-'valid expression for a dictionary, with keys as output '
-'target names, and values a list of targets that are used to '
-'build it. For instance: '{"vocals":["vocals"], '
-'"accompaniment":["drums","bass","other"]}'</dd>
-<dt><strong><code>separator</code></strong></dt>
-<dd>if provided, the model.Separator object that will be used
-to perform separation</dd>
-<dt><strong><code>device</code></strong> : <code>str</code></dt>
-<dd>selects device to be used for inference</dd>
-<dt><strong><code>filterbank</code></strong> : <code>str</code></dt>
-<dd>filterbank implementation method.
-Supported are <code>['torch', 'asteroid']</code>. <code>torch</code> is about 30% faster
-compared to <code>asteroid</code> on large FFT sizes such as 4096. However,
-asteroids stft can be exported to onnx, which makes is practical
-for deployment.</dd>
-</dl></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/predict.py#L4-L80" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def separate(
- audio,
- rate=None,
- model_str_or_path="umxhq",
- targets=None,
- niter=1,
- residual=False,
- wiener_win_len=300,
- aggregate_dict=None,
- separator=None,
- device=None,
- filterbank="torch",
-):
- """
- Open Unmix functional interface
-
- Separates a torch.Tensor or the content of an audio file.
-
- If a separator is provided, use it for inference. If not, create one
- and use it afterwards.
-
- Args:
- audio: audio to process
- torch Tensor: shape (channels, length), and
- `rate` must also be provided.
- rate: int or None: only used if audio is a Tensor. Otherwise,
- inferred from the file.
- model_str_or_path: the pretrained model to use
- targets (str): select the targets for the source to be separated.
- a list including: ['vocals', 'drums', 'bass', 'other'].
- If you don't pick them all, you probably want to
- activate the `residual=True` option.
- Defaults to all available targets per model.
- niter (int): the number of post-processingiterations, defaults to 1
- residual (bool): if True, a "garbage" target is created
- wiener_win_len (int): the number of frames to use when batching
- the post-processing step
- aggregate_dict (str): if provided, must be a string containing a '
- 'valid expression for a dictionary, with keys as output '
- 'target names, and values a list of targets that are used to '
- 'build it. For instance: \'{\"vocals\":[\"vocals\"], '
- '\"accompaniment\":[\"drums\",\"bass\",\"other\"]}\'
- separator: if provided, the model.Separator object that will be used
- to perform separation
- device (str): selects device to be used for inference
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
- """
- if separator is None:
- separator = utils.load_separator(
- model_str_or_path=model_str_or_path,
- targets=targets,
- niter=niter,
- residual=residual,
- wiener_win_len=wiener_win_len,
- device=device,
- pretrained=True,
- filterbank=filterbank,
- )
- separator.freeze()
- if device:
- separator.to(device)
-
- if rate is None:
- raise Exception("rate` must be provided.")
-
- if device:
- audio = audio.to(device)
- audio = utils.preprocess(audio, rate, separator.sample_rate)
-
- # getting the separated signals
- estimates = separator(audio)
- estimates = separator.to_dict(estimates, aggregate_dict=aggregate_dict)
- return estimates</code></pre>
-</details>
-</dd>
-</dl>
-</section>
-<section>
-</section>
-</article>
-<nav id="sidebar">
-<h1>Index</h1>
-<div class="toc">
-<ul></ul>
-</div>
-<ul id="index">
-<li><h3>Super-module</h3>
-<ul>
-<li><code><a title="openunmix" href="index.html">openunmix</a></code></li>
-</ul>
-</li>
-<li><h3><a href="#header-functions">Functions</a></h3>
-<ul class="">
-<li><code><a title="openunmix.predict.separate" href="#openunmix.predict.separate">separate</a></code></li>
-</ul>
-</li>
-</ul>
-</nav>
-</main>
-<footer id="footer">
-<p>Generated by <a href="https://pdoc3.github.io/pdoc"><cite>pdoc</cite> 0.9.2</a>.</p>
-</footer>
-</body>
-</html>
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/training.md b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/training.md
deleted file mode 100644
index 82fa80b959ea66908e1c01f846ac8fb2b236631d..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/training.md
+++ /dev/null
@@ -1,240 +0,0 @@
-# Training Open-Unmix
-
-> This documentation refers to the standard training procedure for _Open-unmix_, where each target is trained independently. It has not been updated for the end-to-end training capabilities that the `Separator` module allows. Please contribute if you try this.
-
-Both models, `umxhq` and `umx` that are provided with pre-trained weights, can be trained using the default parameters of the `scripts/train.py` function.
-
-## Installation
-
-The train function is not part of the python package, thus we suggest to use [Anaconda](https://anaconda.org/) to install the training requirments, also because the environment would allow reproducible results.
-
-To create a conda environment for _open-unmix_, simply run:
-
-`conda env create -f scripts/environment-X.yml` where `X` is either [`cpu-linux`, `gpu-linux-cuda10`, `cpu-osx`], depending on your system. For now, we haven't tested windows support.
-
-## Training API
-
-The [MUSDB18](https://sigsep.github.io/datasets/musdb.html) and [MUSDB18-HQ](https://sigsep.github.io/datasets/musdb.html) are the largest freely available datasets for professionally produced music tracks (~10h duration) of different styles. They come with isolated `drums`, `bass`, `vocals` and `others` stems. _MUSDB18_ contains two subsets: "train", composed of 100 songs, and "test", composed of 50 songs.
-
-To directly train a vocal model with _open-unmix_, we first would need to download one of the datasets and place in _unzipped_ in a directory of your choice (called `root`).
-
-| Argument | Description | Default |
-|----------|-------------|---------|
-| `--root <str>` | path to root of dataset on disk. | `None` |
-
-Also note that, if `--root` is not specified, we automatically download a 7 second preview version of the MUSDB18 dataset. While this is comfortable for testing purposes, we wouldn't recommend to actually train your model on this.
-
-Training can be started using
-
-```bash
-python train.py --root path/to/musdb18 --target vocals
-```
-
-Training `MUSDB18` using _open-unmix_ comes with several design decisions that we made as part of our defaults to improve efficiency and performance:
-
-* __chunking__: we do not feed full audio tracks into _open-unmix_ but instead chunk the audio into 6s excerpts (`--seq-dur 6.0`).
-* __balanced track sampling__: to not create a bias for longer audio tracks we randomly yield one track from MUSDB18 and select a random chunk subsequently. In one epoch we select (on average) 64 samples from each track.
-* __source augmentation__: we apply random gains between `0.25` and `1.25` to all sources before mixing. Furthermore, we randomly swap the channels the input mixture.
-* __random track mixing__: for a given target we select a _random track_ with replacement. To yield a mixture we draw the interfering sources from different tracks (again with replacement) to increase generalization of the model.
-* __fixed validation split__: we provide a fixed validation split of [14 tracks](https://github.com/sigsep/sigsep-mus-db/blob/b283da5b8f24e84172a60a06bb8f3dacd57aa6cd/musdb/configs/mus.yaml#L41). We evaluate on these tracks in full length instead of using chunking to have evaluation as close as possible to the actual test data.
-
-Some of the parameters for the MUSDB sampling can be controlled using the following arguments:
-
-| Argument | Description | Default |
-|---------------------|-----------------------------------------------|--------------|
-| `--is-wav` | loads the decoded WAVs instead of STEMS for faster data loading. See [more details here](https://github.com/sigsep/sigsep-mus-db#using-wav-files-optional). | `True` |
-| `--samples-per-track <int>` | sets the number of samples that are randomly drawn from each track | `64` |
-| `--source-augmentations <list[str]>` | applies augmentations to each audio source before mixing, available augmentations: `[gain, channelswap]`| [gain, channelswap] |
-
-## Training and Model Parameters
-
-An extensive list of additional training parameters allows researchers to quickly try out different parameterizations such as a different FFT size. The table below, we list the additional training parameters and their default values (used for `umxhq` and `umx`L:
-
-| Argument | Description | Default |
-|----------------------------|---------------------------------------------------------------------------------|-----------------|
-| `--target <str>` | name of target source (will be passed to the dataset) | `vocals` |
-| `--output <str>` | path where to save the trained output model as well as checkpoints. | `./open-unmix` |
-| `--checkpoint <str>` | path to checkpoint of target model to resume training. | not set |
-| `--model <str>` | path or str to pretrained target to fine-tune model | not set |
-| `--no_cuda` | disable cuda even if available | not set |
-| `--epochs <int>` | Number of epochs to train | `1000` |
-| `--batch-size <int>` | Batch size has influence on memory usage and performance of the LSTM layer | `16` |
-| `--patience <int>` | early stopping patience | `140` |
-| `--seq-dur <int>` | Sequence duration in seconds of chunks taken from the dataset. A value of `<=0.0` results in full/variable length | `6.0` |
-| `--unidirectional` | changes the bidirectional LSTM to unidirectional (for real-time applications) | not set |
-| `--hidden-size <int>` | Hidden size parameter of dense bottleneck layers | `512` |
-| `--nfft <int>` | STFT FFT window length in samples | `4096` |
-| `--nhop <int>` | STFT hop length in samples | `1024` |
-| `--lr <float>` | learning rate | `0.001` |
-| `--lr-decay-patience <int>` | learning rate decay patience for plateau scheduler | `80` |
-| `--lr-decay-gamma <float>` | gamma of learning rate plateau scheduler. | `0.3` |
-| `--weight-decay <float>` | weight decay for regularization | `0.00001` |
-| `--bandwidth <int>` | maximum bandwidth in Hertz processed by the LSTM. Input and Output is always full bandwidth! | `16000` |
-| `--nb-channels <int>` | set number of channels for model (1 for mono (spectral downmix is applied,) 2 for stereo) | `2` |
-| `--nb-workers <int>` | Number of (parallel) workers for data-loader, can be safely increased for wav files | `0` |
-| `--quiet` | disable print and progress bar during training | not set |
-| `--seed <int>` | Initial seed to set the random initialization | `42` |
-| `--audio-backend <str>` | choose audio loading backend, either `sox` or `soundfile` | `soundfile` for training, `sox` for inference |
-
-### Training details of `umxhq`
-
-The training of `umxhq` took place on Nvidia RTX2080 cards. Equipped with fast SSDs and `--nb-workers 4`, we could utilize around 90% of the GPU, thus training time was around 80 seconds per epoch. We ran four different seeds for each target and selected the model with the lowest validation loss.
-
-The training and validation loss curves are plotted below:
-
-
-
-## Other Datasets
-
-_open-unmix_ uses standard PyTorch [`torch.utils.data.Dataset`](https://pytorch.org/docs/stable/data.html#torch.utils.data.Dataset) classes. The repository comes with __five__ different datasets which cover a wide range of tasks and applications around source separation. Furthermore we also provide a template Dataset if you want to start using your own dataset. The dataset can be selected through a command line argument:
-
-| Argument | Description | Default |
-|----------------------------|------------------------------------------------------------------------|--------------|
-| `--dataset <str>` | Name of the dataset (select from `musdb`, `aligned`, `sourcefolder`, `trackfolder_var`, `trackfolder_fix`) | `musdb` |
-
-### `AlignedDataset` (aligned)
-
-This dataset assumes multiple track folders, where each track includes an input and one output file, directly corresponding to the input and the output of the model.
-
-This dataset is the most basic of all datasets provided here, due to the least amount of
-preprocessing, it is also the fastest option, however, it lacks any kind of source augmentations or custom mixing. Instead, it directly uses the target files that are within the folder. The filenames would have to be identical for each track. E.g, for the first sample of the training, input could be `1/mixture.wav` and output could be `1/vocals.wav`.
-
-Typical use cases:
-
-* Source Separation (Mixture -> Target)
-* Denoising (Noisy -> Clean)
-* Bandwidth Extension (Low Bandwidth -> High Bandwidth)
-
-#### File Structure
-
-```
-data/train/1/mixture.wav --> input
-data/train/1/vocals.wav ---> output
-...
-data/valid/1/mixture.wav --> input
-data/valid/1/vocals.wav ---> output
-
-```
-
-#### Parameters
-
-| Argument | Description | Default |
-|----------|-------------|---------|
-|`--input-file <str>` | input file name | `None` |
-|`--output-file <str>` | output file name | `None` |
-
-#### Example
-
-```bash
-python train.py --dataset aligned --root /dataset --input_file mixture.wav --output_file vocals.wav
-```
-
-### `SourceFolderDataset` (sourcefolder)
-
-A dataset of that assumes folders of sources,
-instead of track folders. This is a common
-format for speech and environmental sound datasets
-such das DCASE. For each source a variable number of
-tracks/sounds is available, therefore the dataset is unaligned by design.
-
-In this scenario one could easily train a network to separate a target sounds from interfering sounds. For each sample, the data loader loads a random combination of target+interferer as the input and performs a linear mixture of these. The output of the model is the target.
-
-#### File structure
-
-```
-train/vocals/track11.wav -----------------\
-train/drums/track202.wav (interferer1) ---+--> input
-train/bass/track007a.wav (interferer2) --/
-
-train/vocals/track11.wav ---------------------> output
-```
-
-#### Parameters
-
-| Argument | Description | Default |
-|----------|-------------|---------|
-|`--interferer-dirs list[<str>]` | list of directories used as interferers | `None` |
-|`--target-dir <str>` | directory that contains the target source | `None` |
-|`--ext <str>` | File extension | `.wav` |
-|`--ext <str>` | File extension | `.wav` |
-|`--nb-train-samples <str>` | Number of samples drawn for training | `1000` |
-|`--nb-valid-samples <str>` | Number of samples drawn for validation | `100` |
-|`--source-augmentations list[<str>]` | List of augmentation functions that are processed in the order of the list | |
-
-#### Example
-
-```bash
-python train.py --dataset sourcefolder --root /data --target-dir vocals --interferer-dirs car_noise wind_noise --ext .ogg --nb-train-samples 1000
-```
-
-### `FixedSourcesTrackFolderDataset` (trackfolder_fix)
-
-A dataset of that assumes audio sources to be stored
-in track folder where each track has a fixed number of sources. For each track the users specifies the target file-name (`target_file`) and a list of interferences files (`interferer_files`).
-A linear mix is performed on the fly by summing the target and the interferers up.
-
-Due to the fact that all tracks comprise the exact same set of sources, the random track mixing augmentation technique can be used, where sources from different tracks are mixed together. Setting `random_track_mix=True` results in an unaligned dataset.
-When random track mixing is enabled, we define an epoch as when the the target source from all tracks has been seen and only once with whatever interfering sources has randomly been drawn.
-
-This dataset is recommended to be used for small/medium size for example like the MUSDB18 or other custom source separation datasets.
-
-#### File structure
-
-```sh
-train/1/vocals.wav ---------------\
-train/1/drums.wav (interferer1) ---+--> input
-train/1/bass.wav -(interferer2) --/
-
-train/1/vocals.wav -------------------> output
-```
-
-#### Parameters
-
-| Argument | Description | Default |
-|----------|-------------|---------|
-|`--target-file <str>` | Target file (includes extension) | `None` |
-|`--interferer-files list[<str>]` | list of interfering sources | `None` |
-|`--random-track-mix` | Applies random track mixing | `False` |
-|`--source-augmentations list[<str>]` | List of augmentation functions that are processed in the order of the list | |
-
-#### Example
-
-```
-python train.py --root /data --dataset trackfolder_fix --target-file vocals.flac --interferer-files bass.flac drums.flac other.flac
-```
-
-### `VariableSourcesTrackFolderDataset` (trackfolder_var)
-
-A dataset of that assumes audio sources to be stored in track folder where each track has a _variable_ number of sources. The users specifies the target file-name (`target_file`) and the extension of sources to used for mixing. A linear mix is performed on the fly by summing all sources in a track folder.
-
-Since the number of sources differ per track, while target is fixed, a random track mix augmentation cannot be used.
-Also make sure, that you do not provide the mixture file among the sources! This dataset maximizes the number of tracks that can be used since it doesn't require the presence of a fixed number of sources per track. However, it is required to
-have the target file to be present. To increase the dataset utilization even further users can enable the `--silence-missing-targets` option that outputs silence to missing targets.
-
-#### File structure
-
-```sh
-train/1/vocals.wav --> input target \
-train/1/drums.wav --> input target |
-train/1/bass.wav --> input target --+--> input
-train/1/accordion.wav --> input target |
-train/1/marimba.wav --> input target /
-
-train/1/vocals.wav -----------------------> output
-```
-
-#### Parameters
-
-| Argument | Description | Default |
-|----------|-------------|---------|
-|`--target-file <str>` | file name of target file | `None` |
-|`--silence-missing-targets` | if a target is not among the list of sources it will be filled with zero | not set |
-|`random interferer mixing` | use _random track_ for the inference track to increase generalization of the model. | not set |
-|`--ext <str>` | File extension that is used to find the interfering files | `.wav` |
-|`--source-augmentations list[<str>]` | List of augmentation functions that are processed in the order of the list | |
-
-#### Example
-
-```
-python train.py --root /data --dataset trackfolder_var --target-file vocals.flac --ext .wav
-```
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/transforms.html b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/transforms.html
deleted file mode 100644
index 251edafc481921734ecaa357bf043b8fd875e60a..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/transforms.html
+++ /dev/null
@@ -1,950 +0,0 @@
-<!doctype html>
-<html lang="en">
-<head>
-<meta charset="utf-8">
-<meta name="viewport" content="width=device-width, initial-scale=1, minimum-scale=1" />
-<meta name="generator" content="pdoc 0.9.2" />
-<title>openunmix.transforms API documentation</title>
-<meta name="description" content="" />
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/sanitize.min.css" integrity="sha256-PK9q560IAAa6WVRRh76LtCaI8pjTJ2z11v0miyNNjrs=" crossorigin>
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/typography.min.css" integrity="sha256-7l/o7C8jubJiy74VsKTidCy1yBkRtiUGbVkYBylBqUg=" crossorigin>
-<link rel="stylesheet preload" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/styles/github.min.css" crossorigin>
-<style>:root{--highlight-color:#fe9}.flex{display:flex !important}body{line-height:1.5em}#content{padding:20px}#sidebar{padding:30px;overflow:hidden}#sidebar > *:last-child{margin-bottom:2cm}.http-server-breadcrumbs{font-size:130%;margin:0 0 15px 0}#footer{font-size:.75em;padding:5px 30px;border-top:1px solid #ddd;text-align:right}#footer p{margin:0 0 0 1em;display:inline-block}#footer p:last-child{margin-right:30px}h1,h2,h3,h4,h5{font-weight:300}h1{font-size:2.5em;line-height:1.1em}h2{font-size:1.75em;margin:1em 0 .50em 0}h3{font-size:1.4em;margin:25px 0 10px 0}h4{margin:0;font-size:105%}h1:target,h2:target,h3:target,h4:target,h5:target,h6:target{background:var(--highlight-color);padding:.2em 0}a{color:#058;text-decoration:none;transition:color .3s ease-in-out}a:hover{color:#e82}.title code{font-weight:bold}h2[id^="header-"]{margin-top:2em}.ident{color:#900}pre code{background:#f8f8f8;font-size:.8em;line-height:1.4em}code{background:#f2f2f1;padding:1px 4px;overflow-wrap:break-word}h1 code{background:transparent}pre{background:#f8f8f8;border:0;border-top:1px solid #ccc;border-bottom:1px solid #ccc;margin:1em 0;padding:1ex}#http-server-module-list{display:flex;flex-flow:column}#http-server-module-list div{display:flex}#http-server-module-list dt{min-width:10%}#http-server-module-list p{margin-top:0}.toc ul,#index{list-style-type:none;margin:0;padding:0}#index code{background:transparent}#index h3{border-bottom:1px solid #ddd}#index ul{padding:0}#index h4{margin-top:.6em;font-weight:bold}@media (min-width:200ex){#index .two-column{column-count:2}}@media (min-width:300ex){#index .two-column{column-count:3}}dl{margin-bottom:2em}dl dl:last-child{margin-bottom:4em}dd{margin:0 0 1em 3em}#header-classes + dl > dd{margin-bottom:3em}dd dd{margin-left:2em}dd p{margin:10px 0}.name{background:#eee;font-weight:bold;font-size:.85em;padding:5px 10px;display:inline-block;min-width:40%}.name:hover{background:#e0e0e0}dt:target .name{background:var(--highlight-color)}.name > span:first-child{white-space:nowrap}.name.class > span:nth-child(2){margin-left:.4em}.inherited{color:#999;border-left:5px solid #eee;padding-left:1em}.inheritance em{font-style:normal;font-weight:bold}.desc h2{font-weight:400;font-size:1.25em}.desc h3{font-size:1em}.desc dt code{background:inherit}.source summary,.git-link-div{color:#666;text-align:right;font-weight:400;font-size:.8em;text-transform:uppercase}.source summary > *{white-space:nowrap;cursor:pointer}.git-link{color:inherit;margin-left:1em}.source pre{max-height:500px;overflow:auto;margin:0}.source pre code{font-size:12px;overflow:visible}.hlist{list-style:none}.hlist li{display:inline}.hlist li:after{content:',\2002'}.hlist li:last-child:after{content:none}.hlist .hlist{display:inline;padding-left:1em}img{max-width:100%}td{padding:0 .5em}.admonition{padding:.1em .5em;margin-bottom:1em}.admonition-title{font-weight:bold}.admonition.note,.admonition.info,.admonition.important{background:#aef}.admonition.todo,.admonition.versionadded,.admonition.tip,.admonition.hint{background:#dfd}.admonition.warning,.admonition.versionchanged,.admonition.deprecated{background:#fd4}.admonition.error,.admonition.danger,.admonition.caution{background:lightpink}</style>
-<style media="screen and (min-width: 700px)">@media screen and (min-width:700px){#sidebar{width:30%;height:100vh;overflow:auto;position:sticky;top:0}#content{width:70%;max-width:100ch;padding:3em 4em;border-left:1px solid #ddd}pre code{font-size:1em}.item .name{font-size:1em}main{display:flex;flex-direction:row-reverse;justify-content:flex-end}.toc ul ul,#index ul{padding-left:1.5em}.toc > ul > li{margin-top:.5em}}</style>
-<style media="print">@media print{#sidebar h1{page-break-before:always}.source{display:none}}@media print{*{background:transparent !important;color:#000 !important;box-shadow:none !important;text-shadow:none !important}a[href]:after{content:" (" attr(href) ")";font-size:90%}a[href][title]:after{content:none}abbr[title]:after{content:" (" attr(title) ")"}.ir a:after,a[href^="javascript:"]:after,a[href^="#"]:after{content:""}pre,blockquote{border:1px solid #999;page-break-inside:avoid}thead{display:table-header-group}tr,img{page-break-inside:avoid}img{max-width:100% !important}@page{margin:0.5cm}p,h2,h3{orphans:3;widows:3}h1,h2,h3,h4,h5,h6{page-break-after:avoid}}</style>
-<script async src="https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.7/latest.js?config=TeX-AMS_CHTML" integrity="sha256-kZafAc6mZvK3W3v1pHOcUix30OHQN6pU/NO2oFkqZVw=" crossorigin></script>
-<script defer src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/highlight.min.js" integrity="sha256-Uv3H6lx7dJmRfRvH8TH6kJD1TSK1aFcwgx+mdg3epi8=" crossorigin></script>
-<script>window.addEventListener('DOMContentLoaded', () => hljs.initHighlighting())</script>
-</head>
-<body>
-<main>
-<article id="content">
-<header>
-<h1 class="title">Module <code>openunmix.transforms</code></h1>
-</header>
-<section id="section-intro">
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/transforms.py#L0-L208" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">from typing import Optional
-
-import torch
-import torchaudio
-from torch import Tensor
-import torch.nn as nn
-
-try:
- from asteroid_filterbanks.enc_dec import Encoder, Decoder
- from asteroid_filterbanks.transforms import to_torchaudio, from_torchaudio
- from asteroid_filterbanks import torch_stft_fb
-except ImportError:
- pass
-
-
-def make_filterbanks(n_fft=4096, n_hop=1024, center=False, sample_rate=44100.0, method="torch"):
- window = nn.Parameter(torch.hann_window(n_fft), requires_grad=False)
-
- if method == "torch":
- encoder = TorchSTFT(n_fft=n_fft, n_hop=n_hop, window=window, center=center)
- decoder = TorchISTFT(n_fft=n_fft, n_hop=n_hop, window=window, center=center)
- elif method == "asteroid":
- fb = torch_stft_fb.TorchSTFTFB.from_torch_args(
- n_fft=n_fft,
- hop_length=n_hop,
- win_length=n_fft,
- window=window,
- center=center,
- sample_rate=sample_rate,
- )
- encoder = AsteroidSTFT(fb)
- decoder = AsteroidISTFT(fb)
- else:
- raise NotImplementedError
- return encoder, decoder
-
-
-class AsteroidSTFT(nn.Module):
- def __init__(self, fb):
- super(AsteroidSTFT, self).__init__()
- self.enc = Encoder(fb)
-
- def forward(self, x):
- aux = self.enc(x)
- return to_torchaudio(aux)
-
-
-class AsteroidISTFT(nn.Module):
- def __init__(self, fb):
- super(AsteroidISTFT, self).__init__()
- self.dec = Decoder(fb)
-
- def forward(self, X: Tensor, length: Optional[int] = None) -> Tensor:
- aux = from_torchaudio(X)
- return self.dec(aux, length=length)
-
-
-class TorchSTFT(nn.Module):
- """Multichannel Short-Time-Fourier Forward transform
- uses hard coded hann_window.
- Args:
- n_fft (int, optional): transform FFT size. Defaults to 4096.
- n_hop (int, optional): transform hop size. Defaults to 1024.
- center (bool, optional): If True, the signals first window is
- zero padded. Centering is required for a perfect
- reconstruction of the signal. However, during training
- of spectrogram models, it can safely turned off.
- Defaults to `true`
- window (nn.Parameter, optional): window function
- """
-
- def __init__(self, n_fft=4096, n_hop=1024, center=False, window=None):
- super(TorchSTFT, self).__init__()
- if window is not None:
- self.window = nn.Parameter(torch.hann_window(n_fft), requires_grad=False)
- else:
- self.window = window
- self.n_fft = n_fft
- self.n_hop = n_hop
- self.center = center
-
- def forward(self, x: Tensor) -> Tensor:
- """STFT forward path
- Args:
- x (Tensor): audio waveform of
- shape (nb_samples, nb_channels, nb_timesteps)
- Returns:
- STFT (Tensor): complex stft of
- shape (nb_samples, nb_channels, nb_bins, nb_frames, complex=2)
- last axis is stacked real and imaginary
- """
-
- shape = x.size()
- nb_samples, nb_channels, nb_timesteps = shape
-
- # pack batch
- x = x.view(-1, shape[-1])
-
- stft_f = torch.stft(
- x,
- n_fft=self.n_fft,
- hop_length=self.n_hop,
- window=self.window,
- center=self.center,
- normalized=False,
- onesided=True,
- pad_mode="reflect",
- )
-
- # unpack batch
- stft_f = stft_f.view(shape[:-1] + stft_f.shape[-3:])
- return stft_f
-
-
-class TorchISTFT(nn.Module):
- """Multichannel Inverse-Short-Time-Fourier functional
- wrapper for torch.istft to support batches
- Args:
- STFT (Tensor): complex stft of
- shape (nb_samples, nb_channels, nb_bins, nb_frames, complex=2)
- last axis is stacked real and imaginary
- n_fft (int, optional): transform FFT size. Defaults to 4096.
- n_hop (int, optional): transform hop size. Defaults to 1024.
- window (callable, optional): window function
- center (bool, optional): If True, the signals first window is
- zero padded. Centering is required for a perfect
- reconstruction of the signal. However, during training
- of spectrogram models, it can safely turned off.
- Defaults to `true`
- length (int, optional): audio signal length to crop the signal
- Returns:
- x (Tensor): audio waveform of
- shape (nb_samples, nb_channels, nb_timesteps)
- """
-
- def __init__(
- self,
- n_fft: int = 4096,
- n_hop: int = 1024,
- center: bool = False,
- sample_rate: float = 44100.0,
- window: Optional[nn.Parameter] = None,
- ) -> None:
- super(TorchISTFT, self).__init__()
-
- self.n_fft = n_fft
- self.n_hop = n_hop
- self.center = center
- self.sample_rate = sample_rate
-
- if window is not None:
- self.window = nn.Parameter(torch.hann_window(n_fft), requires_grad=False)
- else:
- self.window = window
-
- def forward(self, X: Tensor, length: Optional[int] = None) -> Tensor:
- shape = X.size()
- X = X.reshape(-1, shape[-3], shape[-2], shape[-1])
-
- y = torch.istft(
- X,
- n_fft=self.n_fft,
- hop_length=self.n_hop,
- window=self.window,
- center=self.center,
- normalized=False,
- onesided=True,
- length=length,
- )
-
- y = y.reshape(shape[:-3] + y.shape[-1:])
-
- return y
-
-
-class ComplexNorm(nn.Module):
- r"""Compute the norm of complex tensor input.
-
- Extension of `torchaudio.functional.complex_norm` with mono
-
- Args:
- power (float): Power of the norm. (Default: `1.0`).
- mono (bool): Downmix to single channel after applying power norm
- to maximize
- """
-
- def __init__(self, power: float = 1.0, mono: bool = False):
- super(ComplexNorm, self).__init__()
- self.power = power
- self.mono = mono
-
- def forward(self, spec: Tensor) -> Tensor:
- """
- Args:
- spec: complex_tensor (Tensor): Tensor shape of
- `(..., complex=2)`
-
- Returns:
- Tensor: Power/Mag of input
- `(...,)`
- """
- # take the magnitude
- spec = torchaudio.functional.complex_norm(spec, power=self.power)
-
- # downmix in the mag domain to preserve energy
- if self.mono:
- spec = torch.mean(spec, 1, keepdim=True)
-
- return spec</code></pre>
-</details>
-</section>
-<section>
-</section>
-<section>
-</section>
-<section>
-<h2 class="section-title" id="header-functions">Functions</h2>
-<dl>
-<dt id="openunmix.transforms.make_filterbanks"><code class="name flex">
-<span>def <span class="ident">make_filterbanks</span></span>(<span>n_fft=4096, n_hop=1024, center=False, sample_rate=44100.0, method='torch')</span>
-</code></dt>
-<dd>
-<div class="desc"></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/transforms.py#L16-L35" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def make_filterbanks(n_fft=4096, n_hop=1024, center=False, sample_rate=44100.0, method="torch"):
- window = nn.Parameter(torch.hann_window(n_fft), requires_grad=False)
-
- if method == "torch":
- encoder = TorchSTFT(n_fft=n_fft, n_hop=n_hop, window=window, center=center)
- decoder = TorchISTFT(n_fft=n_fft, n_hop=n_hop, window=window, center=center)
- elif method == "asteroid":
- fb = torch_stft_fb.TorchSTFTFB.from_torch_args(
- n_fft=n_fft,
- hop_length=n_hop,
- win_length=n_fft,
- window=window,
- center=center,
- sample_rate=sample_rate,
- )
- encoder = AsteroidSTFT(fb)
- decoder = AsteroidISTFT(fb)
- else:
- raise NotImplementedError
- return encoder, decoder</code></pre>
-</details>
-</dd>
-</dl>
-</section>
-<section>
-<h2 class="section-title" id="header-classes">Classes</h2>
-<dl>
-<dt id="openunmix.transforms.AsteroidISTFT"><code class="flex name class">
-<span>class <span class="ident">AsteroidISTFT</span></span>
-<span>(</span><span>fb)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Base class for all neural network modules.</p>
-<p>Your models should also subclass this class.</p>
-<p>Modules can also contain other Modules, allowing to nest them in
-a tree structure. You can assign the submodules as regular attributes::</p>
-<pre><code>import torch.nn as nn
-import torch.nn.functional as F
-
-class Model(nn.Module):
- def __init__(self):
- super(Model, self).__init__()
- self.conv1 = nn.Conv2d(1, 20, 5)
- self.conv2 = nn.Conv2d(20, 20, 5)
-
- def forward(self, x):
- x = F.relu(self.conv1(x))
- return F.relu(self.conv2(x))
-</code></pre>
-<p>Submodules assigned in this way will be registered, and will have their
-parameters converted too when you call :meth:<code>to</code>, etc.</p>
-<p>:ivar training: Boolean represents whether this module is in training or
-evaluation mode.
-:vartype training: bool</p>
-<p>Initializes internal Module state, shared by both nn.Module and ScriptModule.</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/transforms.py#L48-L55" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class AsteroidISTFT(nn.Module):
- def __init__(self, fb):
- super(AsteroidISTFT, self).__init__()
- self.dec = Decoder(fb)
-
- def forward(self, X: Tensor, length: Optional[int] = None) -> Tensor:
- aux = from_torchaudio(X)
- return self.dec(aux, length=length)</code></pre>
-</details>
-<h3>Ancestors</h3>
-<ul class="hlist">
-<li>torch.nn.modules.module.Module</li>
-</ul>
-<h3>Class variables</h3>
-<dl>
-<dt id="openunmix.transforms.AsteroidISTFT.dump_patches"><code class="name">var <span class="ident">dump_patches</span> :Â bool</code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-<dt id="openunmix.transforms.AsteroidISTFT.training"><code class="name">var <span class="ident">training</span> :Â bool</code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-</dl>
-<h3>Methods</h3>
-<dl>
-<dt id="openunmix.transforms.AsteroidISTFT.forward"><code class="name flex">
-<span>def <span class="ident">forward</span></span>(<span>self, X: torch.Tensor, length: Union[int, NoneType] = None) ‑> torch.Tensor</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Defines the computation performed at every call.</p>
-<p>Should be overridden by all subclasses.</p>
-<div class="admonition note">
-<p class="admonition-title">Note</p>
-<p>Although the recipe for forward pass needs to be defined within
-this function, one should call the :class:<code>Module</code> instance afterwards
-instead of this since the former takes care of running the
-registered hooks while the latter silently ignores them.</p>
-</div></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/transforms.py#L53-L55" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def forward(self, X: Tensor, length: Optional[int] = None) -> Tensor:
- aux = from_torchaudio(X)
- return self.dec(aux, length=length)</code></pre>
-</details>
-</dd>
-</dl>
-</dd>
-<dt id="openunmix.transforms.AsteroidSTFT"><code class="flex name class">
-<span>class <span class="ident">AsteroidSTFT</span></span>
-<span>(</span><span>fb)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Base class for all neural network modules.</p>
-<p>Your models should also subclass this class.</p>
-<p>Modules can also contain other Modules, allowing to nest them in
-a tree structure. You can assign the submodules as regular attributes::</p>
-<pre><code>import torch.nn as nn
-import torch.nn.functional as F
-
-class Model(nn.Module):
- def __init__(self):
- super(Model, self).__init__()
- self.conv1 = nn.Conv2d(1, 20, 5)
- self.conv2 = nn.Conv2d(20, 20, 5)
-
- def forward(self, x):
- x = F.relu(self.conv1(x))
- return F.relu(self.conv2(x))
-</code></pre>
-<p>Submodules assigned in this way will be registered, and will have their
-parameters converted too when you call :meth:<code>to</code>, etc.</p>
-<p>:ivar training: Boolean represents whether this module is in training or
-evaluation mode.
-:vartype training: bool</p>
-<p>Initializes internal Module state, shared by both nn.Module and ScriptModule.</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/transforms.py#L38-L45" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class AsteroidSTFT(nn.Module):
- def __init__(self, fb):
- super(AsteroidSTFT, self).__init__()
- self.enc = Encoder(fb)
-
- def forward(self, x):
- aux = self.enc(x)
- return to_torchaudio(aux)</code></pre>
-</details>
-<h3>Ancestors</h3>
-<ul class="hlist">
-<li>torch.nn.modules.module.Module</li>
-</ul>
-<h3>Class variables</h3>
-<dl>
-<dt id="openunmix.transforms.AsteroidSTFT.dump_patches"><code class="name">var <span class="ident">dump_patches</span> :Â bool</code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-<dt id="openunmix.transforms.AsteroidSTFT.training"><code class="name">var <span class="ident">training</span> :Â bool</code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-</dl>
-<h3>Methods</h3>
-<dl>
-<dt id="openunmix.transforms.AsteroidSTFT.forward"><code class="name flex">
-<span>def <span class="ident">forward</span></span>(<span>self, x) ‑> Callable[..., Any]</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Defines the computation performed at every call.</p>
-<p>Should be overridden by all subclasses.</p>
-<div class="admonition note">
-<p class="admonition-title">Note</p>
-<p>Although the recipe for forward pass needs to be defined within
-this function, one should call the :class:<code>Module</code> instance afterwards
-instead of this since the former takes care of running the
-registered hooks while the latter silently ignores them.</p>
-</div></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/transforms.py#L43-L45" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def forward(self, x):
- aux = self.enc(x)
- return to_torchaudio(aux)</code></pre>
-</details>
-</dd>
-</dl>
-</dd>
-<dt id="openunmix.transforms.ComplexNorm"><code class="flex name class">
-<span>class <span class="ident">ComplexNorm</span></span>
-<span>(</span><span>power: float = 1.0, mono: bool = False)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Compute the norm of complex tensor input.</p>
-<p>Extension of <code>torchaudio.functional.complex_norm</code> with mono</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>power</code></strong> : <code>float</code></dt>
-<dd>Power of the norm. (Default: <code>1.0</code>).</dd>
-<dt><strong><code>mono</code></strong> : <code>bool</code></dt>
-<dd>Downmix to single channel after applying power norm
-to maximize</dd>
-</dl>
-<p>Initializes internal Module state, shared by both nn.Module and ScriptModule.</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/transforms.py#L176-L209" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class ComplexNorm(nn.Module):
- r"""Compute the norm of complex tensor input.
-
- Extension of `torchaudio.functional.complex_norm` with mono
-
- Args:
- power (float): Power of the norm. (Default: `1.0`).
- mono (bool): Downmix to single channel after applying power norm
- to maximize
- """
-
- def __init__(self, power: float = 1.0, mono: bool = False):
- super(ComplexNorm, self).__init__()
- self.power = power
- self.mono = mono
-
- def forward(self, spec: Tensor) -> Tensor:
- """
- Args:
- spec: complex_tensor (Tensor): Tensor shape of
- `(..., complex=2)`
-
- Returns:
- Tensor: Power/Mag of input
- `(...,)`
- """
- # take the magnitude
- spec = torchaudio.functional.complex_norm(spec, power=self.power)
-
- # downmix in the mag domain to preserve energy
- if self.mono:
- spec = torch.mean(spec, 1, keepdim=True)
-
- return spec</code></pre>
-</details>
-<h3>Ancestors</h3>
-<ul class="hlist">
-<li>torch.nn.modules.module.Module</li>
-</ul>
-<h3>Class variables</h3>
-<dl>
-<dt id="openunmix.transforms.ComplexNorm.dump_patches"><code class="name">var <span class="ident">dump_patches</span> :Â bool</code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-<dt id="openunmix.transforms.ComplexNorm.training"><code class="name">var <span class="ident">training</span> :Â bool</code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-</dl>
-<h3>Methods</h3>
-<dl>
-<dt id="openunmix.transforms.ComplexNorm.forward"><code class="name flex">
-<span>def <span class="ident">forward</span></span>(<span>self, spec: torch.Tensor) ‑> torch.Tensor</span>
-</code></dt>
-<dd>
-<div class="desc"><h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>spec</code></strong></dt>
-<dd>complex_tensor (Tensor): Tensor shape of
-<code>(..., complex=2)</code></dd>
-</dl>
-<h2 id="returns">Returns</h2>
-<dl>
-<dt><code>Tensor</code></dt>
-<dd>Power/Mag of input
-<code>(…,)</code></dd>
-</dl></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/transforms.py#L192-L209" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def forward(self, spec: Tensor) -> Tensor:
- """
- Args:
- spec: complex_tensor (Tensor): Tensor shape of
- `(..., complex=2)`
-
- Returns:
- Tensor: Power/Mag of input
- `(...,)`
- """
- # take the magnitude
- spec = torchaudio.functional.complex_norm(spec, power=self.power)
-
- # downmix in the mag domain to preserve energy
- if self.mono:
- spec = torch.mean(spec, 1, keepdim=True)
-
- return spec</code></pre>
-</details>
-</dd>
-</dl>
-</dd>
-<dt id="openunmix.transforms.TorchISTFT"><code class="flex name class">
-<span>class <span class="ident">TorchISTFT</span></span>
-<span>(</span><span>n_fft: int = 4096, n_hop: int = 1024, center: bool = False, sample_rate: float = 44100.0, window: Union[torch.nn.parameter.Parameter, NoneType] = None)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Multichannel Inverse-Short-Time-Fourier functional
-wrapper for torch.istft to support batches</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>STFT</code></strong> : <code>Tensor</code></dt>
-<dd>complex stft of
-shape (nb_samples, nb_channels, nb_bins, nb_frames, complex=2)
-last axis is stacked real and imaginary</dd>
-<dt><strong><code>n_fft</code></strong> : <code>int</code>, optional</dt>
-<dd>transform FFT size. Defaults to 4096.</dd>
-<dt><strong><code>n_hop</code></strong> : <code>int</code>, optional</dt>
-<dd>transform hop size. Defaults to 1024.</dd>
-<dt><strong><code>window</code></strong> : <code>callable</code>, optional</dt>
-<dd>window function</dd>
-<dt><strong><code>center</code></strong> : <code>bool</code>, optional</dt>
-<dd>If True, the signals first window is
-zero padded. Centering is required for a perfect
-reconstruction of the signal. However, during training
-of spectrogram models, it can safely turned off.
-Defaults to <code>true</code></dd>
-<dt><strong><code>length</code></strong> : <code>int</code>, optional</dt>
-<dd>audio signal length to crop the signal</dd>
-</dl>
-<h2 id="returns">Returns</h2>
-<p>x (Tensor): audio waveform of
-shape (nb_samples, nb_channels, nb_timesteps)
-Initializes internal Module state, shared by both nn.Module and ScriptModule.</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/transforms.py#L115-L173" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class TorchISTFT(nn.Module):
- """Multichannel Inverse-Short-Time-Fourier functional
- wrapper for torch.istft to support batches
- Args:
- STFT (Tensor): complex stft of
- shape (nb_samples, nb_channels, nb_bins, nb_frames, complex=2)
- last axis is stacked real and imaginary
- n_fft (int, optional): transform FFT size. Defaults to 4096.
- n_hop (int, optional): transform hop size. Defaults to 1024.
- window (callable, optional): window function
- center (bool, optional): If True, the signals first window is
- zero padded. Centering is required for a perfect
- reconstruction of the signal. However, during training
- of spectrogram models, it can safely turned off.
- Defaults to `true`
- length (int, optional): audio signal length to crop the signal
- Returns:
- x (Tensor): audio waveform of
- shape (nb_samples, nb_channels, nb_timesteps)
- """
-
- def __init__(
- self,
- n_fft: int = 4096,
- n_hop: int = 1024,
- center: bool = False,
- sample_rate: float = 44100.0,
- window: Optional[nn.Parameter] = None,
- ) -> None:
- super(TorchISTFT, self).__init__()
-
- self.n_fft = n_fft
- self.n_hop = n_hop
- self.center = center
- self.sample_rate = sample_rate
-
- if window is not None:
- self.window = nn.Parameter(torch.hann_window(n_fft), requires_grad=False)
- else:
- self.window = window
-
- def forward(self, X: Tensor, length: Optional[int] = None) -> Tensor:
- shape = X.size()
- X = X.reshape(-1, shape[-3], shape[-2], shape[-1])
-
- y = torch.istft(
- X,
- n_fft=self.n_fft,
- hop_length=self.n_hop,
- window=self.window,
- center=self.center,
- normalized=False,
- onesided=True,
- length=length,
- )
-
- y = y.reshape(shape[:-3] + y.shape[-1:])
-
- return y</code></pre>
-</details>
-<h3>Ancestors</h3>
-<ul class="hlist">
-<li>torch.nn.modules.module.Module</li>
-</ul>
-<h3>Class variables</h3>
-<dl>
-<dt id="openunmix.transforms.TorchISTFT.dump_patches"><code class="name">var <span class="ident">dump_patches</span> :Â bool</code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-<dt id="openunmix.transforms.TorchISTFT.training"><code class="name">var <span class="ident">training</span> :Â bool</code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-</dl>
-<h3>Methods</h3>
-<dl>
-<dt id="openunmix.transforms.TorchISTFT.forward"><code class="name flex">
-<span>def <span class="ident">forward</span></span>(<span>self, X: torch.Tensor, length: Union[int, NoneType] = None) ‑> torch.Tensor</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Defines the computation performed at every call.</p>
-<p>Should be overridden by all subclasses.</p>
-<div class="admonition note">
-<p class="admonition-title">Note</p>
-<p>Although the recipe for forward pass needs to be defined within
-this function, one should call the :class:<code>Module</code> instance afterwards
-instead of this since the former takes care of running the
-registered hooks while the latter silently ignores them.</p>
-</div></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/transforms.py#L156-L173" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def forward(self, X: Tensor, length: Optional[int] = None) -> Tensor:
- shape = X.size()
- X = X.reshape(-1, shape[-3], shape[-2], shape[-1])
-
- y = torch.istft(
- X,
- n_fft=self.n_fft,
- hop_length=self.n_hop,
- window=self.window,
- center=self.center,
- normalized=False,
- onesided=True,
- length=length,
- )
-
- y = y.reshape(shape[:-3] + y.shape[-1:])
-
- return y</code></pre>
-</details>
-</dd>
-</dl>
-</dd>
-<dt id="openunmix.transforms.TorchSTFT"><code class="flex name class">
-<span>class <span class="ident">TorchSTFT</span></span>
-<span>(</span><span>n_fft=4096, n_hop=1024, center=False, window=None)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Multichannel Short-Time-Fourier Forward transform
-uses hard coded hann_window.</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>n_fft</code></strong> : <code>int</code>, optional</dt>
-<dd>transform FFT size. Defaults to 4096.</dd>
-<dt><strong><code>n_hop</code></strong> : <code>int</code>, optional</dt>
-<dd>transform hop size. Defaults to 1024.</dd>
-<dt><strong><code>center</code></strong> : <code>bool</code>, optional</dt>
-<dd>If True, the signals first window is
-zero padded. Centering is required for a perfect
-reconstruction of the signal. However, during training
-of spectrogram models, it can safely turned off.
-Defaults to <code>true</code></dd>
-<dt><strong><code>window</code></strong> : <code>nn.Parameter</code>, optional</dt>
-<dd>window function</dd>
-</dl>
-<p>Initializes internal Module state, shared by both nn.Module and ScriptModule.</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/transforms.py#L58-L112" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class TorchSTFT(nn.Module):
- """Multichannel Short-Time-Fourier Forward transform
- uses hard coded hann_window.
- Args:
- n_fft (int, optional): transform FFT size. Defaults to 4096.
- n_hop (int, optional): transform hop size. Defaults to 1024.
- center (bool, optional): If True, the signals first window is
- zero padded. Centering is required for a perfect
- reconstruction of the signal. However, during training
- of spectrogram models, it can safely turned off.
- Defaults to `true`
- window (nn.Parameter, optional): window function
- """
-
- def __init__(self, n_fft=4096, n_hop=1024, center=False, window=None):
- super(TorchSTFT, self).__init__()
- if window is not None:
- self.window = nn.Parameter(torch.hann_window(n_fft), requires_grad=False)
- else:
- self.window = window
- self.n_fft = n_fft
- self.n_hop = n_hop
- self.center = center
-
- def forward(self, x: Tensor) -> Tensor:
- """STFT forward path
- Args:
- x (Tensor): audio waveform of
- shape (nb_samples, nb_channels, nb_timesteps)
- Returns:
- STFT (Tensor): complex stft of
- shape (nb_samples, nb_channels, nb_bins, nb_frames, complex=2)
- last axis is stacked real and imaginary
- """
-
- shape = x.size()
- nb_samples, nb_channels, nb_timesteps = shape
-
- # pack batch
- x = x.view(-1, shape[-1])
-
- stft_f = torch.stft(
- x,
- n_fft=self.n_fft,
- hop_length=self.n_hop,
- window=self.window,
- center=self.center,
- normalized=False,
- onesided=True,
- pad_mode="reflect",
- )
-
- # unpack batch
- stft_f = stft_f.view(shape[:-1] + stft_f.shape[-3:])
- return stft_f</code></pre>
-</details>
-<h3>Ancestors</h3>
-<ul class="hlist">
-<li>torch.nn.modules.module.Module</li>
-</ul>
-<h3>Class variables</h3>
-<dl>
-<dt id="openunmix.transforms.TorchSTFT.dump_patches"><code class="name">var <span class="ident">dump_patches</span> :Â bool</code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-<dt id="openunmix.transforms.TorchSTFT.training"><code class="name">var <span class="ident">training</span> :Â bool</code></dt>
-<dd>
-<div class="desc"></div>
-</dd>
-</dl>
-<h3>Methods</h3>
-<dl>
-<dt id="openunmix.transforms.TorchSTFT.forward"><code class="name flex">
-<span>def <span class="ident">forward</span></span>(<span>self, x: torch.Tensor) ‑> torch.Tensor</span>
-</code></dt>
-<dd>
-<div class="desc"><p>STFT forward path</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>x</code></strong> : <code>Tensor</code></dt>
-<dd>audio waveform of
-shape (nb_samples, nb_channels, nb_timesteps)</dd>
-</dl>
-<h2 id="returns">Returns</h2>
-<p>STFT (Tensor): complex stft of
-shape (nb_samples, nb_channels, nb_bins, nb_frames, complex=2)
-last axis is stacked real and imaginary</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/transforms.py#L82-L112" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def forward(self, x: Tensor) -> Tensor:
- """STFT forward path
- Args:
- x (Tensor): audio waveform of
- shape (nb_samples, nb_channels, nb_timesteps)
- Returns:
- STFT (Tensor): complex stft of
- shape (nb_samples, nb_channels, nb_bins, nb_frames, complex=2)
- last axis is stacked real and imaginary
- """
-
- shape = x.size()
- nb_samples, nb_channels, nb_timesteps = shape
-
- # pack batch
- x = x.view(-1, shape[-1])
-
- stft_f = torch.stft(
- x,
- n_fft=self.n_fft,
- hop_length=self.n_hop,
- window=self.window,
- center=self.center,
- normalized=False,
- onesided=True,
- pad_mode="reflect",
- )
-
- # unpack batch
- stft_f = stft_f.view(shape[:-1] + stft_f.shape[-3:])
- return stft_f</code></pre>
-</details>
-</dd>
-</dl>
-</dd>
-</dl>
-</section>
-</article>
-<nav id="sidebar">
-<h1>Index</h1>
-<div class="toc">
-<ul></ul>
-</div>
-<ul id="index">
-<li><h3>Super-module</h3>
-<ul>
-<li><code><a title="openunmix" href="index.html">openunmix</a></code></li>
-</ul>
-</li>
-<li><h3><a href="#header-functions">Functions</a></h3>
-<ul class="">
-<li><code><a title="openunmix.transforms.make_filterbanks" href="#openunmix.transforms.make_filterbanks">make_filterbanks</a></code></li>
-</ul>
-</li>
-<li><h3><a href="#header-classes">Classes</a></h3>
-<ul>
-<li>
-<h4><code><a title="openunmix.transforms.AsteroidISTFT" href="#openunmix.transforms.AsteroidISTFT">AsteroidISTFT</a></code></h4>
-<ul class="">
-<li><code><a title="openunmix.transforms.AsteroidISTFT.dump_patches" href="#openunmix.transforms.AsteroidISTFT.dump_patches">dump_patches</a></code></li>
-<li><code><a title="openunmix.transforms.AsteroidISTFT.forward" href="#openunmix.transforms.AsteroidISTFT.forward">forward</a></code></li>
-<li><code><a title="openunmix.transforms.AsteroidISTFT.training" href="#openunmix.transforms.AsteroidISTFT.training">training</a></code></li>
-</ul>
-</li>
-<li>
-<h4><code><a title="openunmix.transforms.AsteroidSTFT" href="#openunmix.transforms.AsteroidSTFT">AsteroidSTFT</a></code></h4>
-<ul class="">
-<li><code><a title="openunmix.transforms.AsteroidSTFT.dump_patches" href="#openunmix.transforms.AsteroidSTFT.dump_patches">dump_patches</a></code></li>
-<li><code><a title="openunmix.transforms.AsteroidSTFT.forward" href="#openunmix.transforms.AsteroidSTFT.forward">forward</a></code></li>
-<li><code><a title="openunmix.transforms.AsteroidSTFT.training" href="#openunmix.transforms.AsteroidSTFT.training">training</a></code></li>
-</ul>
-</li>
-<li>
-<h4><code><a title="openunmix.transforms.ComplexNorm" href="#openunmix.transforms.ComplexNorm">ComplexNorm</a></code></h4>
-<ul class="">
-<li><code><a title="openunmix.transforms.ComplexNorm.dump_patches" href="#openunmix.transforms.ComplexNorm.dump_patches">dump_patches</a></code></li>
-<li><code><a title="openunmix.transforms.ComplexNorm.forward" href="#openunmix.transforms.ComplexNorm.forward">forward</a></code></li>
-<li><code><a title="openunmix.transforms.ComplexNorm.training" href="#openunmix.transforms.ComplexNorm.training">training</a></code></li>
-</ul>
-</li>
-<li>
-<h4><code><a title="openunmix.transforms.TorchISTFT" href="#openunmix.transforms.TorchISTFT">TorchISTFT</a></code></h4>
-<ul class="">
-<li><code><a title="openunmix.transforms.TorchISTFT.dump_patches" href="#openunmix.transforms.TorchISTFT.dump_patches">dump_patches</a></code></li>
-<li><code><a title="openunmix.transforms.TorchISTFT.forward" href="#openunmix.transforms.TorchISTFT.forward">forward</a></code></li>
-<li><code><a title="openunmix.transforms.TorchISTFT.training" href="#openunmix.transforms.TorchISTFT.training">training</a></code></li>
-</ul>
-</li>
-<li>
-<h4><code><a title="openunmix.transforms.TorchSTFT" href="#openunmix.transforms.TorchSTFT">TorchSTFT</a></code></h4>
-<ul class="">
-<li><code><a title="openunmix.transforms.TorchSTFT.dump_patches" href="#openunmix.transforms.TorchSTFT.dump_patches">dump_patches</a></code></li>
-<li><code><a title="openunmix.transforms.TorchSTFT.forward" href="#openunmix.transforms.TorchSTFT.forward">forward</a></code></li>
-<li><code><a title="openunmix.transforms.TorchSTFT.training" href="#openunmix.transforms.TorchSTFT.training">training</a></code></li>
-</ul>
-</li>
-</ul>
-</li>
-</ul>
-</nav>
-</main>
-<footer id="footer">
-<p>Generated by <a href="https://pdoc3.github.io/pdoc"><cite>pdoc</cite> 0.9.2</a>.</p>
-</footer>
-</body>
-</html>
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/utils.html b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/utils.html
deleted file mode 100644
index b9d33da73d5433280c020b66cf9e41a7dcc50a6e..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/docs/utils.html
+++ /dev/null
@@ -1,926 +0,0 @@
-<!doctype html>
-<html lang="en">
-<head>
-<meta charset="utf-8">
-<meta name="viewport" content="width=device-width, initial-scale=1, minimum-scale=1" />
-<meta name="generator" content="pdoc 0.9.2" />
-<title>openunmix.utils API documentation</title>
-<meta name="description" content="" />
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/sanitize.min.css" integrity="sha256-PK9q560IAAa6WVRRh76LtCaI8pjTJ2z11v0miyNNjrs=" crossorigin>
-<link rel="preload stylesheet" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/10up-sanitize.css/11.0.1/typography.min.css" integrity="sha256-7l/o7C8jubJiy74VsKTidCy1yBkRtiUGbVkYBylBqUg=" crossorigin>
-<link rel="stylesheet preload" as="style" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/styles/github.min.css" crossorigin>
-<style>:root{--highlight-color:#fe9}.flex{display:flex !important}body{line-height:1.5em}#content{padding:20px}#sidebar{padding:30px;overflow:hidden}#sidebar > *:last-child{margin-bottom:2cm}.http-server-breadcrumbs{font-size:130%;margin:0 0 15px 0}#footer{font-size:.75em;padding:5px 30px;border-top:1px solid #ddd;text-align:right}#footer p{margin:0 0 0 1em;display:inline-block}#footer p:last-child{margin-right:30px}h1,h2,h3,h4,h5{font-weight:300}h1{font-size:2.5em;line-height:1.1em}h2{font-size:1.75em;margin:1em 0 .50em 0}h3{font-size:1.4em;margin:25px 0 10px 0}h4{margin:0;font-size:105%}h1:target,h2:target,h3:target,h4:target,h5:target,h6:target{background:var(--highlight-color);padding:.2em 0}a{color:#058;text-decoration:none;transition:color .3s ease-in-out}a:hover{color:#e82}.title code{font-weight:bold}h2[id^="header-"]{margin-top:2em}.ident{color:#900}pre code{background:#f8f8f8;font-size:.8em;line-height:1.4em}code{background:#f2f2f1;padding:1px 4px;overflow-wrap:break-word}h1 code{background:transparent}pre{background:#f8f8f8;border:0;border-top:1px solid #ccc;border-bottom:1px solid #ccc;margin:1em 0;padding:1ex}#http-server-module-list{display:flex;flex-flow:column}#http-server-module-list div{display:flex}#http-server-module-list dt{min-width:10%}#http-server-module-list p{margin-top:0}.toc ul,#index{list-style-type:none;margin:0;padding:0}#index code{background:transparent}#index h3{border-bottom:1px solid #ddd}#index ul{padding:0}#index h4{margin-top:.6em;font-weight:bold}@media (min-width:200ex){#index .two-column{column-count:2}}@media (min-width:300ex){#index .two-column{column-count:3}}dl{margin-bottom:2em}dl dl:last-child{margin-bottom:4em}dd{margin:0 0 1em 3em}#header-classes + dl > dd{margin-bottom:3em}dd dd{margin-left:2em}dd p{margin:10px 0}.name{background:#eee;font-weight:bold;font-size:.85em;padding:5px 10px;display:inline-block;min-width:40%}.name:hover{background:#e0e0e0}dt:target .name{background:var(--highlight-color)}.name > span:first-child{white-space:nowrap}.name.class > span:nth-child(2){margin-left:.4em}.inherited{color:#999;border-left:5px solid #eee;padding-left:1em}.inheritance em{font-style:normal;font-weight:bold}.desc h2{font-weight:400;font-size:1.25em}.desc h3{font-size:1em}.desc dt code{background:inherit}.source summary,.git-link-div{color:#666;text-align:right;font-weight:400;font-size:.8em;text-transform:uppercase}.source summary > *{white-space:nowrap;cursor:pointer}.git-link{color:inherit;margin-left:1em}.source pre{max-height:500px;overflow:auto;margin:0}.source pre code{font-size:12px;overflow:visible}.hlist{list-style:none}.hlist li{display:inline}.hlist li:after{content:',\2002'}.hlist li:last-child:after{content:none}.hlist .hlist{display:inline;padding-left:1em}img{max-width:100%}td{padding:0 .5em}.admonition{padding:.1em .5em;margin-bottom:1em}.admonition-title{font-weight:bold}.admonition.note,.admonition.info,.admonition.important{background:#aef}.admonition.todo,.admonition.versionadded,.admonition.tip,.admonition.hint{background:#dfd}.admonition.warning,.admonition.versionchanged,.admonition.deprecated{background:#fd4}.admonition.error,.admonition.danger,.admonition.caution{background:lightpink}</style>
-<style media="screen and (min-width: 700px)">@media screen and (min-width:700px){#sidebar{width:30%;height:100vh;overflow:auto;position:sticky;top:0}#content{width:70%;max-width:100ch;padding:3em 4em;border-left:1px solid #ddd}pre code{font-size:1em}.item .name{font-size:1em}main{display:flex;flex-direction:row-reverse;justify-content:flex-end}.toc ul ul,#index ul{padding-left:1.5em}.toc > ul > li{margin-top:.5em}}</style>
-<style media="print">@media print{#sidebar h1{page-break-before:always}.source{display:none}}@media print{*{background:transparent !important;color:#000 !important;box-shadow:none !important;text-shadow:none !important}a[href]:after{content:" (" attr(href) ")";font-size:90%}a[href][title]:after{content:none}abbr[title]:after{content:" (" attr(title) ")"}.ir a:after,a[href^="javascript:"]:after,a[href^="#"]:after{content:""}pre,blockquote{border:1px solid #999;page-break-inside:avoid}thead{display:table-header-group}tr,img{page-break-inside:avoid}img{max-width:100% !important}@page{margin:0.5cm}p,h2,h3{orphans:3;widows:3}h1,h2,h3,h4,h5,h6{page-break-after:avoid}}</style>
-<script async src="https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.7/latest.js?config=TeX-AMS_CHTML" integrity="sha256-kZafAc6mZvK3W3v1pHOcUix30OHQN6pU/NO2oFkqZVw=" crossorigin></script>
-<script defer src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.1.1/highlight.min.js" integrity="sha256-Uv3H6lx7dJmRfRvH8TH6kJD1TSK1aFcwgx+mdg3epi8=" crossorigin></script>
-<script>window.addEventListener('DOMContentLoaded', () => hljs.initHighlighting())</script>
-</head>
-<body>
-<main>
-<article id="content">
-<header>
-<h1 class="title">Module <code>openunmix.utils</code></h1>
-</header>
-<section id="section-intro">
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/utils.py#L0-L304" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">from typing import Optional, Union
-
-import torch
-import os
-import numpy as np
-import torchaudio
-import warnings
-from pathlib import Path
-from contextlib import redirect_stderr
-import io
-import json
-
-import openunmix
-from openunmix import model
-
-
-def bandwidth_to_max_bin(rate: float, n_fft: int, bandwidth: float) -> np.ndarray:
- """Convert bandwidth to maximum bin count
-
- Assuming lapped transforms such as STFT
-
- Args:
- rate (int): Sample rate
- n_fft (int): FFT length
- bandwidth (float): Target bandwidth in Hz
-
- Returns:
- np.ndarray: maximum frequency bin
- """
- freqs = np.linspace(0, rate / 2, n_fft // 2 + 1, endpoint=True)
-
- return np.max(np.where(freqs <= bandwidth)[0]) + 1
-
-
-def save_checkpoint(state: dict, is_best: bool, path: str, target: str):
- """Convert bandwidth to maximum bin count
-
- Assuming lapped transforms such as STFT
-
- Args:
- state (dict): torch model state dict
- is_best (bool): if current model is about to be saved as best model
- path (str): model path
- target (str): target name
- """
- # save full checkpoint including optimizer
- torch.save(state, os.path.join(path, target + ".chkpnt"))
- if is_best:
- # save just the weights
- torch.save(state["state_dict"], os.path.join(path, target + ".pth"))
-
-
-class AverageMeter(object):
- """Computes and stores the average and current value"""
-
- def __init__(self):
- self.reset()
-
- def reset(self):
- self.val = 0
- self.avg = 0
- self.sum = 0
- self.count = 0
-
- def update(self, val, n=1):
- self.val = val
- self.sum += val * n
- self.count += n
- self.avg = self.sum / self.count
-
-
-class EarlyStopping(object):
- """Early Stopping Monitor"""
-
- def __init__(self, mode="min", min_delta=0, patience=10):
- self.mode = mode
- self.min_delta = min_delta
- self.patience = patience
- self.best = None
- self.num_bad_epochs = 0
- self.is_better = None
- self._init_is_better(mode, min_delta)
-
- if patience == 0:
- self.is_better = lambda a, b: True
-
- def step(self, metrics):
- if self.best is None:
- self.best = metrics
- return False
-
- if np.isnan(metrics):
- return True
-
- if self.is_better(metrics, self.best):
- self.num_bad_epochs = 0
- self.best = metrics
- else:
- self.num_bad_epochs += 1
-
- if self.num_bad_epochs >= self.patience:
- return True
-
- return False
-
- def _init_is_better(self, mode, min_delta):
- if mode not in {"min", "max"}:
- raise ValueError("mode " + mode + " is unknown!")
- if mode == "min":
- self.is_better = lambda a, best: a < best - min_delta
- if mode == "max":
- self.is_better = lambda a, best: a > best + min_delta
-
-
-def load_target_models(targets, model_str_or_path="umxhq", device="cpu", pretrained=True):
- """Core model loader
-
- target model path can be either <target>.pth, or <target>-sha256.pth
- (as used on torchub)
-
- The loader either loads the models from a known model string
- as registered in the __init__.py or loads from custom configs.
- """
- if isinstance(targets, str):
- targets = [targets]
-
- model_path = Path(model_str_or_path).expanduser()
- if not model_path.exists():
- # model path does not exist, use pretrained models
- try:
- # disable progress bar
- hub_loader = getattr(openunmix, model_str_or_path + "_spec")
- err = io.StringIO()
- with redirect_stderr(err):
- return hub_loader(targets=targets, device=device, pretrained=pretrained)
- print(err.getvalue())
- except AttributeError:
- raise NameError("Model does not exist on torchhub")
- # assume model is a path to a local model_str_or_path directory
- else:
- models = {}
- for target in targets:
- # load model from disk
- with open(Path(model_path, target + ".json"), "r") as stream:
- results = json.load(stream)
-
- target_model_path = next(Path(model_path).glob("%s*.pth" % target))
- state = torch.load(target_model_path, map_location=device)
-
- models[target] = model.OpenUnmix(
- nb_bins=results["args"]["nfft"] // 2 + 1,
- nb_channels=results["args"]["nb_channels"],
- hidden_size=results["args"]["hidden_size"],
- max_bin=state["input_mean"].shape[0],
- )
-
- if pretrained:
- models[target].load_state_dict(state, strict=False)
-
- models[target].to(device)
- return models
-
-
-def load_separator(
- model_str_or_path: str = "umxhq",
- targets: Optional[list] = None,
- niter: int = 1,
- residual: bool = False,
- wiener_win_len: Optional[int] = 300,
- device: Union[str, torch.device] = "cpu",
- pretrained: bool = True,
- filterbank: str = "torch",
-):
- """Separator loader
-
- Args:
- model_str_or_path (str): Model name or path to model _parent_ directory
- E.g. The following files are assumed to present when
- loading `model_str_or_path='mymodel', targets=['vocals']`
- 'mymodel/separator.json', mymodel/vocals.pth', 'mymodel/vocals.json'.
- Defaults to `umxhq`.
- targets (list of str or None): list of target names. When loading a
- pre-trained model, all `targets` can be None as all targets
- will be loaded
- niter (int): Number of EM steps for refining initial estimates
- in a post-processing stage. `--niter 0` skips this step altogether
- (and thus makes separation significantly faster) More iterations
- can get better interference reduction at the price of artifacts.
- Defaults to `1`.
- residual (bool): Computes a residual target, for custom separation
- scenarios when not all targets are available (at the expense
- of slightly less performance). E.g vocal/accompaniment
- Defaults to `False`.
- wiener_win_len (int): The size of the excerpts (number of frames) on
- which to apply filtering independently. This means assuming
- time varying stereo models and localization of sources.
- None means not batching but using the whole signal. It comes at the
- price of a much larger memory usage.
- Defaults to `300`
- device (str): torch device, defaults to `cpu`
- pretrained (bool): determines if loading pre-trained weights
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
- """
- model_path = Path(model_str_or_path).expanduser()
-
- # when path exists, we assume its a custom model saved locally
- if model_path.exists():
- if targets is None:
- raise UserWarning("For custom models, please specify the targets")
-
- target_models = load_target_models(
- targets=targets, model_str_or_path=model_path, pretrained=pretrained
- )
-
- with open(Path(model_path, "separator.json"), "r") as stream:
- enc_conf = json.load(stream)
-
- separator = model.Separator(
- target_models=target_models,
- niter=niter,
- residual=residual,
- wiener_win_len=wiener_win_len,
- sample_rate=enc_conf["sample_rate"],
- n_fft=enc_conf["nfft"],
- n_hop=enc_conf["nhop"],
- nb_channels=enc_conf["nb_channels"],
- filterbank=filterbank,
- ).to(device)
-
- # otherwise we load the separator from torchhub
- else:
- hub_loader = getattr(openunmix, model_str_or_path)
- separator = hub_loader(
- targets=targets,
- device=device,
- pretrained=True,
- niter=niter,
- residual=residual,
- filterbank=filterbank,
- )
-
- return separator
-
-
-def preprocess(
- audio: torch.Tensor,
- rate: Optional[float] = None,
- model_rate: Optional[float] = None,
-) -> torch.Tensor:
- """
- From an input tensor, convert it to a tensor of shape
- shape=(nb_samples, nb_channels, nb_timesteps). This includes:
- - if input is 1D, adding the samples and channels dimensions.
- - if input is 2D
- o and the smallest dimension is 1 or 2, adding the samples one.
- o and all dimensions are > 2, assuming the smallest is the samples
- one, and adding the channel one
- - at the end, if the number of channels is greater than the number
- of time steps, swap those two.
- - resampling to target rate if necessary
-
- Args:
- audio (Tensor): input waveform
- rate (float): sample rate for the audio
- model_rate (float): sample rate for the model
-
- Returns:
- Tensor: [shape=(nb_samples, nb_channels=2, nb_timesteps)]
- """
- shape = torch.as_tensor(audio.shape, device=audio.device)
-
- if len(shape) == 1:
- # assuming only time dimension is provided.
- audio = audio[None, None, ...]
- elif len(shape) == 2:
- if shape.min() <= 2:
- # assuming sample dimension is missing
- audio = audio[None, ...]
- else:
- # assuming channel dimension is missing
- audio = audio[:, None, ...]
- if audio.shape[1] > audio.shape[2]:
- # swapping channel and time
- audio = audio.transpose(1, 2)
- if audio.shape[1] > 2:
- warnings.warn("Channel count > 2!. Only the first two channels " "will be processed!")
- audio = audio[..., :2]
-
- if audio.shape[1] == 1:
- # if we have mono, we duplicate it to get stereo
- audio = torch.repeat_interleave(audio, 2, dim=1)
-
- if rate != model_rate:
- print("resampling")
- # we have to resample to model samplerate if needed
- # this makes sure we resample input only once
- resampler = torchaudio.transforms.Resample(
- orig_freq=rate, new_freq=model_rate, resampling_method="sinc_interpolation"
- ).to(audio.device)
- audio = resampler(audio)
- return audio</code></pre>
-</details>
-</section>
-<section>
-</section>
-<section>
-</section>
-<section>
-<h2 class="section-title" id="header-functions">Functions</h2>
-<dl>
-<dt id="openunmix.utils.bandwidth_to_max_bin"><code class="name flex">
-<span>def <span class="ident">bandwidth_to_max_bin</span></span>(<span>rate: float, n_fft: int, bandwidth: float) ‑> numpy.ndarray</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Convert bandwidth to maximum bin count</p>
-<p>Assuming lapped transforms such as STFT</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>rate</code></strong> : <code>int</code></dt>
-<dd>Sample rate</dd>
-<dt><strong><code>n_fft</code></strong> : <code>int</code></dt>
-<dd>FFT length</dd>
-<dt><strong><code>bandwidth</code></strong> : <code>float</code></dt>
-<dd>Target bandwidth in Hz</dd>
-</dl>
-<h2 id="returns">Returns</h2>
-<dl>
-<dt><code>np.ndarray</code></dt>
-<dd>maximum frequency bin</dd>
-</dl></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/utils.py#L17-L32" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def bandwidth_to_max_bin(rate: float, n_fft: int, bandwidth: float) -> np.ndarray:
- """Convert bandwidth to maximum bin count
-
- Assuming lapped transforms such as STFT
-
- Args:
- rate (int): Sample rate
- n_fft (int): FFT length
- bandwidth (float): Target bandwidth in Hz
-
- Returns:
- np.ndarray: maximum frequency bin
- """
- freqs = np.linspace(0, rate / 2, n_fft // 2 + 1, endpoint=True)
-
- return np.max(np.where(freqs <= bandwidth)[0]) + 1</code></pre>
-</details>
-</dd>
-<dt id="openunmix.utils.load_separator"><code class="name flex">
-<span>def <span class="ident">load_separator</span></span>(<span>model_str_or_path: str = 'umxhq', targets: Union[list, NoneType] = None, niter: int = 1, residual: bool = False, wiener_win_len: Union[int, NoneType] = 300, device: Union[str, torch.device] = 'cpu', pretrained: bool = True, filterbank: str = 'torch')</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Separator loader</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>model_str_or_path</code></strong> : <code>str</code></dt>
-<dd>Model name or path to model <em>parent</em> directory
-E.g. The following files are assumed to present when
-loading <code>model_str_or_path='mymodel', targets=['vocals']</code>
-'mymodel/separator.json', mymodel/vocals.pth', 'mymodel/vocals.json'.
-Defaults to <code>umxhq</code>.</dd>
-<dt><strong><code>targets</code></strong> : <code>list</code> of <code>str</code> or <code>None</code></dt>
-<dd>list of target names. When loading a
-pre-trained model, all <code>targets</code> can be None as all targets
-will be loaded</dd>
-<dt><strong><code>niter</code></strong> : <code>int</code></dt>
-<dd>Number of EM steps for refining initial estimates
-in a post-processing stage. <code>--niter 0</code> skips this step altogether
-(and thus makes separation significantly faster) More iterations
-can get better interference reduction at the price of artifacts.
-Defaults to <code>1</code>.</dd>
-<dt><strong><code>residual</code></strong> : <code>bool</code></dt>
-<dd>Computes a residual target, for custom separation
-scenarios when not all targets are available (at the expense
-of slightly less performance). E.g vocal/accompaniment
-Defaults to <code>False</code>.</dd>
-<dt><strong><code>wiener_win_len</code></strong> : <code>int</code></dt>
-<dd>The size of the excerpts (number of frames) on
-which to apply filtering independently. This means assuming
-time varying stereo models and localization of sources.
-None means not batching but using the whole signal. It comes at the
-price of a much larger memory usage.
-Defaults to <code>300</code></dd>
-<dt><strong><code>device</code></strong> : <code>str</code></dt>
-<dd>torch device, defaults to <code>cpu</code></dd>
-<dt><strong><code>pretrained</code></strong> : <code>bool</code></dt>
-<dd>determines if loading pre-trained weights</dd>
-<dt><strong><code>filterbank</code></strong> : <code>str</code></dt>
-<dd>filterbank implementation method.
-Supported are <code>['torch', 'asteroid']</code>. <code>torch</code> is about 30% faster
-compared to <code>asteroid</code> on large FFT sizes such as 4096. However,
-asteroids stft can be exported to onnx, which makes is practical
-for deployment.</dd>
-</dl></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/utils.py#L164-L246" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def load_separator(
- model_str_or_path: str = "umxhq",
- targets: Optional[list] = None,
- niter: int = 1,
- residual: bool = False,
- wiener_win_len: Optional[int] = 300,
- device: Union[str, torch.device] = "cpu",
- pretrained: bool = True,
- filterbank: str = "torch",
-):
- """Separator loader
-
- Args:
- model_str_or_path (str): Model name or path to model _parent_ directory
- E.g. The following files are assumed to present when
- loading `model_str_or_path='mymodel', targets=['vocals']`
- 'mymodel/separator.json', mymodel/vocals.pth', 'mymodel/vocals.json'.
- Defaults to `umxhq`.
- targets (list of str or None): list of target names. When loading a
- pre-trained model, all `targets` can be None as all targets
- will be loaded
- niter (int): Number of EM steps for refining initial estimates
- in a post-processing stage. `--niter 0` skips this step altogether
- (and thus makes separation significantly faster) More iterations
- can get better interference reduction at the price of artifacts.
- Defaults to `1`.
- residual (bool): Computes a residual target, for custom separation
- scenarios when not all targets are available (at the expense
- of slightly less performance). E.g vocal/accompaniment
- Defaults to `False`.
- wiener_win_len (int): The size of the excerpts (number of frames) on
- which to apply filtering independently. This means assuming
- time varying stereo models and localization of sources.
- None means not batching but using the whole signal. It comes at the
- price of a much larger memory usage.
- Defaults to `300`
- device (str): torch device, defaults to `cpu`
- pretrained (bool): determines if loading pre-trained weights
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
- """
- model_path = Path(model_str_or_path).expanduser()
-
- # when path exists, we assume its a custom model saved locally
- if model_path.exists():
- if targets is None:
- raise UserWarning("For custom models, please specify the targets")
-
- target_models = load_target_models(
- targets=targets, model_str_or_path=model_path, pretrained=pretrained
- )
-
- with open(Path(model_path, "separator.json"), "r") as stream:
- enc_conf = json.load(stream)
-
- separator = model.Separator(
- target_models=target_models,
- niter=niter,
- residual=residual,
- wiener_win_len=wiener_win_len,
- sample_rate=enc_conf["sample_rate"],
- n_fft=enc_conf["nfft"],
- n_hop=enc_conf["nhop"],
- nb_channels=enc_conf["nb_channels"],
- filterbank=filterbank,
- ).to(device)
-
- # otherwise we load the separator from torchhub
- else:
- hub_loader = getattr(openunmix, model_str_or_path)
- separator = hub_loader(
- targets=targets,
- device=device,
- pretrained=True,
- niter=niter,
- residual=residual,
- filterbank=filterbank,
- )
-
- return separator</code></pre>
-</details>
-</dd>
-<dt id="openunmix.utils.load_target_models"><code class="name flex">
-<span>def <span class="ident">load_target_models</span></span>(<span>targets, model_str_or_path='umxhq', device='cpu', pretrained=True)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Core model loader</p>
-<p>target model path can be either <target>.pth, or <target>-sha256.pth
-(as used on torchub)</p>
-<p>The loader either loads the models from a known model string
-as registered in the <strong>init</strong>.py or loads from custom configs.</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/utils.py#L115-L161" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def load_target_models(targets, model_str_or_path="umxhq", device="cpu", pretrained=True):
- """Core model loader
-
- target model path can be either <target>.pth, or <target>-sha256.pth
- (as used on torchub)
-
- The loader either loads the models from a known model string
- as registered in the __init__.py or loads from custom configs.
- """
- if isinstance(targets, str):
- targets = [targets]
-
- model_path = Path(model_str_or_path).expanduser()
- if not model_path.exists():
- # model path does not exist, use pretrained models
- try:
- # disable progress bar
- hub_loader = getattr(openunmix, model_str_or_path + "_spec")
- err = io.StringIO()
- with redirect_stderr(err):
- return hub_loader(targets=targets, device=device, pretrained=pretrained)
- print(err.getvalue())
- except AttributeError:
- raise NameError("Model does not exist on torchhub")
- # assume model is a path to a local model_str_or_path directory
- else:
- models = {}
- for target in targets:
- # load model from disk
- with open(Path(model_path, target + ".json"), "r") as stream:
- results = json.load(stream)
-
- target_model_path = next(Path(model_path).glob("%s*.pth" % target))
- state = torch.load(target_model_path, map_location=device)
-
- models[target] = model.OpenUnmix(
- nb_bins=results["args"]["nfft"] // 2 + 1,
- nb_channels=results["args"]["nb_channels"],
- hidden_size=results["args"]["hidden_size"],
- max_bin=state["input_mean"].shape[0],
- )
-
- if pretrained:
- models[target].load_state_dict(state, strict=False)
-
- models[target].to(device)
- return models</code></pre>
-</details>
-</dd>
-<dt id="openunmix.utils.preprocess"><code class="name flex">
-<span>def <span class="ident">preprocess</span></span>(<span>audio: torch.Tensor, rate: Union[float, NoneType] = None, model_rate: Union[float, NoneType] = None) ‑> torch.Tensor</span>
-</code></dt>
-<dd>
-<div class="desc"><p>From an input tensor, convert it to a tensor of shape
-shape=(nb_samples, nb_channels, nb_timesteps). This includes:
--
-if input is 1D, adding the samples and channels dimensions.
--
-if input is 2D
-o and the smallest dimension is 1 or 2, adding the samples one.
-o and all dimensions are > 2, assuming the smallest is the samples
-one, and adding the channel one
-- at the end, if the number of channels is greater than the number
-of time steps, swap those two.
-- resampling to target rate if necessary</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>audio</code></strong> : <code>Tensor</code></dt>
-<dd>input waveform</dd>
-<dt><strong><code>rate</code></strong> : <code>float</code></dt>
-<dd>sample rate for the audio</dd>
-<dt><strong><code>model_rate</code></strong> : <code>float</code></dt>
-<dd>sample rate for the model</dd>
-</dl>
-<h2 id="returns">Returns</h2>
-<dl>
-<dt><code>Tensor</code></dt>
-<dd>[shape=(nb_samples, nb_channels=2, nb_timesteps)]</dd>
-</dl></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/utils.py#L249-L305" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def preprocess(
- audio: torch.Tensor,
- rate: Optional[float] = None,
- model_rate: Optional[float] = None,
-) -> torch.Tensor:
- """
- From an input tensor, convert it to a tensor of shape
- shape=(nb_samples, nb_channels, nb_timesteps). This includes:
- - if input is 1D, adding the samples and channels dimensions.
- - if input is 2D
- o and the smallest dimension is 1 or 2, adding the samples one.
- o and all dimensions are > 2, assuming the smallest is the samples
- one, and adding the channel one
- - at the end, if the number of channels is greater than the number
- of time steps, swap those two.
- - resampling to target rate if necessary
-
- Args:
- audio (Tensor): input waveform
- rate (float): sample rate for the audio
- model_rate (float): sample rate for the model
-
- Returns:
- Tensor: [shape=(nb_samples, nb_channels=2, nb_timesteps)]
- """
- shape = torch.as_tensor(audio.shape, device=audio.device)
-
- if len(shape) == 1:
- # assuming only time dimension is provided.
- audio = audio[None, None, ...]
- elif len(shape) == 2:
- if shape.min() <= 2:
- # assuming sample dimension is missing
- audio = audio[None, ...]
- else:
- # assuming channel dimension is missing
- audio = audio[:, None, ...]
- if audio.shape[1] > audio.shape[2]:
- # swapping channel and time
- audio = audio.transpose(1, 2)
- if audio.shape[1] > 2:
- warnings.warn("Channel count > 2!. Only the first two channels " "will be processed!")
- audio = audio[..., :2]
-
- if audio.shape[1] == 1:
- # if we have mono, we duplicate it to get stereo
- audio = torch.repeat_interleave(audio, 2, dim=1)
-
- if rate != model_rate:
- print("resampling")
- # we have to resample to model samplerate if needed
- # this makes sure we resample input only once
- resampler = torchaudio.transforms.Resample(
- orig_freq=rate, new_freq=model_rate, resampling_method="sinc_interpolation"
- ).to(audio.device)
- audio = resampler(audio)
- return audio</code></pre>
-</details>
-</dd>
-<dt id="openunmix.utils.save_checkpoint"><code class="name flex">
-<span>def <span class="ident">save_checkpoint</span></span>(<span>state:Â dict, is_best:Â bool, path:Â str, target:Â str)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Convert bandwidth to maximum bin count</p>
-<p>Assuming lapped transforms such as STFT</p>
-<h2 id="args">Args</h2>
-<dl>
-<dt><strong><code>state</code></strong> : <code>dict</code></dt>
-<dd>torch model state dict</dd>
-<dt><strong><code>is_best</code></strong> : <code>bool</code></dt>
-<dd>if current model is about to be saved as best model</dd>
-<dt><strong><code>path</code></strong> : <code>str</code></dt>
-<dd>model path</dd>
-<dt><strong><code>target</code></strong> : <code>str</code></dt>
-<dd>target name</dd>
-</dl></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/utils.py#L35-L50" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def save_checkpoint(state: dict, is_best: bool, path: str, target: str):
- """Convert bandwidth to maximum bin count
-
- Assuming lapped transforms such as STFT
-
- Args:
- state (dict): torch model state dict
- is_best (bool): if current model is about to be saved as best model
- path (str): model path
- target (str): target name
- """
- # save full checkpoint including optimizer
- torch.save(state, os.path.join(path, target + ".chkpnt"))
- if is_best:
- # save just the weights
- torch.save(state["state_dict"], os.path.join(path, target + ".pth"))</code></pre>
-</details>
-</dd>
-</dl>
-</section>
-<section>
-<h2 class="section-title" id="header-classes">Classes</h2>
-<dl>
-<dt id="openunmix.utils.AverageMeter"><code class="flex name class">
-<span>class <span class="ident">AverageMeter</span></span>
-</code></dt>
-<dd>
-<div class="desc"><p>Computes and stores the average and current value</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/utils.py#L53-L69" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class AverageMeter(object):
- """Computes and stores the average and current value"""
-
- def __init__(self):
- self.reset()
-
- def reset(self):
- self.val = 0
- self.avg = 0
- self.sum = 0
- self.count = 0
-
- def update(self, val, n=1):
- self.val = val
- self.sum += val * n
- self.count += n
- self.avg = self.sum / self.count</code></pre>
-</details>
-<h3>Methods</h3>
-<dl>
-<dt id="openunmix.utils.AverageMeter.reset"><code class="name flex">
-<span>def <span class="ident">reset</span></span>(<span>self)</span>
-</code></dt>
-<dd>
-<div class="desc"></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/utils.py#L59-L63" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def reset(self):
- self.val = 0
- self.avg = 0
- self.sum = 0
- self.count = 0</code></pre>
-</details>
-</dd>
-<dt id="openunmix.utils.AverageMeter.update"><code class="name flex">
-<span>def <span class="ident">update</span></span>(<span>self, val, n=1)</span>
-</code></dt>
-<dd>
-<div class="desc"></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/utils.py#L65-L69" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def update(self, val, n=1):
- self.val = val
- self.sum += val * n
- self.count += n
- self.avg = self.sum / self.count</code></pre>
-</details>
-</dd>
-</dl>
-</dd>
-<dt id="openunmix.utils.EarlyStopping"><code class="flex name class">
-<span>class <span class="ident">EarlyStopping</span></span>
-<span>(</span><span>mode='min', min_delta=0, patience=10)</span>
-</code></dt>
-<dd>
-<div class="desc"><p>Early Stopping Monitor</p></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/utils.py#L72-L112" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">class EarlyStopping(object):
- """Early Stopping Monitor"""
-
- def __init__(self, mode="min", min_delta=0, patience=10):
- self.mode = mode
- self.min_delta = min_delta
- self.patience = patience
- self.best = None
- self.num_bad_epochs = 0
- self.is_better = None
- self._init_is_better(mode, min_delta)
-
- if patience == 0:
- self.is_better = lambda a, b: True
-
- def step(self, metrics):
- if self.best is None:
- self.best = metrics
- return False
-
- if np.isnan(metrics):
- return True
-
- if self.is_better(metrics, self.best):
- self.num_bad_epochs = 0
- self.best = metrics
- else:
- self.num_bad_epochs += 1
-
- if self.num_bad_epochs >= self.patience:
- return True
-
- return False
-
- def _init_is_better(self, mode, min_delta):
- if mode not in {"min", "max"}:
- raise ValueError("mode " + mode + " is unknown!")
- if mode == "min":
- self.is_better = lambda a, best: a < best - min_delta
- if mode == "max":
- self.is_better = lambda a, best: a > best + min_delta</code></pre>
-</details>
-<h3>Methods</h3>
-<dl>
-<dt id="openunmix.utils.EarlyStopping.step"><code class="name flex">
-<span>def <span class="ident">step</span></span>(<span>self, metrics)</span>
-</code></dt>
-<dd>
-<div class="desc"></div>
-<details class="source">
-<summary>
-<span>Expand source code</span>
-<a href="https://github.com/sigsep/open-unmix-pytorch/blob/b436d5f7d40c2b8ff0b2500e9d953fa47929b261/openunmix/utils.py#L87-L104" class="git-link">Browse git</a>
-</summary>
-<pre><code class="python">def step(self, metrics):
- if self.best is None:
- self.best = metrics
- return False
-
- if np.isnan(metrics):
- return True
-
- if self.is_better(metrics, self.best):
- self.num_bad_epochs = 0
- self.best = metrics
- else:
- self.num_bad_epochs += 1
-
- if self.num_bad_epochs >= self.patience:
- return True
-
- return False</code></pre>
-</details>
-</dd>
-</dl>
-</dd>
-</dl>
-</section>
-</article>
-<nav id="sidebar">
-<h1>Index</h1>
-<div class="toc">
-<ul></ul>
-</div>
-<ul id="index">
-<li><h3>Super-module</h3>
-<ul>
-<li><code><a title="openunmix" href="index.html">openunmix</a></code></li>
-</ul>
-</li>
-<li><h3><a href="#header-functions">Functions</a></h3>
-<ul class="">
-<li><code><a title="openunmix.utils.bandwidth_to_max_bin" href="#openunmix.utils.bandwidth_to_max_bin">bandwidth_to_max_bin</a></code></li>
-<li><code><a title="openunmix.utils.load_separator" href="#openunmix.utils.load_separator">load_separator</a></code></li>
-<li><code><a title="openunmix.utils.load_target_models" href="#openunmix.utils.load_target_models">load_target_models</a></code></li>
-<li><code><a title="openunmix.utils.preprocess" href="#openunmix.utils.preprocess">preprocess</a></code></li>
-<li><code><a title="openunmix.utils.save_checkpoint" href="#openunmix.utils.save_checkpoint">save_checkpoint</a></code></li>
-</ul>
-</li>
-<li><h3><a href="#header-classes">Classes</a></h3>
-<ul>
-<li>
-<h4><code><a title="openunmix.utils.AverageMeter" href="#openunmix.utils.AverageMeter">AverageMeter</a></code></h4>
-<ul class="">
-<li><code><a title="openunmix.utils.AverageMeter.reset" href="#openunmix.utils.AverageMeter.reset">reset</a></code></li>
-<li><code><a title="openunmix.utils.AverageMeter.update" href="#openunmix.utils.AverageMeter.update">update</a></code></li>
-</ul>
-</li>
-<li>
-<h4><code><a title="openunmix.utils.EarlyStopping" href="#openunmix.utils.EarlyStopping">EarlyStopping</a></code></h4>
-<ul class="">
-<li><code><a title="openunmix.utils.EarlyStopping.step" href="#openunmix.utils.EarlyStopping.step">step</a></code></li>
-</ul>
-</li>
-</ul>
-</li>
-</ul>
-</nav>
-</main>
-<footer id="footer">
-<p>Generated by <a href="https://pdoc3.github.io/pdoc"><cite>pdoc</cite> 0.9.2</a>.</p>
-</footer>
-</body>
-</html>
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/hubconf.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/hubconf.py
deleted file mode 100644
index 669017fd2bf02d7041ad23b431d0ccc60e43076e..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/hubconf.py
+++ /dev/null
@@ -1,19 +0,0 @@
-# This file is to be parsed by torch.hub mechanics
-#
-# `xxx_spec` take spectrogram inputs and output separated spectrograms
-# `xxx` take waveform inputs and output separated waveforms
-
-# Optional list of dependencies required by the package
-dependencies = ['torch', 'numpy']
-
-from openunmix import umxse_spec
-from openunmix import umxse
-
-from openunmix import umxhq_spec
-from openunmix import umxhq
-
-from openunmix import umx_spec
-from openunmix import umx
-
-from openunmix import umxl_spec
-from openunmix import umxl
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/__init__.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/__init__.py
deleted file mode 100644
index dc3fbb8a281bed5d68819549a4216811cd93cb00..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/__init__.py
+++ /dev/null
@@ -1,346 +0,0 @@
-"""
-
-Open-Unmix is a deep neural network reference implementation for music source separation, applicable for researchers, audio engineers and artists. Open-Unmix provides ready-to-use models that allow users to separate pop music into four stems: vocals, drums, bass and the remaining other instruments. The models were pre-trained on the MUSDB18 dataset. See details at apply pre-trained model.
-
-This is the python package API documentation.
-Please checkout [the open-unmix website](https://sigsep.github.io/open-unmix) for more information.
-"""
-from openunmix import utils
-import torch.hub
-
-
-def umxse_spec(targets=None, device="cpu", pretrained=True):
- target_urls = {
- "speech": "https://zenodo.org/api/files/765b45a3-c70d-48a6-936b-09a7989c349a/speech_f5e0d9f9.pth",
- "noise": "https://zenodo.org/api/files/765b45a3-c70d-48a6-936b-09a7989c349a/noise_04a6fc2d.pth",
- }
-
- from .model import OpenUnmix
-
- if targets is None:
- targets = ["speech", "noise"]
-
- # determine the maximum bin count for a 16khz bandwidth model
- max_bin = utils.bandwidth_to_max_bin(rate=16000.0, n_fft=1024, bandwidth=16000)
-
- # load open unmix models speech enhancement models
- target_models = {}
- for target in targets:
- target_unmix = OpenUnmix(
- nb_bins=1024 // 2 + 1, nb_channels=1, hidden_size=256, max_bin=max_bin
- )
-
- # enable centering of stft to minimize reconstruction error
- if pretrained:
- state_dict = torch.hub.load_state_dict_from_url(
- target_urls[target], map_location=device
- )
- target_unmix.load_state_dict(state_dict, strict=False)
- target_unmix.eval()
-
- target_unmix.to(device)
- target_models[target] = target_unmix
- return target_models
-
-
-def umxse(
- targets=None,
- residual=False,
- niter=1,
- device="cpu",
- pretrained=True,
- filterbank="torch",
-):
- """
- Open Unmix Speech Enhancemennt 1-channel BiLSTM Model
- trained on the 28-speaker version of Voicebank+Demand
- (Sampling rate: 16kHz)
-
- Args:
- targets (str): select the targets for the source to be separated.
- a list including: ['speech', 'noise'].
- If you don't pick them all, you probably want to
- activate the `residual=True` option.
- Defaults to all available targets per model.
- pretrained (bool): If True, returns a model pre-trained on MUSDB18-HQ
- residual (bool): if True, a "garbage" target is created
- niter (int): the number of post-processingiterations, defaults to 0
- device (str): selects device to be used for inference
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
-
- Reference:
- Uhlich, Stefan, & Mitsufuji, Yuki. (2020).
- Open-Unmix for Speech Enhancement (UMX SE).
- Zenodo. http://doi.org/10.5281/zenodo.3786908
- """
- from .model import Separator
-
- target_models = umxse_spec(targets=targets, device=device, pretrained=pretrained)
-
- separator = Separator(
- target_models=target_models,
- niter=niter,
- residual=residual,
- n_fft=1024,
- n_hop=512,
- nb_channels=1,
- sample_rate=16000.0,
- filterbank=filterbank,
- ).to(device)
-
- return separator
-
-
-def umxhq_spec(targets=None, device="cpu", pretrained=True):
- from .model import OpenUnmix
-
- # set urls for weights
- target_urls = {
- "bass": "https://zenodo.org/api/files/1c8f83c5-33a5-4f59-b109-721fdd234875/bass-8d85a5bd.pth",
- "drums": "https://zenodo.org/api/files/1c8f83c5-33a5-4f59-b109-721fdd234875/drums-9619578f.pth",
- "other": "https://zenodo.org/api/files/1c8f83c5-33a5-4f59-b109-721fdd234875/other-b52fbbf7.pth",
- "vocals": "https://zenodo.org/api/files/1c8f83c5-33a5-4f59-b109-721fdd234875/vocals-b62c91ce.pth",
- }
-
- if targets is None:
- targets = ["vocals", "drums", "bass", "other"]
-
- # determine the maximum bin count for a 16khz bandwidth model
- max_bin = utils.bandwidth_to_max_bin(rate=44100.0, n_fft=4096, bandwidth=16000)
-
- target_models = {}
- for target in targets:
- # load open unmix model
- target_unmix = OpenUnmix(
- nb_bins=4096 // 2 + 1, nb_channels=2, hidden_size=512, max_bin=max_bin
- )
-
- # enable centering of stft to minimize reconstruction error
- if pretrained:
- state_dict = torch.hub.load_state_dict_from_url(
- target_urls[target], map_location=device
- )
- target_unmix.load_state_dict(state_dict, strict=False)
- target_unmix.eval()
-
- target_unmix.to(device)
- target_models[target] = target_unmix
- return target_models
-
-
-def umxhq(
- targets=None,
- residual=False,
- niter=1,
- device="cpu",
- pretrained=True,
- filterbank="torch",
-):
- """
- Open Unmix 2-channel/stereo BiLSTM Model trained on MUSDB18-HQ
-
- Args:
- targets (str): select the targets for the source to be separated.
- a list including: ['vocals', 'drums', 'bass', 'other'].
- If you don't pick them all, you probably want to
- activate the `residual=True` option.
- Defaults to all available targets per model.
- pretrained (bool): If True, returns a model pre-trained on MUSDB18-HQ
- residual (bool): if True, a "garbage" target is created
- niter (int): the number of post-processingiterations, defaults to 0
- device (str): selects device to be used for inference
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
- """
-
- from .model import Separator
-
- target_models = umxhq_spec(targets=targets, device=device, pretrained=pretrained)
-
- separator = Separator(
- target_models=target_models,
- niter=niter,
- residual=residual,
- n_fft=4096,
- n_hop=1024,
- nb_channels=2,
- sample_rate=44100.0,
- filterbank=filterbank,
- ).to(device)
-
- return separator
-
-
-def umx_spec(targets=None, device="cpu", pretrained=True):
- from .model import OpenUnmix
-
- # set urls for weights
- target_urls = {
- "bass": "https://zenodo.org/api/files/d6105b95-8c52-430c-84ce-bd14b803faaf/bass-646024d3.pth",
- "drums": "https://zenodo.org/api/files/d6105b95-8c52-430c-84ce-bd14b803faaf/drums-5a48008b.pth",
- "other": "https://zenodo.org/api/files/d6105b95-8c52-430c-84ce-bd14b803faaf/other-f8e132cc.pth",
- "vocals": "https://zenodo.org/api/files/d6105b95-8c52-430c-84ce-bd14b803faaf/vocals-c8df74a5.pth",
- }
-
- if targets is None:
- targets = ["vocals", "drums", "bass", "other"]
-
- # determine the maximum bin count for a 16khz bandwidth model
- max_bin = utils.bandwidth_to_max_bin(rate=44100.0, n_fft=4096, bandwidth=16000)
-
- target_models = {}
- for target in targets:
- # load open unmix model
- target_unmix = OpenUnmix(
- nb_bins=4096 // 2 + 1, nb_channels=2, hidden_size=512, max_bin=max_bin
- )
-
- # enable centering of stft to minimize reconstruction error
- if pretrained:
- state_dict = torch.hub.load_state_dict_from_url(
- target_urls[target], map_location=device
- )
- target_unmix.load_state_dict(state_dict, strict=False)
- target_unmix.eval()
-
- target_unmix.to(device)
- target_models[target] = target_unmix
- return target_models
-
-
-def umx(
- targets=None,
- residual=False,
- niter=1,
- device="cpu",
- pretrained=True,
- filterbank="torch",
-):
- """
- Open Unmix 2-channel/stereo BiLSTM Model trained on MUSDB18
-
- Args:
- targets (str): select the targets for the source to be separated.
- a list including: ['vocals', 'drums', 'bass', 'other'].
- If you don't pick them all, you probably want to
- activate the `residual=True` option.
- Defaults to all available targets per model.
- pretrained (bool): If True, returns a model pre-trained on MUSDB18-HQ
- residual (bool): if True, a "garbage" target is created
- niter (int): the number of post-processingiterations, defaults to 0
- device (str): selects device to be used for inference
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
-
- """
-
- from .model import Separator
-
- target_models = umx_spec(targets=targets, device=device, pretrained=pretrained)
- separator = Separator(
- target_models=target_models,
- niter=niter,
- residual=residual,
- n_fft=4096,
- n_hop=1024,
- nb_channels=2,
- sample_rate=44100.0,
- filterbank=filterbank,
- ).to(device)
-
- return separator
-
-
-def umxl_spec(targets=None, device="cpu", pretrained=True):
- from .model import OpenUnmix
-
- # set urls for weights
- target_urls = {
- "bass": "https://zenodo.org/api/files/f8209c3e-ba60-48cf-8e79-71ae65beca61/bass-2ca1ce51.pth",
- "drums": "https://zenodo.org/api/files/f8209c3e-ba60-48cf-8e79-71ae65beca61/drums-69e0ebd4.pth",
- "other": "https://zenodo.org/api/files/f8209c3e-ba60-48cf-8e79-71ae65beca61/other-c8c5b3e6.pth",
- "vocals": "https://zenodo.org/api/files/f8209c3e-ba60-48cf-8e79-71ae65beca61/vocals-bccbd9aa.pth",
- }
-
- if targets is None:
- targets = ["vocals", "drums", "bass", "other"]
-
- # determine the maximum bin count for a 16khz bandwidth model
- max_bin = utils.bandwidth_to_max_bin(rate=44100.0, n_fft=4096, bandwidth=16000)
-
- target_models = {}
- for target in targets:
- # load open unmix model
- target_unmix = OpenUnmix(
- nb_bins=4096 // 2 + 1, nb_channels=2, hidden_size=1024, max_bin=max_bin
- )
-
- # enable centering of stft to minimize reconstruction error
- if pretrained:
- state_dict = torch.hub.load_state_dict_from_url(
- target_urls[target], map_location=device
- )
- target_unmix.load_state_dict(state_dict, strict=False)
- target_unmix.eval()
-
- target_unmix.to(device)
- target_models[target] = target_unmix
- return target_models
-
-
-def umxl(
- targets=None,
- residual=False,
- niter=1,
- device="cpu",
- pretrained=True,
- filterbank="torch",
-):
- """
- Open Unmix Extra (UMX-L), 2-channel/stereo BLSTM Model trained on a private dataset
- of ~400h of multi-track audio.
-
-
- Args:
- targets (str): select the targets for the source to be separated.
- a list including: ['vocals', 'drums', 'bass', 'other'].
- If you don't pick them all, you probably want to
- activate the `residual=True` option.
- Defaults to all available targets per model.
- pretrained (bool): If True, returns a model pre-trained on MUSDB18-HQ
- residual (bool): if True, a "garbage" target is created
- niter (int): the number of post-processingiterations, defaults to 0
- device (str): selects device to be used for inference
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
-
- """
-
- from .model import Separator
-
- target_models = umxl_spec(targets=targets, device=device, pretrained=pretrained)
- separator = Separator(
- target_models=target_models,
- niter=niter,
- residual=residual,
- n_fft=4096,
- n_hop=1024,
- nb_channels=2,
- sample_rate=44100.0,
- filterbank=filterbank,
- ).to(device)
-
- return separator
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/cli.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/cli.py
deleted file mode 100644
index 23d2a37ee3ea7c3ceca469ba6e0da6ce68813250..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/cli.py
+++ /dev/null
@@ -1,205 +0,0 @@
-from pathlib import Path
-import torch
-import torchaudio
-import json
-import numpy as np
-import tqdm
-
-from openunmix import utils
-from openunmix import predict
-from openunmix import data
-
-import argparse
-
-
-def separate():
- parser = argparse.ArgumentParser(
- description="UMX Inference",
- add_help=True,
- formatter_class=argparse.RawDescriptionHelpFormatter,
- )
-
- parser.add_argument("input", type=str, nargs="+", help="List of paths to wav/flac files.")
-
- parser.add_argument(
- "--model",
- default="umxl",
- type=str,
- help="path to mode base directory of pretrained models, defaults to UMX-L",
- )
-
- parser.add_argument(
- "--targets",
- nargs="+",
- type=str,
- help="provide targets to be processed. \
- If none, all available targets will be computed",
- )
-
- parser.add_argument(
- "--outdir",
- type=str,
- help="Results path where audio evaluation results are stored",
- )
-
- parser.add_argument(
- "--ext",
- type=str,
- default=".wav",
- help="Output extension which sets the audio format",
- )
-
- parser.add_argument("--start", type=float, default=0.0, help="Audio chunk start in seconds")
-
- parser.add_argument(
- "--duration",
- type=float,
- help="Audio chunk duration in seconds, negative values load full track",
- )
-
- parser.add_argument(
- "--no-cuda", action="store_true", default=False, help="disables CUDA inference"
- )
-
- parser.add_argument(
- "--audio-backend",
- type=str,
- help="Sets audio backend. Default to torchaudio's default backend: See https://pytorch.org/audio/stable/backend.html"
- "(`sox_io`, `sox`, `soundfile` or `stempeg`)",
- )
-
- parser.add_argument(
- "--niter",
- type=int,
- default=1,
- help="number of iterations for refining results.",
- )
-
- parser.add_argument(
- "--wiener-win-len",
- type=int,
- default=300,
- help="Number of frames on which to apply filtering independently",
- )
-
- parser.add_argument(
- "--residual",
- type=str,
- default=None,
- help="if provided, build a source with given name "
- "for the mix minus all estimated targets",
- )
-
- parser.add_argument(
- "--aggregate",
- type=str,
- default=None,
- help="if provided, must be a string containing a valid expression for "
- "a dictionary, with keys as output target names, and values "
- "a list of targets that are used to build it. For instance: "
- '\'{"vocals":["vocals"], "accompaniment":["drums",'
- '"bass","other"]}\'',
- )
-
- parser.add_argument(
- "--filterbank",
- type=str,
- default="torch",
- help="filterbank implementation method. "
- "Supported: `['torch', 'asteroid']`. `torch` is ~30%% faster "
- "compared to `asteroid` on large FFT sizes such as 4096. However "
- "asteroids stft can be exported to onnx, which makes is practical "
- "for deployment.",
- )
- parser.add_argument(
- "--verbose",
- action="store_true",
- default=False,
- help="Enable log messages",
- )
- args = parser.parse_args()
-
- if args.audio_backend != "stempeg" and args.audio_backend is not None:
- torchaudio.set_audio_backend(args.audio_backend)
-
- use_cuda = not args.no_cuda and torch.cuda.is_available()
- device = torch.device("cuda" if use_cuda else "cpu")
- if args.verbose:
- print("Using ", device)
- # parsing the output dict
- aggregate_dict = None if args.aggregate is None else json.loads(args.aggregate)
-
- # create separator only once to reduce model loading
- # when using multiple files
- separator = utils.load_separator(
- model_str_or_path=args.model,
- targets=args.targets,
- niter=args.niter,
- residual=args.residual,
- wiener_win_len=args.wiener_win_len,
- device=device,
- pretrained=True,
- filterbank=args.filterbank,
- )
-
- separator.freeze()
- separator.to(device)
-
- if args.audio_backend == "stempeg":
- try:
- import stempeg
- except ImportError:
- raise RuntimeError("Please install pip package `stempeg`")
-
- # loop over the files
- for input_file in tqdm.tqdm(args.input):
- if args.audio_backend == "stempeg":
- audio, rate = stempeg.read_stems(
- input_file,
- start=args.start,
- duration=args.duration,
- sample_rate=separator.sample_rate,
- dtype=np.float32,
- )
- audio = torch.tensor(audio)
- else:
- audio, rate = data.load_audio(input_file, start=args.start, dur=args.duration)
- estimates = predict.separate(
- audio=audio,
- rate=rate,
- aggregate_dict=aggregate_dict,
- separator=separator,
- device=device,
- )
- if not args.outdir:
- model_path = Path(args.model)
- if not model_path.exists():
- outdir = Path(Path(input_file).stem + "_" + args.model)
- else:
- outdir = Path(Path(input_file).stem + "_" + model_path.stem)
- else:
- outdir = Path(args.outdir) / Path(input_file).stem
- outdir.mkdir(exist_ok=True, parents=True)
-
- # write out estimates
- if args.audio_backend == "stempeg":
- target_path = str(outdir / Path("target").with_suffix(args.ext))
- # convert torch dict to numpy dict
- estimates_numpy = {}
- for target, estimate in estimates.items():
- estimates_numpy[target] = torch.squeeze(estimate).detach().cpu().numpy().T
-
- stempeg.write_stems(
- target_path,
- estimates_numpy,
- sample_rate=separator.sample_rate,
- writer=stempeg.FilesWriter(multiprocess=True, output_sample_rate=rate),
- )
- else:
- for target, estimate in estimates.items():
- target_path = str(outdir / Path(target).with_suffix(args.ext))
- torchaudio.save(
- target_path,
- torch.squeeze(estimate).to("cpu"),
- sample_rate=separator.sample_rate,
- )
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/data.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/data.py
deleted file mode 100644
index c07cac8200515812e782e5918c9ce8dfed150fd0..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/data.py
+++ /dev/null
@@ -1,974 +0,0 @@
-import argparse
-import random
-from pathlib import Path
-from typing import Optional, Union, Tuple, List, Any, Callable
-
-import torch
-import torch.utils.data
-import torchaudio
-import tqdm
-
-
-def load_info(path: str) -> dict:
- """Load audio metadata
-
- this is a backend_independent wrapper around torchaudio.info
-
- Args:
- path: Path of filename
- Returns:
- Dict: Metadata with
- `samplerate`, `samples` and `duration` in seconds
-
- """
- # get length of file in samples
- if torchaudio.get_audio_backend() == "sox":
- raise RuntimeError("Deprecated backend is not supported")
-
- info = {}
- si = torchaudio.info(str(path))
- info["samplerate"] = si.sample_rate
- info["samples"] = si.num_frames
- info["channels"] = si.num_channels
- info["duration"] = info["samples"] / info["samplerate"]
- return info
-
-
-def load_audio(
- path: str,
- start: float = 0.0,
- dur: Optional[float] = None,
- info: Optional[dict] = None,
-):
- """Load audio file
-
- Args:
- path: Path of audio file
- start: start position in seconds, defaults on the beginning.
- dur: end position in seconds, defaults to `None` (full file).
- info: metadata object as called from `load_info`.
-
- Returns:
- Tensor: torch tensor waveform of shape `(num_channels, num_samples)`
- """
- # loads the full track duration
- if dur is None:
- # we ignore the case where start!=0 and dur=None
- # since we have to deal with fixed length audio
- sig, rate = torchaudio.load(path)
- return sig, rate
- else:
- if info is None:
- info = load_info(path)
- num_frames = int(dur * info["samplerate"])
- frame_offset = int(start * info["samplerate"])
- sig, rate = torchaudio.load(path, num_frames=num_frames, frame_offset=frame_offset)
- return sig, rate
-
-
-def aug_from_str(list_of_function_names: list):
- if list_of_function_names:
- return Compose([globals()["_augment_" + aug] for aug in list_of_function_names])
- else:
- return lambda audio: audio
-
-
-class Compose(object):
- """Composes several augmentation transforms.
- Args:
- augmentations: list of augmentations to compose.
- """
-
- def __init__(self, transforms):
- self.transforms = transforms
-
- def __call__(self, audio: torch.Tensor) -> torch.Tensor:
- for t in self.transforms:
- audio = t(audio)
- return audio
-
-
-def _augment_gain(audio: torch.Tensor, low: float = 0.25, high: float = 1.25) -> torch.Tensor:
- """Applies a random gain between `low` and `high`"""
- g = low + torch.rand(1) * (high - low)
- return audio * g
-
-
-def _augment_channelswap(audio: torch.Tensor) -> torch.Tensor:
- """Swap channels of stereo signals with a probability of p=0.5"""
- if audio.shape[0] == 2 and torch.tensor(1.0).uniform_() < 0.5:
- return torch.flip(audio, [0])
- else:
- return audio
-
-
-def _augment_force_stereo(audio: torch.Tensor) -> torch.Tensor:
- # for multichannel > 2, we drop the other channels
- if audio.shape[0] > 2:
- audio = audio[:2, ...]
-
- if audio.shape[0] == 1:
- # if we have mono, we duplicate it to get stereo
- audio = torch.repeat_interleave(audio, 2, dim=0)
-
- return audio
-
-
-class UnmixDataset(torch.utils.data.Dataset):
- _repr_indent = 4
-
- def __init__(
- self,
- root: Union[Path, str],
- sample_rate: float,
- seq_duration: Optional[float] = None,
- source_augmentations: Optional[Callable] = None,
- ) -> None:
- self.root = Path(args.root).expanduser()
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.source_augmentations = source_augmentations
-
- def __getitem__(self, index: int) -> Any:
- raise NotImplementedError
-
- def __len__(self) -> int:
- raise NotImplementedError
-
- def __repr__(self) -> str:
- head = "Dataset " + self.__class__.__name__
- body = ["Number of datapoints: {}".format(self.__len__())]
- body += self.extra_repr().splitlines()
- lines = [head] + [" " * self._repr_indent + line for line in body]
- return "\n".join(lines)
-
- def extra_repr(self) -> str:
- return ""
-
-
-def load_datasets(
- parser: argparse.ArgumentParser, args: argparse.Namespace
-) -> Tuple[UnmixDataset, UnmixDataset, argparse.Namespace]:
- """Loads the specified dataset from commandline arguments
-
- Returns:
- train_dataset, validation_dataset
- """
- if args.dataset == "aligned":
- parser.add_argument("--input-file", type=str)
- parser.add_argument("--output-file", type=str)
-
- args = parser.parse_args()
- # set output target to basename of output file
- args.target = Path(args.output_file).stem
-
- dataset_kwargs = {
- "root": Path(args.root),
- "seq_duration": args.seq_dur,
- "input_file": args.input_file,
- "output_file": args.output_file,
- }
- args.target = Path(args.output_file).stem
- train_dataset = AlignedDataset(
- split="train", random_chunks=True, **dataset_kwargs
- ) # type: UnmixDataset
- valid_dataset = AlignedDataset(split="valid", **dataset_kwargs) # type: UnmixDataset
-
- elif args.dataset == "sourcefolder":
- parser.add_argument("--interferer-dirs", type=str, nargs="+")
- parser.add_argument("--target-dir", type=str)
- parser.add_argument("--ext", type=str, default=".wav")
- parser.add_argument("--nb-train-samples", type=int, default=1000)
- parser.add_argument("--nb-valid-samples", type=int, default=100)
- parser.add_argument("--source-augmentations", type=str, nargs="+")
- args = parser.parse_args()
- args.target = args.target_dir
-
- dataset_kwargs = {
- "root": Path(args.root),
- "interferer_dirs": args.interferer_dirs,
- "target_dir": args.target_dir,
- "ext": args.ext,
- }
-
- source_augmentations = aug_from_str(args.source_augmentations)
-
- train_dataset = SourceFolderDataset(
- split="train",
- source_augmentations=source_augmentations,
- random_chunks=True,
- nb_samples=args.nb_train_samples,
- seq_duration=args.seq_dur,
- **dataset_kwargs,
- )
-
- valid_dataset = SourceFolderDataset(
- split="valid",
- random_chunks=True,
- seq_duration=args.seq_dur,
- nb_samples=args.nb_valid_samples,
- **dataset_kwargs,
- )
-
- elif args.dataset == "trackfolder_fix":
- parser.add_argument("--target-file", type=str)
- parser.add_argument("--interferer-files", type=str, nargs="+")
- parser.add_argument(
- "--random-track-mix",
- action="store_true",
- default=False,
- help="Apply random track mixing augmentation",
- )
- parser.add_argument("--source-augmentations", type=str, nargs="+")
-
- args = parser.parse_args()
- args.target = Path(args.target_file).stem
-
- dataset_kwargs = {
- "root": Path(args.root),
- "interferer_files": args.interferer_files,
- "target_file": args.target_file,
- }
-
- source_augmentations = aug_from_str(args.source_augmentations)
-
- train_dataset = FixedSourcesTrackFolderDataset(
- split="train",
- source_augmentations=source_augmentations,
- random_track_mix=args.random_track_mix,
- random_chunks=True,
- seq_duration=args.seq_dur,
- **dataset_kwargs,
- )
- valid_dataset = FixedSourcesTrackFolderDataset(
- split="valid", seq_duration=None, **dataset_kwargs
- )
-
- elif args.dataset == "trackfolder_var":
- parser.add_argument("--ext", type=str, default=".wav")
- parser.add_argument("--target-file", type=str)
- parser.add_argument("--source-augmentations", type=str, nargs="+")
- parser.add_argument(
- "--random-interferer-mix",
- action="store_true",
- default=False,
- help="Apply random interferer mixing augmentation",
- )
- parser.add_argument(
- "--silence-missing",
- action="store_true",
- default=False,
- help="silence missing targets",
- )
-
- args = parser.parse_args()
- args.target = Path(args.target_file).stem
-
- dataset_kwargs = {
- "root": Path(args.root),
- "target_file": args.target_file,
- "ext": args.ext,
- "silence_missing_targets": args.silence_missing,
- }
-
- source_augmentations = Compose(
- [globals()["_augment_" + aug] for aug in args.source_augmentations]
- )
-
- train_dataset = VariableSourcesTrackFolderDataset(
- split="train",
- source_augmentations=source_augmentations,
- random_interferer_mix=args.random_interferer_mix,
- random_chunks=True,
- seq_duration=args.seq_dur,
- **dataset_kwargs,
- )
- valid_dataset = VariableSourcesTrackFolderDataset(
- split="valid", seq_duration=None, **dataset_kwargs
- )
-
- else:
- parser.add_argument(
- "--is-wav",
- action="store_true",
- default=False,
- help="loads wav instead of STEMS",
- )
- parser.add_argument("--samples-per-track", type=int, default=64)
- parser.add_argument(
- "--source-augmentations", type=str, default=["gain", "channelswap"], nargs="+"
- )
-
- args = parser.parse_args()
- dataset_kwargs = {
- "root": args.root,
- "is_wav": args.is_wav,
- "subsets": "train",
- "target": args.target,
- "download": args.root is None,
- "seed": args.seed,
- }
-
- source_augmentations = aug_from_str(args.source_augmentations)
-
- train_dataset = MUSDBDataset(
- split="train",
- samples_per_track=args.samples_per_track,
- seq_duration=args.seq_dur,
- source_augmentations=source_augmentations,
- random_track_mix=True,
- **dataset_kwargs,
- )
-
- valid_dataset = MUSDBDataset(
- split="valid", samples_per_track=1, seq_duration=None, **dataset_kwargs
- )
-
- return train_dataset, valid_dataset, args
-
-
-class AlignedDataset(UnmixDataset):
- def __init__(
- self,
- root: str,
- split: str = "train",
- input_file: str = "mixture.wav",
- output_file: str = "vocals.wav",
- seq_duration: Optional[float] = None,
- random_chunks: bool = False,
- sample_rate: float = 44100.0,
- source_augmentations: Optional[Callable] = None,
- seed: int = 42,
- ) -> None:
- """A dataset of that assumes multiple track folders
- where each track includes and input and an output file
- which directly corresponds to the the input and the
- output of the model. This dataset is the most basic of
- all datasets provided here, due to the least amount of
- preprocessing, it is also the fastest option, however,
- it lacks any kind of source augmentations or custum mixing.
-
- Typical use cases:
-
- * Source Separation (Mixture -> Target)
- * Denoising (Noisy -> Clean)
- * Bandwidth Extension (Low Bandwidth -> High Bandwidth)
-
- Example
- =======
- data/train/01/mixture.wav --> input
- data/train/01/vocals.wav ---> output
-
- """
- self.root = Path(root).expanduser()
- self.split = split
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.random_chunks = random_chunks
- # set the input and output files (accept glob)
- self.input_file = input_file
- self.output_file = output_file
- self.tuple_paths = list(self._get_paths())
- if not self.tuple_paths:
- raise RuntimeError("Dataset is empty, please check parameters")
- self.seed = seed
- random.seed(self.seed)
-
- def __getitem__(self, index):
- input_path, output_path = self.tuple_paths[index]
-
- if self.random_chunks:
- input_info = load_info(input_path)
- output_info = load_info(output_path)
- duration = min(input_info["duration"], output_info["duration"])
- start = random.uniform(0, duration - self.seq_duration)
- else:
- start = 0
-
- X_audio, _ = load_audio(input_path, start=start, dur=self.seq_duration)
- Y_audio, _ = load_audio(output_path, start=start, dur=self.seq_duration)
- # return torch tensors
- return X_audio, Y_audio
-
- def __len__(self):
- return len(self.tuple_paths)
-
- def _get_paths(self):
- """Loads input and output tracks"""
- p = Path(self.root, self.split)
- for track_path in tqdm.tqdm(p.iterdir()):
- if track_path.is_dir():
- input_path = list(track_path.glob(self.input_file))
- output_path = list(track_path.glob(self.output_file))
- if input_path and output_path:
- if self.seq_duration is not None:
- input_info = load_info(input_path[0])
- output_info = load_info(output_path[0])
- min_duration = min(input_info["duration"], output_info["duration"])
- # check if both targets are available in the subfolder
- if min_duration > self.seq_duration:
- yield input_path[0], output_path[0]
- else:
- yield input_path[0], output_path[0]
-
-
-class SourceFolderDataset(UnmixDataset):
- def __init__(
- self,
- root: str,
- split: str = "train",
- target_dir: str = "vocals",
- interferer_dirs: List[str] = ["bass", "drums"],
- ext: str = ".wav",
- nb_samples: int = 1000,
- seq_duration: Optional[float] = None,
- random_chunks: bool = True,
- sample_rate: float = 44100.0,
- source_augmentations: Optional[Callable] = lambda audio: audio,
- seed: int = 42,
- ) -> None:
- """A dataset that assumes folders of sources,
- instead of track folders. This is a common
- format for speech and environmental sound datasets
- such das DCASE. For each source a variable number of
- tracks/sounds is available, therefore the dataset
- is unaligned by design.
- By default, for each sample, sources from random track are drawn
- to assemble the mixture.
-
- Example
- =======
- train/vocals/track11.wav -----------------\
- train/drums/track202.wav (interferer1) ---+--> input
- train/bass/track007a.wav (interferer2) --/
-
- train/vocals/track11.wav ---------------------> output
-
- """
- self.root = Path(root).expanduser()
- self.split = split
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.ext = ext
- self.random_chunks = random_chunks
- self.source_augmentations = source_augmentations
- self.target_dir = target_dir
- self.interferer_dirs = interferer_dirs
- self.source_folders = self.interferer_dirs + [self.target_dir]
- self.source_tracks = self.get_tracks()
- self.nb_samples = nb_samples
- self.seed = seed
- random.seed(self.seed)
-
- def __getitem__(self, index):
- # For each source draw a random sound and mix them together
- audio_sources = []
- for source in self.source_folders:
- if self.split == "valid":
- # provide deterministic behaviour for validation so that
- # each epoch, the same tracks are yielded
- random.seed(index)
-
- # select a random track for each source
- source_path = random.choice(self.source_tracks[source])
- duration = load_info(source_path)["duration"]
- if self.random_chunks:
- # for each source, select a random chunk
- start = random.uniform(0, duration - self.seq_duration)
- else:
- # use center segment
- start = max(duration // 2 - self.seq_duration // 2, 0)
-
- audio, _ = load_audio(source_path, start=start, dur=self.seq_duration)
- audio = self.source_augmentations(audio)
- audio_sources.append(audio)
-
- stems = torch.stack(audio_sources)
- # # apply linear mix over source index=0
- x = stems.sum(0)
- # target is always the last element in the list
- y = stems[-1]
- return x, y
-
- def __len__(self):
- return self.nb_samples
-
- def get_tracks(self):
- """Loads input and output tracks"""
- p = Path(self.root, self.split)
- source_tracks = {}
- for source_folder in tqdm.tqdm(self.source_folders):
- tracks = []
- source_path = p / source_folder
- for source_track_path in sorted(source_path.glob("*" + self.ext)):
- if self.seq_duration is not None:
- info = load_info(source_track_path)
- # get minimum duration of track
- if info["duration"] > self.seq_duration:
- tracks.append(source_track_path)
- else:
- tracks.append(source_track_path)
- source_tracks[source_folder] = tracks
- return source_tracks
-
-
-class FixedSourcesTrackFolderDataset(UnmixDataset):
- def __init__(
- self,
- root: str,
- split: str = "train",
- target_file: str = "vocals.wav",
- interferer_files: List[str] = ["bass.wav", "drums.wav"],
- seq_duration: Optional[float] = None,
- random_chunks: bool = False,
- random_track_mix: bool = False,
- source_augmentations: Optional[Callable] = lambda audio: audio,
- sample_rate: float = 44100.0,
- seed: int = 42,
- ) -> None:
- """A dataset that assumes audio sources to be stored
- in track folder where each track has a fixed number of sources.
- For each track the users specifies the target file-name (`target_file`)
- and a list of interferences files (`interferer_files`).
- A linear mix is performed on the fly by summing the target and
- the inferers up.
-
- Due to the fact that all tracks comprise the exact same set
- of sources, the random track mixing augmentation technique
- can be used, where sources from different tracks are mixed
- together. Setting `random_track_mix=True` results in an
- unaligned dataset.
- When random track mixing is enabled, we define an epoch as
- when the the target source from all tracks has been seen and only once
- with whatever interfering sources has randomly been drawn.
-
- This dataset is recommended to be used for small/medium size
- for example like the MUSDB18 or other custom source separation
- datasets.
-
- Example
- =======
- train/1/vocals.wav ---------------\
- train/1/drums.wav (interferer1) ---+--> input
- train/1/bass.wav -(interferer2) --/
-
- train/1/vocals.wav -------------------> output
-
- """
- self.root = Path(root).expanduser()
- self.split = split
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.random_track_mix = random_track_mix
- self.random_chunks = random_chunks
- self.source_augmentations = source_augmentations
- # set the input and output files (accept glob)
- self.target_file = target_file
- self.interferer_files = interferer_files
- self.source_files = self.interferer_files + [self.target_file]
- self.seed = seed
- random.seed(self.seed)
-
- self.tracks = list(self.get_tracks())
- if not len(self.tracks):
- raise RuntimeError("No tracks found")
-
- def __getitem__(self, index):
- # first, get target track
- track_path = self.tracks[index]["path"]
- min_duration = self.tracks[index]["min_duration"]
- if self.random_chunks:
- # determine start seek by target duration
- start = random.uniform(0, min_duration - self.seq_duration)
- else:
- start = 0
-
- # assemble the mixture of target and interferers
- audio_sources = []
- # load target
- target_audio, _ = load_audio(
- track_path / self.target_file, start=start, dur=self.seq_duration
- )
- target_audio = self.source_augmentations(target_audio)
- audio_sources.append(target_audio)
- # load interferers
- for source in self.interferer_files:
- # optionally select a random track for each source
- if self.random_track_mix:
- random_idx = random.choice(range(len(self.tracks)))
- track_path = self.tracks[random_idx]["path"]
- if self.random_chunks:
- min_duration = self.tracks[random_idx]["min_duration"]
- start = random.uniform(0, min_duration - self.seq_duration)
-
- audio, _ = load_audio(track_path / source, start=start, dur=self.seq_duration)
- audio = self.source_augmentations(audio)
- audio_sources.append(audio)
-
- stems = torch.stack(audio_sources)
- # # apply linear mix over source index=0
- x = stems.sum(0)
- # target is always the first element in the list
- y = stems[0]
- return x, y
-
- def __len__(self):
- return len(self.tracks)
-
- def get_tracks(self):
- """Loads input and output tracks"""
- p = Path(self.root, self.split)
- for track_path in tqdm.tqdm(p.iterdir()):
- if track_path.is_dir():
- source_paths = [track_path / s for s in self.source_files]
- if not all(sp.exists() for sp in source_paths):
- print("Exclude track ", track_path)
- continue
-
- if self.seq_duration is not None:
- infos = list(map(load_info, source_paths))
- # get minimum duration of track
- min_duration = min(i["duration"] for i in infos)
- if min_duration > self.seq_duration:
- yield ({"path": track_path, "min_duration": min_duration})
- else:
- yield ({"path": track_path, "min_duration": None})
-
-
-class VariableSourcesTrackFolderDataset(UnmixDataset):
- def __init__(
- self,
- root: str,
- split: str = "train",
- target_file: str = "vocals.wav",
- ext: str = ".wav",
- seq_duration: Optional[float] = None,
- random_chunks: bool = False,
- random_interferer_mix: bool = False,
- sample_rate: float = 44100.0,
- source_augmentations: Optional[Callable] = lambda audio: audio,
- silence_missing_targets: bool = False,
- ) -> None:
- """A dataset that assumes audio sources to be stored
- in track folder where each track has a _variable_ number of sources.
- The users specifies the target file-name (`target_file`)
- and the extension of sources to used for mixing.
- A linear mix is performed on the fly by summing all sources in a
- track folder.
-
- Since the number of sources differ per track,
- while target is fixed, a random track mix
- augmentation cannot be used. Instead, a random track
- can be used to load the interfering sources.
-
- Also make sure, that you do not provide the mixture
- file among the sources!
-
- Example
- =======
- train/1/vocals.wav --> input target \
- train/1/drums.wav --> input target |
- train/1/bass.wav --> input target --+--> input
- train/1/accordion.wav --> input target |
- train/1/marimba.wav --> input target /
-
- train/1/vocals.wav -----------------------> output
-
- """
- self.root = Path(root).expanduser()
- self.split = split
- self.sample_rate = sample_rate
- self.seq_duration = seq_duration
- self.random_chunks = random_chunks
- self.random_interferer_mix = random_interferer_mix
- self.source_augmentations = source_augmentations
- self.target_file = target_file
- self.ext = ext
- self.silence_missing_targets = silence_missing_targets
- self.tracks = list(self.get_tracks())
-
- def __getitem__(self, index):
- # select the target based on the dataset index
- target_track_path = self.tracks[index]["path"]
- if self.random_chunks:
- target_min_duration = self.tracks[index]["min_duration"]
- target_start = random.uniform(0, target_min_duration - self.seq_duration)
- else:
- target_start = 0
-
- # optionally select a random interferer track
- if self.random_interferer_mix:
- random_idx = random.choice(range(len(self.tracks)))
- intfr_track_path = self.tracks[random_idx]["path"]
- if self.random_chunks:
- intfr_min_duration = self.tracks[random_idx]["min_duration"]
- intfr_start = random.uniform(0, intfr_min_duration - self.seq_duration)
- else:
- intfr_start = 0
- else:
- intfr_track_path = target_track_path
- intfr_start = target_start
-
- # get sources from interferer track
- sources = sorted(list(intfr_track_path.glob("*" + self.ext)))
-
- # load sources
- x = 0
- for source_path in sources:
- # skip target file and load it later
- if source_path == intfr_track_path / self.target_file:
- continue
-
- try:
- audio, _ = load_audio(source_path, start=intfr_start, dur=self.seq_duration)
- except RuntimeError:
- index = index - 1 if index > 0 else index + 1
- return self.__getitem__(index)
- x += self.source_augmentations(audio)
-
- # load the selected track target
- if Path(target_track_path / self.target_file).exists():
- y, _ = load_audio(
- target_track_path / self.target_file,
- start=target_start,
- dur=self.seq_duration,
- )
- y = self.source_augmentations(y)
- x += y
-
- # Use silence if target does not exist
- else:
- y = torch.zeros(audio.shape)
-
- return x, y
-
- def __len__(self):
- return len(self.tracks)
-
- def get_tracks(self):
- p = Path(self.root, self.split)
- for track_path in tqdm.tqdm(p.iterdir()):
- if track_path.is_dir():
- # check if target exists
- if Path(track_path, self.target_file).exists() or self.silence_missing_targets:
- sources = sorted(list(track_path.glob("*" + self.ext)))
- if not sources:
- # in case of empty folder
- print("empty track: ", track_path)
- continue
- if self.seq_duration is not None:
- # check sources
- infos = list(map(load_info, sources))
- # get minimum duration of source
- min_duration = min(i["duration"] for i in infos)
- if min_duration > self.seq_duration:
- yield ({"path": track_path, "min_duration": min_duration})
- else:
- yield ({"path": track_path, "min_duration": None})
-
-
-class MUSDBDataset(UnmixDataset):
- def __init__(
- self,
- target: str = "vocals",
- root: str = None,
- download: bool = False,
- is_wav: bool = False,
- subsets: str = "train",
- split: str = "train",
- seq_duration: Optional[float] = 6.0,
- samples_per_track: int = 64,
- source_augmentations: Optional[Callable] = lambda audio: audio,
- random_track_mix: bool = False,
- seed: int = 42,
- *args,
- **kwargs,
- ) -> None:
- """MUSDB18 torch.data.Dataset that samples from the MUSDB tracks
- using track and excerpts with replacement.
-
- Parameters
- ----------
- target : str
- target name of the source to be separated, defaults to ``vocals``.
- root : str
- root path of MUSDB
- download : boolean
- automatically download 7s preview version of MUSDB
- is_wav : boolean
- specify if the WAV version (instead of the MP4 STEMS) are used
- subsets : list-like [str]
- subset str or list of subset. Defaults to ``train``.
- split : str
- use (stratified) track splits for validation split (``valid``),
- defaults to ``train``.
- seq_duration : float
- training is performed in chunks of ``seq_duration`` (in seconds,
- defaults to ``None`` which loads the full audio track
- samples_per_track : int
- sets the number of samples, yielded from each track per epoch.
- Defaults to 64
- source_augmentations : list[callables]
- provide list of augmentation function that take a multi-channel
- audio file of shape (src, samples) as input and output. Defaults to
- no-augmentations (input = output)
- random_track_mix : boolean
- randomly mixes sources from different tracks to assemble a
- custom mix. This augmenation is only applied for the train subset.
- seed : int
- control randomness of dataset iterations
- args, kwargs : additional keyword arguments
- used to add further control for the musdb dataset
- initialization function.
-
- """
- import musdb
-
- self.seed = seed
- random.seed(seed)
- self.is_wav = is_wav
- self.seq_duration = seq_duration
- self.target = target
- self.subsets = subsets
- self.split = split
- self.samples_per_track = samples_per_track
- self.source_augmentations = source_augmentations
- self.random_track_mix = random_track_mix
- self.mus = musdb.DB(
- root=root,
- is_wav=is_wav,
- split=split,
- subsets=subsets,
- download=download,
- *args,
- **kwargs,
- )
- self.sample_rate = 44100.0 # musdb is fixed sample rate
-
- def __getitem__(self, index):
- audio_sources = []
- target_ind = None
-
- # select track
- track = self.mus.tracks[index // self.samples_per_track]
-
- # at training time we assemble a custom mix
- if self.split == "train" and self.seq_duration:
- for k, source in enumerate(self.mus.setup["sources"]):
- # memorize index of target source
- if source == self.target:
- target_ind = k
-
- # select a random track
- if self.random_track_mix:
- track = random.choice(self.mus.tracks)
-
- # set the excerpt duration
-
- track.chunk_duration = self.seq_duration
- # set random start position
- track.chunk_start = random.uniform(0, track.duration - self.seq_duration)
- # load source audio and apply time domain source_augmentations
- audio = torch.as_tensor(track.sources[source].audio.T, dtype=torch.float32)
- audio = self.source_augmentations(audio)
- audio_sources.append(audio)
-
- # create stem tensor of shape (source, channel, samples)
- stems = torch.stack(audio_sources, dim=0)
- # # apply linear mix over source index=0
- x = stems.sum(0)
- # get the target stem
- if target_ind is not None:
- y = stems[target_ind]
- # assuming vocal/accompaniment scenario if target!=source
- else:
- vocind = list(self.mus.setup["sources"].keys()).index("vocals")
- # apply time domain subtraction
- y = x - stems[vocind]
-
- # for validation and test, we deterministically yield the full
- # pre-mixed musdb track
- else:
- # get the non-linear source mix straight from musdb
- x = torch.as_tensor(track.audio.T, dtype=torch.float32)
- y = torch.as_tensor(track.targets[self.target].audio.T, dtype=torch.float32)
-
- return x, y
-
- def __len__(self):
- return len(self.mus.tracks) * self.samples_per_track
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(description="Open Unmix Trainer")
- parser.add_argument(
- "--dataset",
- type=str,
- default="musdb",
- choices=[
- "musdb",
- "aligned",
- "sourcefolder",
- "trackfolder_var",
- "trackfolder_fix",
- ],
- help="Name of the dataset.",
- )
-
- parser.add_argument("--root", type=str, help="root path of dataset")
-
- parser.add_argument(
- "--save", action="store_true", help=("write out a fixed dataset of samples")
- )
-
- parser.add_argument("--target", type=str, default="vocals")
- parser.add_argument("--seed", type=int, default=42)
- parser.add_argument(
- "--audio-backend",
- type=str,
- default="soundfile",
- help="Set torchaudio backend (`sox_io` or `soundfile`",
- )
-
- # I/O Parameters
- parser.add_argument(
- "--seq-dur",
- type=float,
- default=5.0,
- help="Duration of <=0.0 will result in the full audio",
- )
-
- parser.add_argument("--batch-size", type=int, default=16)
-
- args, _ = parser.parse_known_args()
-
- torchaudio.set_audio_backend(args.audio_backend)
-
- train_dataset, valid_dataset, args = load_datasets(parser, args)
- print("Audio Backend: ", torchaudio.get_audio_backend())
-
- # Iterate over training dataset and compute statistics
- total_training_duration = 0
- for k in tqdm.tqdm(range(len(train_dataset))):
- x, y = train_dataset[k]
- total_training_duration += x.shape[1] / train_dataset.sample_rate
- if args.save:
- torchaudio.save("test/" + str(k) + "x.wav", x.T, train_dataset.sample_rate)
- torchaudio.save("test/" + str(k) + "y.wav", y.T, train_dataset.sample_rate)
-
- print("Total training duration (h): ", total_training_duration / 3600)
- print("Number of train samples: ", len(train_dataset))
- print("Number of validation samples: ", len(valid_dataset))
-
- # iterate over dataloader
- train_dataset.seq_duration = args.seq_dur
-
- train_sampler = torch.utils.data.DataLoader(
- train_dataset,
- batch_size=args.batch_size,
- shuffle=True,
- num_workers=4,
- )
-
- for x, y in tqdm.tqdm(train_sampler):
- print(x.shape)
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/evaluate.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/evaluate.py
deleted file mode 100644
index e59535cbbd2b7177707663843f11f6ab948f057b..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/evaluate.py
+++ /dev/null
@@ -1,197 +0,0 @@
-import argparse
-import functools
-import json
-import multiprocessing
-from typing import Optional, Union
-
-import musdb
-import museval
-import torch
-import tqdm
-
-from openunmix import utils
-
-
-def separate_and_evaluate(
- track: musdb.MultiTrack,
- targets: list,
- model_str_or_path: str,
- niter: int,
- output_dir: str,
- eval_dir: str,
- residual: bool,
- mus,
- aggregate_dict: dict = None,
- device: Union[str, torch.device] = "cpu",
- wiener_win_len: Optional[int] = None,
- filterbank="torch",
-) -> str:
-
- separator = utils.load_separator(
- model_str_or_path=model_str_or_path,
- targets=targets,
- niter=niter,
- residual=residual,
- wiener_win_len=wiener_win_len,
- device=device,
- pretrained=True,
- filterbank=filterbank,
- )
-
- separator.freeze()
- separator.to(device)
-
- audio = torch.as_tensor(track.audio, dtype=torch.float32, device=device)
- audio = utils.preprocess(audio, track.rate, separator.sample_rate)
-
- estimates = separator(audio)
- estimates = separator.to_dict(estimates, aggregate_dict=aggregate_dict)
-
- for key in estimates:
- estimates[key] = estimates[key][0].cpu().detach().numpy().T
- if output_dir:
- mus.save_estimates(estimates, track, output_dir)
-
- scores = museval.eval_mus_track(track, estimates, output_dir=eval_dir)
- return scores
-
-
-if __name__ == "__main__":
- # Training settings
- parser = argparse.ArgumentParser(description="MUSDB18 Evaluation", add_help=False)
-
- parser.add_argument(
- "--targets",
- nargs="+",
- default=["vocals", "drums", "bass", "other"],
- type=str,
- help="provide targets to be processed. \
- If none, all available targets will be computed",
- )
-
- parser.add_argument(
- "--model",
- default="umxl",
- type=str,
- help="path to mode base directory of pretrained models",
- )
-
- parser.add_argument(
- "--outdir",
- type=str,
- help="Results path where audio evaluation results are stored",
- )
-
- parser.add_argument("--evaldir", type=str, help="Results path for museval estimates")
-
- parser.add_argument("--root", type=str, help="Path to MUSDB18")
-
- parser.add_argument("--subset", type=str, default="test", help="MUSDB subset (`train`/`test`)")
-
- parser.add_argument("--cores", type=int, default=1)
-
- parser.add_argument(
- "--no-cuda", action="store_true", default=False, help="disables CUDA inference"
- )
-
- parser.add_argument(
- "--is-wav",
- action="store_true",
- default=False,
- help="flags wav version of the dataset",
- )
-
- parser.add_argument(
- "--niter",
- type=int,
- default=1,
- help="number of iterations for refining results.",
- )
-
- parser.add_argument(
- "--wiener-win-len",
- type=int,
- default=300,
- help="Number of frames on which to apply filtering independently",
- )
-
- parser.add_argument(
- "--residual",
- type=str,
- default=None,
- help="if provided, build a source with given name"
- "for the mix minus all estimated targets",
- )
-
- parser.add_argument(
- "--aggregate",
- type=str,
- default=None,
- help="if provided, must be a string containing a valid expression for "
- "a dictionary, with keys as output target names, and values "
- "a list of targets that are used to build it. For instance: "
- '\'{"vocals":["vocals"], "accompaniment":["drums",'
- '"bass","other"]}\'',
- )
-
- args = parser.parse_args()
-
- use_cuda = not args.no_cuda and torch.cuda.is_available()
- device = torch.device("cuda" if use_cuda else "cpu")
-
- mus = musdb.DB(
- root=args.root,
- download=args.root is None,
- subsets=args.subset,
- is_wav=args.is_wav,
- )
- aggregate_dict = None if args.aggregate is None else json.loads(args.aggregate)
-
- if args.cores > 1:
- pool = multiprocessing.Pool(args.cores)
- results = museval.EvalStore()
- scores_list = list(
- pool.imap_unordered(
- func=functools.partial(
- separate_and_evaluate,
- targets=args.targets,
- model_str_or_path=args.model,
- niter=args.niter,
- residual=args.residual,
- mus=mus,
- aggregate_dict=aggregate_dict,
- output_dir=args.outdir,
- eval_dir=args.evaldir,
- device=device,
- ),
- iterable=mus.tracks,
- chunksize=1,
- )
- )
- pool.close()
- pool.join()
- for scores in scores_list:
- results.add_track(scores)
-
- else:
- results = museval.EvalStore()
- for track in tqdm.tqdm(mus.tracks):
- scores = separate_and_evaluate(
- track,
- targets=args.targets,
- model_str_or_path=args.model,
- niter=args.niter,
- residual=args.residual,
- mus=mus,
- aggregate_dict=aggregate_dict,
- output_dir=args.outdir,
- eval_dir=args.evaldir,
- device=device,
- )
- print(track, "\n", scores)
- results.add_track(scores)
-
- print(results)
- method = museval.MethodStore()
- method.add_evalstore(results, args.model)
- method.save(args.model + ".pandas")
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/filtering.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/filtering.py
deleted file mode 100644
index b0f4921e95dc95afa64c7e83d702cd011d8577b6..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/filtering.py
+++ /dev/null
@@ -1,504 +0,0 @@
-from typing import Optional
-
-import torch
-import torch.nn as nn
-from torch import Tensor
-from torch.utils.data import DataLoader
-
-
-def atan2(y, x):
- r"""Element-wise arctangent function of y/x.
- Returns a new tensor with signed angles in radians.
- It is an alternative implementation of torch.atan2
-
- Args:
- y (Tensor): First input tensor
- x (Tensor): Second input tensor [shape=y.shape]
-
- Returns:
- Tensor: [shape=y.shape].
- """
- pi = 2 * torch.asin(torch.tensor(1.0))
- x += ((x == 0) & (y == 0)) * 1.0
- out = torch.atan(y / x)
- out += ((y >= 0) & (x < 0)) * pi
- out -= ((y < 0) & (x < 0)) * pi
- out *= 1 - ((y > 0) & (x == 0)) * 1.0
- out += ((y > 0) & (x == 0)) * (pi / 2)
- out *= 1 - ((y < 0) & (x == 0)) * 1.0
- out += ((y < 0) & (x == 0)) * (-pi / 2)
- return out
-
-
-# Define basic complex operations on torch.Tensor objects whose last dimension
-# consists in the concatenation of the real and imaginary parts.
-
-
-def _norm(x: torch.Tensor) -> torch.Tensor:
- r"""Computes the norm value of a torch Tensor, assuming that it
- comes as real and imaginary part in its last dimension.
-
- Args:
- x (Tensor): Input Tensor of shape [shape=(..., 2)]
-
- Returns:
- Tensor: shape as x excluding the last dimension.
- """
- return torch.abs(x[..., 0]) ** 2 + torch.abs(x[..., 1]) ** 2
-
-
-def _mul_add(a: torch.Tensor, b: torch.Tensor, out: Optional[torch.Tensor] = None) -> torch.Tensor:
- """Element-wise multiplication of two complex Tensors described
- through their real and imaginary parts.
- The result is added to the `out` tensor"""
-
- # check `out` and allocate it if needed
- target_shape = torch.Size([max(sa, sb) for (sa, sb) in zip(a.shape, b.shape)])
- if out is None or out.shape != target_shape:
- out = torch.zeros(target_shape, dtype=a.dtype, device=a.device)
- if out is a:
- real_a = a[..., 0]
- out[..., 0] = out[..., 0] + (real_a * b[..., 0] - a[..., 1] * b[..., 1])
- out[..., 1] = out[..., 1] + (real_a * b[..., 1] + a[..., 1] * b[..., 0])
- else:
- out[..., 0] = out[..., 0] + (a[..., 0] * b[..., 0] - a[..., 1] * b[..., 1])
- out[..., 1] = out[..., 1] + (a[..., 0] * b[..., 1] + a[..., 1] * b[..., 0])
- return out
-
-
-def _mul(a: torch.Tensor, b: torch.Tensor, out: Optional[torch.Tensor] = None) -> torch.Tensor:
- """Element-wise multiplication of two complex Tensors described
- through their real and imaginary parts
- can work in place in case out is a only"""
- target_shape = torch.Size([max(sa, sb) for (sa, sb) in zip(a.shape, b.shape)])
- if out is None or out.shape != target_shape:
- out = torch.zeros(target_shape, dtype=a.dtype, device=a.device)
- if out is a:
- real_a = a[..., 0]
- out[..., 0] = real_a * b[..., 0] - a[..., 1] * b[..., 1]
- out[..., 1] = real_a * b[..., 1] + a[..., 1] * b[..., 0]
- else:
- out[..., 0] = a[..., 0] * b[..., 0] - a[..., 1] * b[..., 1]
- out[..., 1] = a[..., 0] * b[..., 1] + a[..., 1] * b[..., 0]
- return out
-
-
-def _inv(z: torch.Tensor, out: Optional[torch.Tensor] = None) -> torch.Tensor:
- """Element-wise multiplicative inverse of a Tensor with complex
- entries described through their real and imaginary parts.
- can work in place in case out is z"""
- ez = _norm(z)
- if out is None or out.shape != z.shape:
- out = torch.zeros_like(z)
- out[..., 0] = z[..., 0] / ez
- out[..., 1] = -z[..., 1] / ez
- return out
-
-
-def _conj(z, out: Optional[torch.Tensor] = None) -> torch.Tensor:
- """Element-wise complex conjugate of a Tensor with complex entries
- described through their real and imaginary parts.
- can work in place in case out is z"""
- if out is None or out.shape != z.shape:
- out = torch.zeros_like(z)
- out[..., 0] = z[..., 0]
- out[..., 1] = -z[..., 1]
- return out
-
-
-def _invert(M: torch.Tensor, out: Optional[torch.Tensor] = None) -> torch.Tensor:
- """
- Invert 1x1 or 2x2 matrices
-
- Will generate errors if the matrices are singular: user must handle this
- through his own regularization schemes.
-
- Args:
- M (Tensor): [shape=(..., nb_channels, nb_channels, 2)]
- matrices to invert: must be square along dimensions -3 and -2
-
- Returns:
- invM (Tensor): [shape=M.shape]
- inverses of M
- """
- nb_channels = M.shape[-2]
-
- if out is None or out.shape != M.shape:
- out = torch.empty_like(M)
-
- if nb_channels == 1:
- # scalar case
- out = _inv(M, out)
- elif nb_channels == 2:
- # two channels case: analytical expression
-
- # first compute the determinent
- det = _mul(M[..., 0, 0, :], M[..., 1, 1, :])
- det = det - _mul(M[..., 0, 1, :], M[..., 1, 0, :])
- # invert it
- invDet = _inv(det)
-
- # then fill out the matrix with the inverse
- out[..., 0, 0, :] = _mul(invDet, M[..., 1, 1, :], out[..., 0, 0, :])
- out[..., 1, 0, :] = _mul(-invDet, M[..., 1, 0, :], out[..., 1, 0, :])
- out[..., 0, 1, :] = _mul(-invDet, M[..., 0, 1, :], out[..., 0, 1, :])
- out[..., 1, 1, :] = _mul(invDet, M[..., 0, 0, :], out[..., 1, 1, :])
- else:
- raise Exception("Only 2 channels are supported for the torch version.")
- return out
-
-
-# Now define the signal-processing low-level functions used by the Separator
-
-
-def expectation_maximization(
- y: torch.Tensor,
- x: torch.Tensor,
- iterations: int = 2,
- eps: float = 1e-10,
- batch_size: int = 200,
-):
- r"""Expectation maximization algorithm, for refining source separation
- estimates.
-
- This algorithm allows to make source separation results better by
- enforcing multichannel consistency for the estimates. This usually means
- a better perceptual quality in terms of spatial artifacts.
-
- The implementation follows the details presented in [1]_, taking
- inspiration from the original EM algorithm proposed in [2]_ and its
- weighted refinement proposed in [3]_, [4]_.
- It works by iteratively:
-
- * Re-estimate source parameters (power spectral densities and spatial
- covariance matrices) through :func:`get_local_gaussian_model`.
-
- * Separate again the mixture with the new parameters by first computing
- the new modelled mixture covariance matrices with :func:`get_mix_model`,
- prepare the Wiener filters through :func:`wiener_gain` and apply them
- with :func:`apply_filter``.
-
- References
- ----------
- .. [1] S. Uhlich and M. Porcu and F. Giron and M. Enenkl and T. Kemp and
- N. Takahashi and Y. Mitsufuji, "Improving music source separation based
- on deep neural networks through data augmentation and network
- blending." 2017 IEEE International Conference on Acoustics, Speech
- and Signal Processing (ICASSP). IEEE, 2017.
-
- .. [2] N.Q. Duong and E. Vincent and R.Gribonval. "Under-determined
- reverberant audio source separation using a full-rank spatial
- covariance model." IEEE Transactions on Audio, Speech, and Language
- Processing 18.7 (2010): 1830-1840.
-
- .. [3] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel audio source
- separation with deep neural networks." IEEE/ACM Transactions on Audio,
- Speech, and Language Processing 24.9 (2016): 1652-1664.
-
- .. [4] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel music
- separation with deep neural networks." 2016 24th European Signal
- Processing Conference (EUSIPCO). IEEE, 2016.
-
- .. [5] A. Liutkus and R. Badeau and G. Richard "Kernel additive models for
- source separation." IEEE Transactions on Signal Processing
- 62.16 (2014): 4298-4310.
-
- Args:
- y (Tensor): [shape=(nb_frames, nb_bins, nb_channels, 2, nb_sources)]
- initial estimates for the sources
- x (Tensor): [shape=(nb_frames, nb_bins, nb_channels, 2)]
- complex STFT of the mixture signal
- iterations (int): [scalar]
- number of iterations for the EM algorithm.
- eps (float or None): [scalar]
- The epsilon value to use for regularization and filters.
-
- Returns:
- y (Tensor): [shape=(nb_frames, nb_bins, nb_channels, 2, nb_sources)]
- estimated sources after iterations
- v (Tensor): [shape=(nb_frames, nb_bins, nb_sources)]
- estimated power spectral densities
- R (Tensor): [shape=(nb_bins, nb_channels, nb_channels, 2, nb_sources)]
- estimated spatial covariance matrices
-
- Notes:
- * You need an initial estimate for the sources to apply this
- algorithm. This is precisely what the :func:`wiener` function does.
- * This algorithm *is not* an implementation of the "exact" EM
- proposed in [1]_. In particular, it does compute the posterior
- covariance matrices the same (exact) way. Instead, it uses the
- simplified approximate scheme initially proposed in [5]_ and further
- refined in [3]_, [4]_, that boils down to just take the empirical
- covariance of the recent source estimates, followed by a weighted
- average for the update of the spatial covariance matrix. It has been
- empirically demonstrated that this simplified algorithm is more
- robust for music separation.
-
- Warning:
- It is *very* important to make sure `x.dtype` is `torch.float64`
- if you want double precision, because this function will **not**
- do such conversion for you from `torch.complex32`, in case you want the
- smaller RAM usage on purpose.
-
- It is usually always better in terms of quality to have double
- precision, by e.g. calling :func:`expectation_maximization`
- with ``x.to(torch.float64)``.
- """
- # dimensions
- (nb_frames, nb_bins, nb_channels) = x.shape[:-1]
- nb_sources = y.shape[-1]
-
- regularization = torch.cat(
- (
- torch.eye(nb_channels, dtype=x.dtype, device=x.device)[..., None],
- torch.zeros((nb_channels, nb_channels, 1), dtype=x.dtype, device=x.device),
- ),
- dim=2,
- )
- regularization = torch.sqrt(torch.as_tensor(eps)) * (
- regularization[None, None, ...].expand((-1, nb_bins, -1, -1, -1))
- )
-
- # allocate the spatial covariance matrices
- R = [
- torch.zeros((nb_bins, nb_channels, nb_channels, 2), dtype=x.dtype, device=x.device)
- for j in range(nb_sources)
- ]
- weight: torch.Tensor = torch.zeros((nb_bins,), dtype=x.dtype, device=x.device)
-
- v: torch.Tensor = torch.zeros((nb_frames, nb_bins, nb_sources), dtype=x.dtype, device=x.device)
- for it in range(iterations):
- # constructing the mixture covariance matrix. Doing it with a loop
- # to avoid storing anytime in RAM the whole 6D tensor
-
- # update the PSD as the average spectrogram over channels
- v = torch.mean(torch.abs(y[..., 0, :]) ** 2 + torch.abs(y[..., 1, :]) ** 2, dim=-2)
-
- # update spatial covariance matrices (weighted update)
- for j in range(nb_sources):
- R[j] = torch.tensor(0.0, device=x.device)
- weight = torch.tensor(eps, device=x.device)
- pos: int = 0
- batch_size = batch_size if batch_size else nb_frames
- while pos < nb_frames:
- t = torch.arange(pos, min(nb_frames, pos + batch_size))
- pos = int(t[-1]) + 1
-
- R[j] = R[j] + torch.sum(_covariance(y[t, ..., j]), dim=0)
- weight = weight + torch.sum(v[t, ..., j], dim=0)
- R[j] = R[j] / weight[..., None, None, None]
- weight = torch.zeros_like(weight)
-
- # cloning y if we track gradient, because we're going to update it
- if y.requires_grad:
- y = y.clone()
-
- pos = 0
- while pos < nb_frames:
- t = torch.arange(pos, min(nb_frames, pos + batch_size))
- pos = int(t[-1]) + 1
-
- y[t, ...] = torch.tensor(0.0, device=x.device, dtype=x.dtype)
-
- # compute mix covariance matrix
- Cxx = regularization
- for j in range(nb_sources):
- Cxx = Cxx + (v[t, ..., j, None, None, None] * R[j][None, ...].clone())
-
- # invert it
- inv_Cxx = _invert(Cxx)
-
- # separate the sources
- for j in range(nb_sources):
-
- # create a wiener gain for this source
- gain = torch.zeros_like(inv_Cxx)
-
- # computes multichannel Wiener gain as v_j R_j inv_Cxx
- indices = torch.cartesian_prod(
- torch.arange(nb_channels),
- torch.arange(nb_channels),
- torch.arange(nb_channels),
- )
- for index in indices:
- gain[:, :, index[0], index[1], :] = _mul_add(
- R[j][None, :, index[0], index[2], :].clone(),
- inv_Cxx[:, :, index[2], index[1], :],
- gain[:, :, index[0], index[1], :],
- )
- gain = gain * v[t, ..., None, None, None, j]
-
- # apply it to the mixture
- for i in range(nb_channels):
- y[t, ..., j] = _mul_add(gain[..., i, :], x[t, ..., i, None, :], y[t, ..., j])
-
- return y, v, R
-
-
-def wiener(
- targets_spectrograms: torch.Tensor,
- mix_stft: torch.Tensor,
- iterations: int = 1,
- softmask: bool = False,
- residual: bool = False,
- scale_factor: float = 10.0,
- eps: float = 1e-10,
-):
- """Wiener-based separation for multichannel audio.
-
- The method uses the (possibly multichannel) spectrograms of the
- sources to separate the (complex) Short Term Fourier Transform of the
- mix. Separation is done in a sequential way by:
-
- * Getting an initial estimate. This can be done in two ways: either by
- directly using the spectrograms with the mixture phase, or
- by using a softmasking strategy. This initial phase is controlled
- by the `softmask` flag.
-
- * If required, adding an additional residual target as the mix minus
- all targets.
-
- * Refinining these initial estimates through a call to
- :func:`expectation_maximization` if the number of iterations is nonzero.
-
- This implementation also allows to specify the epsilon value used for
- regularization. It is based on [1]_, [2]_, [3]_, [4]_.
-
- References
- ----------
- .. [1] S. Uhlich and M. Porcu and F. Giron and M. Enenkl and T. Kemp and
- N. Takahashi and Y. Mitsufuji, "Improving music source separation based
- on deep neural networks through data augmentation and network
- blending." 2017 IEEE International Conference on Acoustics, Speech
- and Signal Processing (ICASSP). IEEE, 2017.
-
- .. [2] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel audio source
- separation with deep neural networks." IEEE/ACM Transactions on Audio,
- Speech, and Language Processing 24.9 (2016): 1652-1664.
-
- .. [3] A. Nugraha and A. Liutkus and E. Vincent. "Multichannel music
- separation with deep neural networks." 2016 24th European Signal
- Processing Conference (EUSIPCO). IEEE, 2016.
-
- .. [4] A. Liutkus and R. Badeau and G. Richard "Kernel additive models for
- source separation." IEEE Transactions on Signal Processing
- 62.16 (2014): 4298-4310.
-
- Args:
- targets_spectrograms (Tensor): spectrograms of the sources
- [shape=(nb_frames, nb_bins, nb_channels, nb_sources)].
- This is a nonnegative tensor that is
- usually the output of the actual separation method of the user. The
- spectrograms may be mono, but they need to be 4-dimensional in all
- cases.
- mix_stft (Tensor): [shape=(nb_frames, nb_bins, nb_channels, complex=2)]
- STFT of the mixture signal.
- iterations (int): [scalar]
- number of iterations for the EM algorithm
- softmask (bool): Describes how the initial estimates are obtained.
- * if `False`, then the mixture phase will directly be used with the
- spectrogram as initial estimates.
- * if `True`, initial estimates are obtained by multiplying the
- complex mix element-wise with the ratio of each target spectrogram
- with the sum of them all. This strategy is better if the model are
- not really good, and worse otherwise.
- residual (bool): if `True`, an additional target is created, which is
- equal to the mixture minus the other targets, before application of
- expectation maximization
- eps (float): Epsilon value to use for computing the separations.
- This is used whenever division with a model energy is
- performed, i.e. when softmasking and when iterating the EM.
- It can be understood as the energy of the additional white noise
- that is taken out when separating.
-
- Returns:
- Tensor: shape=(nb_frames, nb_bins, nb_channels, complex=2, nb_sources)
- STFT of estimated sources
-
- Notes:
- * Be careful that you need *magnitude spectrogram estimates* for the
- case `softmask==False`.
- * `softmask=False` is recommended
- * The epsilon value will have a huge impact on performance. If it's
- large, only the parts of the signal with a significant energy will
- be kept in the sources. This epsilon then directly controls the
- energy of the reconstruction error.
-
- Warning:
- As in :func:`expectation_maximization`, we recommend converting the
- mixture `x` to double precision `torch.float64` *before* calling
- :func:`wiener`.
- """
- if softmask:
- # if we use softmask, we compute the ratio mask for all targets and
- # multiply by the mix stft
- y = (
- mix_stft[..., None]
- * (
- targets_spectrograms
- / (eps + torch.sum(targets_spectrograms, dim=-1, keepdim=True).to(mix_stft.dtype))
- )[..., None, :]
- )
- else:
- # otherwise, we just multiply the targets spectrograms with mix phase
- # we tacitly assume that we have magnitude estimates.
- angle = atan2(mix_stft[..., 1], mix_stft[..., 0])[..., None]
- nb_sources = targets_spectrograms.shape[-1]
- y = torch.zeros(
- mix_stft.shape + (nb_sources,), dtype=mix_stft.dtype, device=mix_stft.device
- )
- y[..., 0, :] = targets_spectrograms * torch.cos(angle)
- y[..., 1, :] = targets_spectrograms * torch.sin(angle)
-
- if residual:
- # if required, adding an additional target as the mix minus
- # available targets
- y = torch.cat([y, mix_stft[..., None] - y.sum(dim=-1, keepdim=True)], dim=-1)
-
- if iterations == 0:
- return y
-
- # we need to refine the estimates. Scales down the estimates for
- # numerical stability
- max_abs = torch.max(
- torch.as_tensor(1.0, dtype=mix_stft.dtype, device=mix_stft.device),
- torch.sqrt(_norm(mix_stft)).max() / scale_factor,
- )
-
- mix_stft = mix_stft / max_abs
- y = y / max_abs
-
- # call expectation maximization
- y = expectation_maximization(y, mix_stft, iterations, eps=eps)[0]
-
- # scale estimates up again
- y = y * max_abs
- return y
-
-
-def _covariance(y_j):
- """
- Compute the empirical covariance for a source.
-
- Args:
- y_j (Tensor): complex stft of the source.
- [shape=(nb_frames, nb_bins, nb_channels, 2)].
-
- Returns:
- Cj (Tensor): [shape=(nb_frames, nb_bins, nb_channels, nb_channels, 2)]
- just y_j * conj(y_j.T): empirical covariance for each TF bin.
- """
- (nb_frames, nb_bins, nb_channels) = y_j.shape[:-1]
- Cj = torch.zeros(
- (nb_frames, nb_bins, nb_channels, nb_channels, 2),
- dtype=y_j.dtype,
- device=y_j.device,
- )
- indices = torch.cartesian_prod(torch.arange(nb_channels), torch.arange(nb_channels))
- for index in indices:
- Cj[:, :, index[0], index[1], :] = _mul_add(
- y_j[:, :, index[0], :],
- _conj(y_j[:, :, index[1], :]),
- Cj[:, :, index[0], index[1], :],
- )
- return Cj
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/model.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/model.py
deleted file mode 100644
index 6c54776fef03da7fc71542fb0cc4556077bd6e64..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/model.py
+++ /dev/null
@@ -1,347 +0,0 @@
-from typing import Optional, Mapping
-
-import numpy as np
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from torch import Tensor
-from torch.nn import LSTM, BatchNorm1d, Linear, Parameter
-from .filtering import wiener
-from .transforms import make_filterbanks, ComplexNorm
-
-
-class OpenUnmix(nn.Module):
- """OpenUnmix Core spectrogram based separation module.
-
- Args:
- nb_bins (int): Number of input time-frequency bins (Default: `4096`).
- nb_channels (int): Number of input audio channels (Default: `2`).
- hidden_size (int): Size for bottleneck layers (Default: `512`).
- nb_layers (int): Number of Bi-LSTM layers (Default: `3`).
- unidirectional (bool): Use causal model useful for realtime purpose.
- (Default `False`)
- input_mean (ndarray or None): global data mean of shape `(nb_bins, )`.
- Defaults to zeros(nb_bins)
- input_scale (ndarray or None): global data mean of shape `(nb_bins, )`.
- Defaults to ones(nb_bins)
- max_bin (int or None): Internal frequency bin threshold to
- reduce high frequency content. Defaults to `None` which results
- in `nb_bins`
- """
-
- def __init__(
- self,
- nb_bins: int = 4096,
- nb_channels: int = 2,
- hidden_size: int = 512,
- nb_layers: int = 3,
- unidirectional: bool = False,
- input_mean: Optional[np.ndarray] = None,
- input_scale: Optional[np.ndarray] = None,
- max_bin: Optional[int] = None,
- ):
- super(OpenUnmix, self).__init__()
-
- self.nb_output_bins = nb_bins
- if max_bin:
- self.nb_bins = max_bin
- else:
- self.nb_bins = self.nb_output_bins
-
- self.hidden_size = hidden_size
-
- self.fc1 = Linear(self.nb_bins * nb_channels, hidden_size, bias=False)
-
- self.bn1 = BatchNorm1d(hidden_size)
-
- if unidirectional:
- lstm_hidden_size = hidden_size
- else:
- lstm_hidden_size = hidden_size // 2
-
- self.lstm = LSTM(
- input_size=hidden_size,
- hidden_size=lstm_hidden_size,
- num_layers=nb_layers,
- bidirectional=not unidirectional,
- batch_first=False,
- dropout=0.4 if nb_layers > 1 else 0,
- )
-
- fc2_hiddensize = hidden_size * 2
- self.fc2 = Linear(in_features=fc2_hiddensize, out_features=hidden_size, bias=False)
-
- self.bn2 = BatchNorm1d(hidden_size)
-
- self.fc3 = Linear(
- in_features=hidden_size,
- out_features=self.nb_output_bins * nb_channels,
- bias=False,
- )
-
- self.bn3 = BatchNorm1d(self.nb_output_bins * nb_channels)
-
- if input_mean is not None:
- input_mean = torch.from_numpy(-input_mean[: self.nb_bins]).float()
- else:
- input_mean = torch.zeros(self.nb_bins)
-
- if input_scale is not None:
- input_scale = torch.from_numpy(1.0 / input_scale[: self.nb_bins]).float()
- else:
- input_scale = torch.ones(self.nb_bins)
-
- self.input_mean = Parameter(input_mean)
- self.input_scale = Parameter(input_scale)
-
- self.output_scale = Parameter(torch.ones(self.nb_output_bins).float())
- self.output_mean = Parameter(torch.ones(self.nb_output_bins).float())
-
- def freeze(self):
- # set all parameters as not requiring gradient, more RAM-efficient
- # at test time
- for p in self.parameters():
- p.requires_grad = False
- self.eval()
-
- def forward(self, x: Tensor) -> Tensor:
- """
- Args:
- x: input spectrogram of shape
- `(nb_samples, nb_channels, nb_bins, nb_frames)`
-
- Returns:
- Tensor: filtered spectrogram of shape
- `(nb_samples, nb_channels, nb_bins, nb_frames)`
- """
-
- # permute so that batch is last for lstm
- x = x.permute(3, 0, 1, 2)
- # get current spectrogram shape
- nb_frames, nb_samples, nb_channels, nb_bins = x.data.shape
-
- mix = x.detach().clone()
-
- # crop
- x = x[..., : self.nb_bins]
- # shift and scale input to mean=0 std=1 (across all bins)
- x = x + self.input_mean
- x = x * self.input_scale
-
- # to (nb_frames*nb_samples, nb_channels*nb_bins)
- # and encode to (nb_frames*nb_samples, hidden_size)
- x = self.fc1(x.reshape(-1, nb_channels * self.nb_bins))
- # normalize every instance in a batch
- x = self.bn1(x)
- x = x.reshape(nb_frames, nb_samples, self.hidden_size)
- # squash range ot [-1, 1]
- x = torch.tanh(x)
-
- # apply 3-layers of stacked LSTM
- lstm_out = self.lstm(x)
-
- # lstm skip connection
- x = torch.cat([x, lstm_out[0]], -1)
-
- # first dense stage + batch norm
- x = self.fc2(x.reshape(-1, x.shape[-1]))
- x = self.bn2(x)
-
- x = F.relu(x)
-
- # second dense stage + layer norm
- x = self.fc3(x)
- x = self.bn3(x)
-
- # reshape back to original dim
- x = x.reshape(nb_frames, nb_samples, nb_channels, self.nb_output_bins)
-
- # apply output scaling
- x *= self.output_scale
- x += self.output_mean
-
- # since our output is non-negative, we can apply RELU
- x = F.relu(x) * mix
- # permute back to (nb_samples, nb_channels, nb_bins, nb_frames)
- return x.permute(1, 2, 3, 0)
-
-
-class Separator(nn.Module):
- """
- Separator class to encapsulate all the stereo filtering
- as a torch Module, to enable end-to-end learning.
-
- Args:
- targets (dict of str: nn.Module): dictionary of target models
- the spectrogram models to be used by the Separator.
- niter (int): Number of EM steps for refining initial estimates in a
- post-processing stage. Zeroed if only one target is estimated.
- defaults to `1`.
- residual (bool): adds an additional residual target, obtained by
- subtracting the other estimated targets from the mixture,
- before any potential EM post-processing.
- Defaults to `False`.
- wiener_win_len (int or None): The size of the excerpts
- (number of frames) on which to apply filtering
- independently. This means assuming time varying stereo models and
- localization of sources.
- None means not batching but using the whole signal. It comes at the
- price of a much larger memory usage.
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
- """
-
- def __init__(
- self,
- target_models: Mapping[str, nn.Module],
- niter: int = 0,
- softmask: bool = False,
- residual: bool = False,
- sample_rate: float = 44100.0,
- n_fft: int = 4096,
- n_hop: int = 1024,
- nb_channels: int = 2,
- wiener_win_len: Optional[int] = 300,
- filterbank: str = "torch",
- ):
- super(Separator, self).__init__()
-
- # saving parameters
- self.niter = niter
- self.residual = residual
- self.softmask = softmask
- self.wiener_win_len = wiener_win_len
-
- self.stft, self.istft = make_filterbanks(
- n_fft=n_fft,
- n_hop=n_hop,
- center=True,
- method=filterbank,
- sample_rate=sample_rate,
- )
- self.complexnorm = ComplexNorm(mono=nb_channels == 1)
-
- # registering the targets models
- self.target_models = nn.ModuleDict(target_models)
- # adding till https://github.com/pytorch/pytorch/issues/38963
- self.nb_targets = len(self.target_models)
- # get the sample_rate as the sample_rate of the first model
- # (tacitly assume it's the same for all targets)
- self.register_buffer("sample_rate", torch.as_tensor(sample_rate))
-
- def freeze(self):
- # set all parameters as not requiring gradient, more RAM-efficient
- # at test time
- for p in self.parameters():
- p.requires_grad = False
- self.eval()
-
- def forward(self, audio: Tensor) -> Tensor:
- """Performing the separation on audio input
-
- Args:
- audio (Tensor): [shape=(nb_samples, nb_channels, nb_timesteps)]
- mixture audio waveform
-
- Returns:
- Tensor: stacked tensor of separated waveforms
- shape `(nb_samples, nb_targets, nb_channels, nb_timesteps)`
- """
-
- nb_sources = self.nb_targets
- nb_samples = audio.shape[0]
-
- # getting the STFT of mix:
- # (nb_samples, nb_channels, nb_bins, nb_frames, 2)
- mix_stft = self.stft(audio)
- X = self.complexnorm(mix_stft)
-
- # initializing spectrograms variable
- spectrograms = torch.zeros(X.shape + (nb_sources,), dtype=audio.dtype, device=X.device)
-
- for j, (target_name, target_module) in enumerate(self.target_models.items()):
- # apply current model to get the source spectrogram
- target_spectrogram = target_module(X.detach().clone())
- spectrograms[..., j] = target_spectrogram
-
- # transposing it as
- # (nb_samples, nb_frames, nb_bins,{1,nb_channels}, nb_sources)
- spectrograms = spectrograms.permute(0, 3, 2, 1, 4)
-
- # rearranging it into:
- # (nb_samples, nb_frames, nb_bins, nb_channels, 2) to feed
- # into filtering methods
- mix_stft = mix_stft.permute(0, 3, 2, 1, 4)
-
- # create an additional target if we need to build a residual
- if self.residual:
- # we add an additional target
- nb_sources += 1
-
- if nb_sources == 1 and self.niter > 0:
- raise Exception(
- "Cannot use EM if only one target is estimated."
- "Provide two targets or create an additional "
- "one with `--residual`"
- )
-
- nb_frames = spectrograms.shape[1]
- targets_stft = torch.zeros(
- mix_stft.shape + (nb_sources,), dtype=audio.dtype, device=mix_stft.device
- )
- for sample in range(nb_samples):
- pos = 0
- if self.wiener_win_len:
- wiener_win_len = self.wiener_win_len
- else:
- wiener_win_len = nb_frames
- while pos < nb_frames:
- cur_frame = torch.arange(pos, min(nb_frames, pos + wiener_win_len))
- pos = int(cur_frame[-1]) + 1
-
- targets_stft[sample, cur_frame] = wiener(
- spectrograms[sample, cur_frame],
- mix_stft[sample, cur_frame],
- self.niter,
- softmask=self.softmask,
- residual=self.residual,
- )
-
- # getting to (nb_samples, nb_targets, channel, fft_size, n_frames, 2)
- targets_stft = targets_stft.permute(0, 5, 3, 2, 1, 4).contiguous()
-
- # inverse STFT
- estimates = self.istft(targets_stft, length=audio.shape[2])
-
- return estimates
-
- def to_dict(self, estimates: Tensor, aggregate_dict: Optional[dict] = None) -> dict:
- """Convert estimates as stacked tensor to dictionary
-
- Args:
- estimates (Tensor): separated targets of shape
- (nb_samples, nb_targets, nb_channels, nb_timesteps)
- aggregate_dict (dict or None)
-
- Returns:
- (dict of str: Tensor):
- """
- estimates_dict = {}
- for k, target in enumerate(self.target_models):
- estimates_dict[target] = estimates[:, k, ...]
-
- # in the case of residual, we added another source
- if self.residual:
- estimates_dict["residual"] = estimates[:, -1, ...]
-
- if aggregate_dict is not None:
- new_estimates = {}
- for key in aggregate_dict:
- new_estimates[key] = torch.tensor(0.0)
- for target in aggregate_dict[key]:
- new_estimates[key] = new_estimates[key] + estimates_dict[target]
- estimates_dict = new_estimates
- return estimates_dict
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/predict.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/predict.py
deleted file mode 100644
index 254feb3d9e7543438a59bb59ccfb19bcf029b887..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/predict.py
+++ /dev/null
@@ -1,80 +0,0 @@
-from openunmix import utils
-
-
-def separate(
- audio,
- rate=None,
- model_str_or_path="umxl",
- targets=None,
- niter=1,
- residual=False,
- wiener_win_len=300,
- aggregate_dict=None,
- separator=None,
- device=None,
- filterbank="torch",
-):
- """
- Open Unmix functional interface
-
- Separates a torch.Tensor or the content of an audio file.
-
- If a separator is provided, use it for inference. If not, create one
- and use it afterwards.
-
- Args:
- audio: audio to process
- torch Tensor: shape (channels, length), and
- `rate` must also be provided.
- rate: int or None: only used if audio is a Tensor. Otherwise,
- inferred from the file.
- model_str_or_path: the pretrained model to use, defaults to UMX-L
- targets (str): select the targets for the source to be separated.
- a list including: ['vocals', 'drums', 'bass', 'other'].
- If you don't pick them all, you probably want to
- activate the `residual=True` option.
- Defaults to all available targets per model.
- niter (int): the number of post-processingiterations, defaults to 1
- residual (bool): if True, a "garbage" target is created
- wiener_win_len (int): the number of frames to use when batching
- the post-processing step
- aggregate_dict (str): if provided, must be a string containing a '
- 'valid expression for a dictionary, with keys as output '
- 'target names, and values a list of targets that are used to '
- 'build it. For instance: \'{\"vocals\":[\"vocals\"], '
- '\"accompaniment\":[\"drums\",\"bass\",\"other\"]}\'
- separator: if provided, the model.Separator object that will be used
- to perform separation
- device (str): selects device to be used for inference
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
- """
- if separator is None:
- separator = utils.load_separator(
- model_str_or_path=model_str_or_path,
- targets=targets,
- niter=niter,
- residual=residual,
- wiener_win_len=wiener_win_len,
- device=device,
- pretrained=True,
- filterbank=filterbank,
- )
- separator.freeze()
- if device:
- separator.to(device)
-
- if rate is None:
- raise Exception("rate` must be provided.")
-
- if device:
- audio = audio.to(device)
- audio = utils.preprocess(audio, rate, separator.sample_rate)
-
- # getting the separated signals
- estimates = separator(audio)
- estimates = separator.to_dict(estimates, aggregate_dict=aggregate_dict)
- return estimates
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/transforms.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/transforms.py
deleted file mode 100644
index 69c30b5895f455af6b270fec2325f5b3c8c0dcc0..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/transforms.py
+++ /dev/null
@@ -1,216 +0,0 @@
-from typing import Optional
-
-import torch
-import torchaudio
-from torch import Tensor
-import torch.nn as nn
-
-try:
- from asteroid_filterbanks.enc_dec import Encoder, Decoder
- from asteroid_filterbanks.transforms import to_torchaudio, from_torchaudio
- from asteroid_filterbanks import torch_stft_fb
-except ImportError:
- pass
-
-
-def make_filterbanks(n_fft=4096, n_hop=1024, center=False, sample_rate=44100.0, method="torch"):
- window = nn.Parameter(torch.hann_window(n_fft), requires_grad=False)
-
- if method == "torch":
- encoder = TorchSTFT(n_fft=n_fft, n_hop=n_hop, window=window, center=center)
- decoder = TorchISTFT(n_fft=n_fft, n_hop=n_hop, window=window, center=center)
- elif method == "asteroid":
- fb = torch_stft_fb.TorchSTFTFB.from_torch_args(
- n_fft=n_fft,
- hop_length=n_hop,
- win_length=n_fft,
- window=window,
- center=center,
- sample_rate=sample_rate,
- )
- encoder = AsteroidSTFT(fb)
- decoder = AsteroidISTFT(fb)
- else:
- raise NotImplementedError
- return encoder, decoder
-
-
-class AsteroidSTFT(nn.Module):
- def __init__(self, fb):
- super(AsteroidSTFT, self).__init__()
- self.enc = Encoder(fb)
-
- def forward(self, x):
- aux = self.enc(x)
- return to_torchaudio(aux)
-
-
-class AsteroidISTFT(nn.Module):
- def __init__(self, fb):
- super(AsteroidISTFT, self).__init__()
- self.dec = Decoder(fb)
-
- def forward(self, X: Tensor, length: Optional[int] = None) -> Tensor:
- aux = from_torchaudio(X)
- return self.dec(aux, length=length)
-
-
-class TorchSTFT(nn.Module):
- """Multichannel Short-Time-Fourier Forward transform
- uses hard coded hann_window.
- Args:
- n_fft (int, optional): transform FFT size. Defaults to 4096.
- n_hop (int, optional): transform hop size. Defaults to 1024.
- center (bool, optional): If True, the signals first window is
- zero padded. Centering is required for a perfect
- reconstruction of the signal. However, during training
- of spectrogram models, it can safely turned off.
- Defaults to `true`
- window (nn.Parameter, optional): window function
- """
-
- def __init__(
- self,
- n_fft: int = 4096,
- n_hop: int = 1024,
- center: bool = False,
- window: Optional[nn.Parameter] = None,
- ):
- super(TorchSTFT, self).__init__()
- if window is None:
- self.window = nn.Parameter(torch.hann_window(n_fft), requires_grad=False)
- else:
- self.window = window
-
- self.n_fft = n_fft
- self.n_hop = n_hop
- self.center = center
-
- def forward(self, x: Tensor) -> Tensor:
- """STFT forward path
- Args:
- x (Tensor): audio waveform of
- shape (nb_samples, nb_channels, nb_timesteps)
- Returns:
- STFT (Tensor): complex stft of
- shape (nb_samples, nb_channels, nb_bins, nb_frames, complex=2)
- last axis is stacked real and imaginary
- """
-
- shape = x.size()
- nb_samples, nb_channels, nb_timesteps = shape
-
- # pack batch
- x = x.view(-1, shape[-1])
-
- complex_stft = torch.stft(
- x,
- n_fft=self.n_fft,
- hop_length=self.n_hop,
- window=self.window,
- center=self.center,
- normalized=False,
- onesided=True,
- pad_mode="reflect",
- return_complex=True,
- )
- stft_f = torch.view_as_real(complex_stft)
- # unpack batch
- stft_f = stft_f.view(shape[:-1] + stft_f.shape[-3:])
- return stft_f
-
-
-class TorchISTFT(nn.Module):
- """Multichannel Inverse-Short-Time-Fourier functional
- wrapper for torch.istft to support batches
- Args:
- STFT (Tensor): complex stft of
- shape (nb_samples, nb_channels, nb_bins, nb_frames, complex=2)
- last axis is stacked real and imaginary
- n_fft (int, optional): transform FFT size. Defaults to 4096.
- n_hop (int, optional): transform hop size. Defaults to 1024.
- window (callable, optional): window function
- center (bool, optional): If True, the signals first window is
- zero padded. Centering is required for a perfect
- reconstruction of the signal. However, during training
- of spectrogram models, it can safely turned off.
- Defaults to `true`
- length (int, optional): audio signal length to crop the signal
- Returns:
- x (Tensor): audio waveform of
- shape (nb_samples, nb_channels, nb_timesteps)
- """
-
- def __init__(
- self,
- n_fft: int = 4096,
- n_hop: int = 1024,
- center: bool = False,
- sample_rate: float = 44100.0,
- window: Optional[nn.Parameter] = None,
- ) -> None:
- super(TorchISTFT, self).__init__()
-
- self.n_fft = n_fft
- self.n_hop = n_hop
- self.center = center
- self.sample_rate = sample_rate
-
- if window is None:
- self.window = nn.Parameter(torch.hann_window(n_fft), requires_grad=False)
- else:
- self.window = window
-
- def forward(self, X: Tensor, length: Optional[int] = None) -> Tensor:
- shape = X.size()
- X = X.reshape(-1, shape[-3], shape[-2], shape[-1])
-
- y = torch.istft(
- torch.view_as_complex(X),
- n_fft=self.n_fft,
- hop_length=self.n_hop,
- window=self.window,
- center=self.center,
- normalized=False,
- onesided=True,
- length=length,
- )
-
- y = y.reshape(shape[:-3] + y.shape[-1:])
-
- return y
-
-
-class ComplexNorm(nn.Module):
- r"""Compute the norm of complex tensor input.
-
- Extension of `torchaudio.functional.complex_norm` with mono
-
- Args:
- mono (bool): Downmix to single channel after applying power norm
- to maximize
- """
-
- def __init__(self, mono: bool = False):
- super(ComplexNorm, self).__init__()
- self.mono = mono
-
- def forward(self, spec: Tensor) -> Tensor:
- """
- Args:
- spec: complex_tensor (Tensor): Tensor shape of
- `(..., complex=2)`
-
- Returns:
- Tensor: Power/Mag of input
- `(...,)`
- """
- # take the magnitude
-
- spec = torch.abs(torch.view_as_complex(spec))
-
- # downmix in the mag domain to preserve energy
- if self.mono:
- spec = torch.mean(spec, 1, keepdim=True)
-
- return spec
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/utils.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/utils.py
deleted file mode 100644
index bece46f847bf1e4685cc58d9ac5ab0443e32a481..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/openunmix/utils.py
+++ /dev/null
@@ -1,305 +0,0 @@
-from typing import Optional, Union
-
-import torch
-import os
-import numpy as np
-import torchaudio
-import warnings
-from pathlib import Path
-from contextlib import redirect_stderr
-import io
-import json
-
-import openunmix
-from openunmix import model
-
-
-def bandwidth_to_max_bin(rate: float, n_fft: int, bandwidth: float) -> np.ndarray:
- """Convert bandwidth to maximum bin count
-
- Assuming lapped transforms such as STFT
-
- Args:
- rate (int): Sample rate
- n_fft (int): FFT length
- bandwidth (float): Target bandwidth in Hz
-
- Returns:
- np.ndarray: maximum frequency bin
- """
- freqs = np.linspace(0, rate / 2, n_fft // 2 + 1, endpoint=True)
-
- return np.max(np.where(freqs <= bandwidth)[0]) + 1
-
-
-def save_checkpoint(state: dict, is_best: bool, path: str, target: str):
- """Convert bandwidth to maximum bin count
-
- Assuming lapped transforms such as STFT
-
- Args:
- state (dict): torch model state dict
- is_best (bool): if current model is about to be saved as best model
- path (str): model path
- target (str): target name
- """
- # save full checkpoint including optimizer
- torch.save(state, os.path.join(path, target + ".chkpnt"))
- if is_best:
- # save just the weights
- torch.save(state["state_dict"], os.path.join(path, target + ".pth"))
-
-
-class AverageMeter(object):
- """Computes and stores the average and current value"""
-
- def __init__(self):
- self.reset()
-
- def reset(self):
- self.val = 0
- self.avg = 0
- self.sum = 0
- self.count = 0
-
- def update(self, val, n=1):
- self.val = val
- self.sum += val * n
- self.count += n
- self.avg = self.sum / self.count
-
-
-class EarlyStopping(object):
- """Early Stopping Monitor"""
-
- def __init__(self, mode="min", min_delta=0, patience=10):
- self.mode = mode
- self.min_delta = min_delta
- self.patience = patience
- self.best = None
- self.num_bad_epochs = 0
- self.is_better = None
- self._init_is_better(mode, min_delta)
-
- if patience == 0:
- self.is_better = lambda a, b: True
-
- def step(self, metrics):
- if self.best is None:
- self.best = metrics
- return False
-
- if np.isnan(metrics):
- return True
-
- if self.is_better(metrics, self.best):
- self.num_bad_epochs = 0
- self.best = metrics
- else:
- self.num_bad_epochs += 1
-
- if self.num_bad_epochs >= self.patience:
- return True
-
- return False
-
- def _init_is_better(self, mode, min_delta):
- if mode not in {"min", "max"}:
- raise ValueError("mode " + mode + " is unknown!")
- if mode == "min":
- self.is_better = lambda a, best: a < best - min_delta
- if mode == "max":
- self.is_better = lambda a, best: a > best + min_delta
-
-
-def load_target_models(targets, model_str_or_path="umxhq", device="cpu", pretrained=True):
- """Core model loader
-
- target model path can be either <target>.pth, or <target>-sha256.pth
- (as used on torchub)
-
- The loader either loads the models from a known model string
- as registered in the __init__.py or loads from custom configs.
- """
- if isinstance(targets, str):
- targets = [targets]
-
- model_path = Path(model_str_or_path).expanduser()
- if not model_path.exists():
- # model path does not exist, use pretrained models
- try:
- # disable progress bar
- hub_loader = getattr(openunmix, model_str_or_path + "_spec")
- err = io.StringIO()
- with redirect_stderr(err):
- return hub_loader(targets=targets, device=device, pretrained=pretrained)
- print(err.getvalue())
- except AttributeError:
- raise NameError("Model does not exist on torchhub")
- # assume model is a path to a local model_str_or_path directory
- else:
- models = {}
- for target in targets:
- # load model from disk
- with open(Path(model_path, target + ".json"), "r") as stream:
- results = json.load(stream)
-
- target_model_path = next(Path(model_path).glob("%s*.pth" % target))
- state = torch.load(target_model_path, map_location=device)
-
- models[target] = model.OpenUnmix(
- nb_bins=results["args"]["nfft"] // 2 + 1,
- nb_channels=results["args"]["nb_channels"],
- hidden_size=results["args"]["hidden_size"],
- max_bin=state["input_mean"].shape[0],
- )
-
- if pretrained:
- models[target].load_state_dict(state, strict=False)
-
- models[target].to(device)
- return models
-
-
-def load_separator(
- model_str_or_path: str = "umxhq",
- targets: Optional[list] = None,
- niter: int = 1,
- residual: bool = False,
- wiener_win_len: Optional[int] = 300,
- device: Union[str, torch.device] = "cpu",
- pretrained: bool = True,
- filterbank: str = "torch",
-):
- """Separator loader
-
- Args:
- model_str_or_path (str): Model name or path to model _parent_ directory
- E.g. The following files are assumed to present when
- loading `model_str_or_path='mymodel', targets=['vocals']`
- 'mymodel/separator.json', mymodel/vocals.pth', 'mymodel/vocals.json'.
- Defaults to `umxhq`.
- targets (list of str or None): list of target names. When loading a
- pre-trained model, all `targets` can be None as all targets
- will be loaded
- niter (int): Number of EM steps for refining initial estimates
- in a post-processing stage. `--niter 0` skips this step altogether
- (and thus makes separation significantly faster) More iterations
- can get better interference reduction at the price of artifacts.
- Defaults to `1`.
- residual (bool): Computes a residual target, for custom separation
- scenarios when not all targets are available (at the expense
- of slightly less performance). E.g vocal/accompaniment
- Defaults to `False`.
- wiener_win_len (int): The size of the excerpts (number of frames) on
- which to apply filtering independently. This means assuming
- time varying stereo models and localization of sources.
- None means not batching but using the whole signal. It comes at the
- price of a much larger memory usage.
- Defaults to `300`
- device (str): torch device, defaults to `cpu`
- pretrained (bool): determines if loading pre-trained weights
- filterbank (str): filterbank implementation method.
- Supported are `['torch', 'asteroid']`. `torch` is about 30% faster
- compared to `asteroid` on large FFT sizes such as 4096. However,
- asteroids stft can be exported to onnx, which makes is practical
- for deployment.
- """
- model_path = Path(model_str_or_path).expanduser()
-
- # when path exists, we assume its a custom model saved locally
- if model_path.exists():
- if targets is None:
- raise UserWarning("For custom models, please specify the targets")
-
- target_models = load_target_models(
- targets=targets, model_str_or_path=model_path, pretrained=pretrained
- )
-
- with open(Path(model_path, "separator.json"), "r") as stream:
- enc_conf = json.load(stream)
-
- separator = model.Separator(
- target_models=target_models,
- niter=niter,
- residual=residual,
- wiener_win_len=wiener_win_len,
- sample_rate=enc_conf["sample_rate"],
- n_fft=enc_conf["nfft"],
- n_hop=enc_conf["nhop"],
- nb_channels=enc_conf["nb_channels"],
- filterbank=filterbank,
- ).to(device)
-
- # otherwise we load the separator from torchhub
- else:
- hub_loader = getattr(openunmix, model_str_or_path)
- separator = hub_loader(
- targets=targets,
- device=device,
- pretrained=True,
- niter=niter,
- residual=residual,
- filterbank=filterbank,
- )
-
- return separator
-
-
-def preprocess(
- audio: torch.Tensor,
- rate: Optional[float] = None,
- model_rate: Optional[float] = None,
-) -> torch.Tensor:
- """
- From an input tensor, convert it to a tensor of shape
- shape=(nb_samples, nb_channels, nb_timesteps). This includes:
- - if input is 1D, adding the samples and channels dimensions.
- - if input is 2D
- o and the smallest dimension is 1 or 2, adding the samples one.
- o and all dimensions are > 2, assuming the smallest is the samples
- one, and adding the channel one
- - at the end, if the number of channels is greater than the number
- of time steps, swap those two.
- - resampling to target rate if necessary
-
- Args:
- audio (Tensor): input waveform
- rate (float): sample rate for the audio
- model_rate (float): sample rate for the model
-
- Returns:
- Tensor: [shape=(nb_samples, nb_channels=2, nb_timesteps)]
- """
- shape = torch.as_tensor(audio.shape, device=audio.device)
-
- if len(shape) == 1:
- # assuming only time dimension is provided.
- audio = audio[None, None, ...]
- elif len(shape) == 2:
- if shape.min() <= 2:
- # assuming sample dimension is missing
- audio = audio[None, ...]
- else:
- # assuming channel dimension is missing
- audio = audio[:, None, ...]
- if audio.shape[1] > audio.shape[2]:
- # swapping channel and time
- audio = audio.transpose(1, 2)
- if audio.shape[1] > 2:
- warnings.warn("Channel count > 2!. Only the first two channels " "will be processed!")
- audio = audio[..., :2]
-
- if audio.shape[1] == 1:
- # if we have mono, we duplicate it to get stereo
- audio = torch.repeat_interleave(audio, 2, dim=1)
-
- if rate != model_rate:
- warnings.warn("resample to model sample rate")
- # we have to resample to model samplerate if needed
- # this makes sure we resample input only once
- resampler = torchaudio.transforms.Resample(
- orig_freq=rate, new_freq=model_rate, resampling_method="sinc_interpolation"
- ).to(audio.device)
- audio = resampler(audio)
- return audio
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/pdoc/config.mako b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/pdoc/config.mako
deleted file mode 100644
index e195864b1c2725db134a3cf7fbd71fb48a8b1a2a..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/pdoc/config.mako
+++ /dev/null
@@ -1,53 +0,0 @@
-<%!
- # Template configuration. Copy over in your template directory
- # (used with `--template-dir`) and adapt as necessary.
- # Note, defaults are loaded from this distribution file, so your
- # config.mako only needs to contain values you want overridden.
- # You can also run pdoc with `--config KEY=VALUE` to override
- # individual values.
- html_lang = 'en'
- show_inherited_members = False
- extract_module_toc_into_sidebar = True
- list_class_variables_in_index = True
- sort_identifiers = True
- show_type_annotations = True
- # Show collapsed source code block next to each item.
- # Disabling this can improve rendering speed of large modules.
- show_source_code = True
- # If set, format links to objects in online source code repository
- # according to this template. Supported keywords for interpolation
- # are: commit, path, start_line, end_line.
- git_link_template = 'https://github.com/sigsep/open-unmix-pytorch/blob/{commit}/{path}#L{start_line}-L{end_line}'
- #git_link_template = 'https://gitlab.com/USER/PROJECT/blob/{commit}/{path}#L{start_line}-L{end_line}'
- #git_link_template = 'https://bitbucket.org/USER/PROJECT/src/{commit}/{path}#lines-{start_line}:{end_line}'
- #git_link_template = 'https://CGIT_HOSTNAME/PROJECT/tree/{path}?id={commit}#n{start-line}'
- # A prefix to use for every HTML hyperlink in the generated documentation.
- # No prefix results in all links being relative.
- link_prefix = ''
- # Enable syntax highlighting for code/source blocks by including Highlight.js
- syntax_highlighting = True
- # Set the style keyword such as 'atom-one-light' or 'github-gist'
- # Options: https://github.com/highlightjs/highlight.js/tree/master/src/styles
- # Demo: https://highlightjs.org/static/demo/
- hljs_style = 'github'
- # If set, insert Google Analytics tracking code. Value is GA
- # tracking id (UA-XXXXXX-Y).
- google_analytics = ''
- # If set, insert Google Custom Search search bar widget above the sidebar index.
- # The whitespace-separated tokens represent arbitrary extra queries (at least one
- # must match) passed to regular Google search. Example:
- #google_search_query = 'inurl:github.com/USER/PROJECT site:PROJECT.github.io site:PROJECT.website'
- google_search_query = ''
- # Enable offline search using Lunr.js. For explanation of 'fuzziness' parameter, which is
- # added to every query word, see: https://lunrjs.com/guides/searching.html#fuzzy-matches
- # If 'index_docstrings' is False, a shorter index is built, indexing only
- # the full object reference names.
- #lunr_search = {'fuzziness': 1, 'index_docstrings': True}
- lunr_search = None
- # If set, render LaTeX math syntax within \(...\) (inline equations),
- # or within \[...\] or $$...$$ or `.. math::` (block equations)
- # as nicely-formatted math formulas using MathJax.
- # Note: in Python docstrings, either all backslashes need to be escaped (\\)
- # or you need to use raw r-strings.
- latex_math = True
-%>
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/pyproject.toml b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/pyproject.toml
deleted file mode 100644
index 6ae8cc226e96421c8b90adffab4ae1d293a0d3fb..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/pyproject.toml
+++ /dev/null
@@ -1,5 +0,0 @@
-[tool.black]
-# https://github.com/psf/black
-line-length = 100
-target-version = ["py37"]
-exclude = "(.eggs|.git|.hg|.mypy_cache|.nox|.tox|.venv|.svn|_build|buck-out|build|dist)"
\ No newline at end of file
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/README.md b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/README.md
deleted file mode 100644
index 4a0b2bc232d7de2c83f9d8e8dfe5bd0b6c0ca315..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/README.md
+++ /dev/null
@@ -1,249 +0,0 @@
-# _Open-Unmix_ for PyTorch: end-to-end torch branch
-
-[](https://joss.theoj.org/papers/571753bc54c5d6dd36382c3d801de41d) [](https://paperswithcode.com/sota/music-source-separation-on-musdb18?p=open-unmix-a-reference-implementation-for)
-
-[](https://colab.research.google.com/drive/1mijF0zGWxN-KaxTnd0q6hayAlrID5fEQ) [](https://gitter.im/sigsep/open-unmix?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge) [](https://groups.google.com/forum/#!forum/open-unmix)
-
-[](https://travis-ci.com/sigsep/open-unmix-pytorch) [](https://cloud.docker.com/u/faroit/repository/docker/faroit/open-unmix-pytorch)
-
-This repository contains the PyTorch (1.0+) implementation of __Open-Unmix__, a deep neural network reference implementation for music source separation, applicable for researchers, audio engineers and artists. __Open-Unmix__ provides ready-to-use models that allow users to separate pop music into four stems: __vocals__, __drums__, __bass__ and the remaining __other__ instruments. The models were pre-trained on the [MUSDB18](https://sigsep.github.io/datasets/musdb.html) dataset. See details at [apply pre-trained model](#getting-started).
-
-## News:
-
-- 06/05/2020: We also added a pre-trained speech enhancement model (`umxse`) provided by Sony. For more information we refer [to this site](https://sigsep.github.io/open-unmix/se)
-
-__Related Projects:__ open-unmix-pytorch | [open-unmix-nnabla](https://github.com/sigsep/open-unmix-nnabla) | [musdb](https://github.com/sigsep/sigsep-mus-db) | [museval](https://github.com/sigsep/sigsep-mus-eval) | [norbert](https://github.com/sigsep/norbert)
-
-## The Model for one source
-
-
-
-To perform separation into multiple sources, _Open-unmix_ comprises multiple models that are trained for each particular target. While this makes the training less comfortable, it allows great flexibility to customize the training data for each target source.
-
-Each _Open-Unmix_ source model is based on a three-layer bidirectional deep LSTM. The model learns to predict the magnitude spectrogram of a target source, like _vocals_, from the magnitude spectrogram of a mixture input. Internally, the prediction is obtained by applying a mask on the input. The model is optimized in the magnitude domain using mean squared error.
-
-### Input Stage
-
-__Open-Unmix__ operates in the time-frequency domain to perform its prediction. The input of the model is either:
-
-* __A time domain__ signal tensor of shape `(nb_samples, nb_channels, nb_timesteps)`, where `nb_samples` are the samples in a batch, `nb_channels` is 1 or 2 for mono or stereo audio, respectively, and `nb_timesteps` is the number of audio samples in the recording.
-
- In that case, the model computes spectrograms with `torch.STFT` on the fly.
-
-* Alternatively _open-unmix_ also takes **magnitude spectrograms** directly (e.g. when pre-computed and loaded from disk).
-
- In that case, the input is of shape `(nb_frames, nb_samples, nb_channels, nb_bins)`, where `nb_frames` and `nb_bins` are the time and frequency-dimensions of a Short-Time-Fourier-Transform.
-
-The input spectrogram is _standardized_ using the global mean and standard deviation for every frequency bin across all frames. Furthermore, we apply batch normalization in multiple stages of the model to make the training more robust against gain variation.
-
-### Dimensionality reduction
-
-The LSTM is not operating on the original input spectrogram resolution. Instead, in the first step after the normalization, the network learns to compresses the frequency and channel axis of the model to reduce redundancy and make the model converge faster.
-
-### Bidirectional-LSTM
-
-The core of __open-unmix__ is a three layer bidirectional [LSTM network](https://dl.acm.org/citation.cfm?id=1246450). Due to its recurrent nature, the model can be trained and evaluated on arbitrary length of audio signals. Since the model takes information from past and future simultaneously, the model cannot be used in an online/real-time manner.
-An uni-directional model can easily be trained as described [here](docs/training.md).
-
-### Output Stage
-
-After applying the LSTM, the signal is decoded back to its original input dimensionality. In the last steps the output is multiplied with the input magnitude spectrogram, so that the models is asked to learn a mask.
-
-## Putting source models together: the `Separator`
-
-For inference, this branch enables a `Separator` pytorch Module, that puts together one _Open-unmix_ model for each desired target, and combines their output through a multichannel generalized Wiener filter, before application of inverse STFTs using `torchaudio`.
-The filtering is a rewriting in torch of the [numpy implementation](https://github.com/sigsep/norbert) used in the main branch.
-
-
-## Getting started
-
-### Installation
-
-For installation we recommend to use the [Anaconda](https://anaconda.org/) python distribution. To create a conda environment for _open-unmix_, simply run:
-
-`conda env create -f environment-X.yml` where `X` is either [`cpu-linux`, `gpu-linux-cuda10`, `cpu-osx`], depending on your system. For now, we haven't tested windows support.
-
-### Using Docker
-
-We also provide a docker container as an alternative to anaconda. That way performing separation of a local track in `~/Music/track1.wav` can be performed in a single line:
-
-```
-docker run -v ~/Music/:/data -it faroit/open-unmix-pytorch python test.py "/data/track1.wav" --outdir /data/track1
-```
-
-### Applying pre-trained models on audio files
-
-We provide two pre-trained music separation models:
-
-* __`umxhq` (default)__ trained on [MUSDB18-HQ](https://sigsep.github.io/datasets/musdb.html#uncompressed-wav) which comprises the same tracks as in MUSDB18 but un-compressed which yield in a full bandwidth of 22050 Hz.
-
- [](https://doi.org/10.5281/zenodo.3370489)
-
-* __`umx`__ is trained on the regular [MUSDB18](https://sigsep.github.io/datasets/musdb.html#compressed-stems) which is bandwidth limited to 16 kHz do to AAC compression. This model should be used for comparison with other (older) methods for evaluation in [SiSEC18](sisec18.unmix.app).
-
- [](https://doi.org/10.5281/zenodo.3370486)
-
-Furthermore, we provide a model for speech enhancement trained by [Sony Corporation](link)
-
-* __`umxse`__ speech enhancement model is trained on the 28-speaker version of the [Voicebank+DEMAND corpus](https://datashare.is.ed.ac.uk/handle/10283/1942?show=full).
-
- [](https://doi.org/10.5281/zenodo.3786908)
-
-To separate audio files (`wav`, `flac`, `ogg` - but not `mp3`) files just run:
-
-```bash
-umx input_file.wav --model umxhq
-```
-
-A more detailed list of the parameters used for the separation is given in the [inference.md](/docs/inference.md) document.
-We provide a [jupyter notebook on google colab](https://colab.research.google.com/drive/1mijF0zGWxN-KaxTnd0q6hayAlrID5fEQ) to
-experiment with open-unmix and to separate files online without any installation setup.
-
-### Interface with separator fron python via torch.hub
-
-A pre-trained `Separator` can be loaded from pytorch based code using torch.hub.load:
-
-```python
-separator = torch.hub.load('sigsep/open-unmix-pytorch', 'umxhq')
-```
-
-This object may then simply be used for separation of some `audio` (`torch.Tensor` of shape ), sampled at a sampling rate `rate`, through:
-
-```python
-audio_stimates = separator(audio)
-```
-
-### Load user-trained models (only music separation models)
-
-When a path instead of a model-name is provided to `--model` the pre-trained model will be loaded from disk.
-
-```bash
-umx --model /path/to/model/root/directory input_file.wav
-```
-
-Note that `model` usually contains individual models for each target and performs separation using all models. E.g. if `model_path` contains `vocals` and `drums` models, two output files are generated, unless the `--residual-model` option is selected, in which case an additional source will be produced, containing an estimate of all that is not the targets in the mixtures.
-
-### Evaluation using `museval`
-
-To perform evaluation in comparison to other SISEC systems, you would need to install the `museval` package using
-
-```
-pip install museval
-```
-
-and then run the evaluation using
-
-`python -m openunmix.evaluate --outdir /path/to/musdb/estimates --evaldir /path/to/museval/results`
-
-### Results compared to SiSEC 2018 (SDR/Vocals)
-
-Open-Unmix yields state-of-the-art results compared to participants from [SiSEC 2018](https://sisec18.unmix.app/#/methods). The performance of `UMXHQ` and `UMX` is almost identical since it was evaluated on compressed STEMS.
-
-
-
-Note that
-
-1. [`STL1`, `TAK2`, `TAK3`, `TAU1`, `UHL3`, `UMXHQ`] were omitted as they were _not_ trained on only _MUSDB18_.
-2. [`HEL1`, `TAK1`, `UHL1`, `UHL2`] are not open-source.
-
-#### Scores (Median of frames, Median of tracks)
-
-|target|SDR |SIR | SAR | ISR | SDR | SIR | SAR | ISR |
-|------|-----|-----|-----|-----|-----|-----|-----|-----|
-|`model`|UMX |UMX |UMX |UMX |UMXHQ|UMXHQ|UMXHQ|UMXHQ|
-|vocals|6.32 |13.33| 6.52|11.93| 6.25|12.95| 6.50|12.70|
-|bass |5.23 |10.93| 6.34| 9.23| 5.07|10.35| 6.02| 9.71|
-|drums |5.73 |11.12| 6.02|10.51| 6.04|11.65| 5.93|11.17|
-|other |4.02 |6.59 | 4.74| 9.31| 4.28| 7.10| 4.62| 8.78|
-
-## Training
-
-Details on the training is provided in a separate document [here](docs/training.md).
-
-## Extensions
-
-Details on how _open-unmix_ can be extended or improved for future research on music separation is described in a separate document [here](docs/extensions.md).
-
-
-## Design Choices
-
-we favored simplicity over performance to promote clearness of the code. The rationale is to have __open-unmix__ serve as a __baseline__ for future research while performance still meets current state-of-the-art (See [Evaluation](#Evaluation)). The results are comparable/better to those of `UHL1`/`UHL2` which obtained the best performance over all systems trained on MUSDB18 in the [SiSEC 2018 Evaluation campaign](https://sisec18.unmix.app).
-We designed the code to allow researchers to reproduce existing results, quickly develop new architectures and add own user data for training and testing. We favored framework specifics implementations instead of having a monolithic repository with common code for all frameworks.
-
-## How to contribute
-
-_open-unmix_ is a community focused project, we therefore encourage the community to submit bug-fixes and requests for technical support through [github issues](https://github.com/sigsep/open-unmix-pytorch/issues/new/choose). For more details of how to contribute, please follow our [`CONTRIBUTING.md`](CONTRIBUTING.md). For help and support, please use the gitter chat or the google groups forums.
-
-### Authors
-
-[Fabian-Robert Stöter](https://www.faroit.com/), [Antoine Liutkus](https://github.com/aliutkus), Inria and LIRMM, Montpellier, France
-
-## References
-
-<details><summary>If you use open-unmix for your research – Cite Open-Unmix</summary>
-
-```latex
-@article{stoter19,
- author={F.-R. St\\"oter and S. Uhlich and A. Liutkus and Y. Mitsufuji},
- title={Open-Unmix - A Reference Implementation for Music Source Separation},
- journal={Journal of Open Source Software},
- year=2019,
- doi = {10.21105/joss.01667},
- url = {https://doi.org/10.21105/joss.01667}
-}
-```
-
-</p>
-</details>
-
-<details><summary>If you use the MUSDB dataset for your research - Cite the MUSDB18 Dataset</summary>
-<p>
-
-```latex
-@misc{MUSDB18,
- author = {Rafii, Zafar and
- Liutkus, Antoine and
- Fabian-Robert St{\"o}ter and
- Mimilakis, Stylianos Ioannis and
- Bittner, Rachel},
- title = {The {MUSDB18} corpus for music separation},
- month = dec,
- year = 2017,
- doi = {10.5281/zenodo.1117372},
- url = {https://doi.org/10.5281/zenodo.1117372}
-}
-```
-
-</p>
-</details>
-
-
-<details><summary>If compare your results with SiSEC 2018 Participants - Cite the SiSEC 2018 LVA/ICA Paper</summary>
-<p>
-
-```latex
-@inproceedings{SiSEC18,
- author="St{\"o}ter, Fabian-Robert and Liutkus, Antoine and Ito, Nobutaka",
- title="The 2018 Signal Separation Evaluation Campaign",
- booktitle="Latent Variable Analysis and Signal Separation:
- 14th International Conference, LVA/ICA 2018, Surrey, UK",
- year="2018",
- pages="293--305"
-}
-```
-
-</p>
-</details>
-
-âš ï¸ Please note that the official acronym for _open-unmix_ is **UMX**.
-
-### License
-
-MIT
-
-### Acknowledgements
-
-<p align="center">
- <img src="https://raw.githubusercontent.com/sigsep/website/master/content/open-unmix/logo_INRIA.svg?sanitize=true" width="200" title="inria">
- <img src="https://raw.githubusercontent.com/sigsep/website/master/content/open-unmix/anr.jpg" width="100" alt="anr">
-</p>
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/environment-cpu-linux.yml b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/environment-cpu-linux.yml
deleted file mode 100644
index f42955ced300277eba3a4cf680624ac708af3c27..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/environment-cpu-linux.yml
+++ /dev/null
@@ -1,23 +0,0 @@
-name: umx-cpu
-
-channels:
- - conda-forge
- - pytorch
-
-dependencies:
- - python=3.7
- - numpy=1.18
- - scipy=1.4
- - pytorch==1.9.0
- - torchaudio==0.9.0
- - cpuonly
- - tqdm
- - scikit-learn=0.22
- - ffmpeg
- - libsndfile
- - pip
- - pip:
- - musdb>=0.4.0
- - museval>=0.4.0
- - asteroid-filterbanks>=0.3.2
- - gitpython
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/environment-cpu-osx.yml b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/environment-cpu-osx.yml
deleted file mode 100644
index fc97f9a4346a0537e1b0bb016a454869004aa0f9..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/environment-cpu-osx.yml
+++ /dev/null
@@ -1,23 +0,0 @@
-name: umx-osx
-
-channels:
- - conda-forge
- - pytorch
-
-dependencies:
- - python=3.7
- - numpy=1.18
- - scipy=1.4
- - pytorch==1.9.0
- - torchaudio==0.9.0
- - tqdm
- - scikit-learn=0.22
- - ffmpeg
- - libsndfile
- - pip
- - pip:
- - musdb>=0.4.0
- - museval>=0.4.0
- - asteroid-filterbanks>=0.3.2
- - gitpython
-
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/environment-gpu-linux-cuda10.yml b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/environment-gpu-linux-cuda10.yml
deleted file mode 100644
index f35f925adff65fe390531d6af78e614912b8f2d8..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/environment-gpu-linux-cuda10.yml
+++ /dev/null
@@ -1,25 +0,0 @@
-name: umx-gpu
-
-channels:
- - conda-forge
- - pytorch
- - nvidia
-
-dependencies:
- - python=3.7
- - numpy=1.18
- - scipy=1.4
- - pytorch==1.9.0
- - torchaudio==0.9.0
- - cudatoolkit=11.1
- - scikit-learn=0.22
- - tqdm
- - libsndfile
- - ffmpeg
- - pip
- - pip:
- - musdb>=0.4.0
- - museval>=0.4.0
- - asteroid-filterbanks>=0.3.2
- - gitpython
-
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/requirements.txt b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/requirements.txt
deleted file mode 100644
index 8d32278ba07c6fb43363d992d6bb33682fc2a126..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/requirements.txt
+++ /dev/null
@@ -1,27 +0,0 @@
-attrs==21.2.0
-cffi==1.14.6
-ffmpeg-python==0.2.0
-future==0.18.2
-gitdb==4.0.7
-GitPython==3.1.18
-joblib==1.2.0
-jsonschema==3.2.0
-musdb==0.3.1
-museval==0.3.1
-numpy==1.22.0
-pandas==1.3.3
-pyaml==21.8.3
-pycparser==2.20
-pyrsistent==0.18.0
-python-dateutil==2.8.2
-pytz==2021.1
-PyYAML==5.4.1
-scikit-learn==0.22
-scipy==1.7.1
-simplejson==3.17.5
-six==1.16.0
-smmap==4.0.0
-SoundFile==0.10.3.post1
-stempeg==0.2.3
-tqdm==4.62.2
-typing-extensions==3.10.0.2
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/train.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/train.py
deleted file mode 100644
index fa154c1cc341adabb3026fd52f805321a90dd853..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/scripts/train.py
+++ /dev/null
@@ -1,368 +0,0 @@
-import argparse
-import torch
-import time
-from pathlib import Path
-import tqdm
-import json
-import sklearn.preprocessing
-import numpy as np
-import random
-from git import Repo
-import os
-import copy
-import torchaudio
-
-from openunmix import data
-from openunmix import model
-from openunmix import utils
-from openunmix import transforms
-
-tqdm.monitor_interval = 0
-
-
-def train(args, unmix, encoder, device, train_sampler, optimizer):
- losses = utils.AverageMeter()
- unmix.train()
- pbar = tqdm.tqdm(train_sampler, disable=args.quiet)
- for x, y in pbar:
- pbar.set_description("Training batch")
- x, y = x.to(device), y.to(device)
- optimizer.zero_grad()
- X = encoder(x)
- Y_hat = unmix(X)
- Y = encoder(y)
- loss = torch.nn.functional.mse_loss(Y_hat, Y)
- loss.backward()
- optimizer.step()
- losses.update(loss.item(), Y.size(1))
- pbar.set_postfix(loss="{:.3f}".format(losses.avg))
- return losses.avg
-
-
-def valid(args, unmix, encoder, device, valid_sampler):
- losses = utils.AverageMeter()
- unmix.eval()
- with torch.no_grad():
- for x, y in valid_sampler:
- x, y = x.to(device), y.to(device)
- X = encoder(x)
- Y_hat = unmix(X)
- Y = encoder(y)
- loss = torch.nn.functional.mse_loss(Y_hat, Y)
- losses.update(loss.item(), Y.size(1))
- return losses.avg
-
-
-def get_statistics(args, encoder, dataset):
- encoder = copy.deepcopy(encoder).to("cpu")
- scaler = sklearn.preprocessing.StandardScaler()
-
- dataset_scaler = copy.deepcopy(dataset)
- if isinstance(dataset_scaler, data.SourceFolderDataset):
- dataset_scaler.random_chunks = False
- else:
- dataset_scaler.random_chunks = False
- dataset_scaler.seq_duration = None
-
- dataset_scaler.samples_per_track = 1
- dataset_scaler.augmentations = None
- dataset_scaler.random_track_mix = False
- dataset_scaler.random_interferer_mix = False
-
- pbar = tqdm.tqdm(range(len(dataset_scaler)), disable=args.quiet)
- for ind in pbar:
- x, y = dataset_scaler[ind]
- pbar.set_description("Compute dataset statistics")
- # downmix to mono channel
- X = encoder(x[None, ...]).mean(1, keepdim=False).permute(0, 2, 1)
-
- scaler.partial_fit(np.squeeze(X))
-
- # set inital input scaler values
- std = np.maximum(scaler.scale_, 1e-4 * np.max(scaler.scale_))
- return scaler.mean_, std
-
-
-def main():
- parser = argparse.ArgumentParser(description="Open Unmix Trainer")
-
- # which target do we want to train?
- parser.add_argument(
- "--target",
- type=str,
- default="vocals",
- help="target source (will be passed to the dataset)",
- )
-
- # Dataset paramaters
- parser.add_argument(
- "--dataset",
- type=str,
- default="musdb",
- choices=[
- "musdb",
- "aligned",
- "sourcefolder",
- "trackfolder_var",
- "trackfolder_fix",
- ],
- help="Name of the dataset.",
- )
- parser.add_argument("--root", type=str, help="root path of dataset")
- parser.add_argument(
- "--output",
- type=str,
- default="open-unmix",
- help="provide output path base folder name",
- )
- parser.add_argument("--model", type=str, help="Name or path of pretrained model to fine-tune")
- parser.add_argument("--checkpoint", type=str, help="Path of checkpoint to resume training")
- parser.add_argument(
- "--audio-backend",
- type=str,
- default="soundfile",
- help="Set torchaudio backend (`sox_io` or `soundfile`",
- )
-
- # Training Parameters
- parser.add_argument("--epochs", type=int, default=1000)
- parser.add_argument("--batch-size", type=int, default=16)
- parser.add_argument("--lr", type=float, default=0.001, help="learning rate, defaults to 1e-3")
- parser.add_argument(
- "--patience",
- type=int,
- default=140,
- help="maximum number of train epochs (default: 140)",
- )
- parser.add_argument(
- "--lr-decay-patience",
- type=int,
- default=80,
- help="lr decay patience for plateau scheduler",
- )
- parser.add_argument(
- "--lr-decay-gamma",
- type=float,
- default=0.3,
- help="gamma of learning rate scheduler decay",
- )
- parser.add_argument("--weight-decay", type=float, default=0.00001, help="weight decay")
- parser.add_argument(
- "--seed", type=int, default=42, metavar="S", help="random seed (default: 42)"
- )
-
- # Model Parameters
- parser.add_argument(
- "--seq-dur",
- type=float,
- default=6.0,
- help="Sequence duration in seconds" "value of <=0.0 will use full/variable length",
- )
- parser.add_argument(
- "--unidirectional",
- action="store_true",
- default=False,
- help="Use unidirectional LSTM",
- )
- parser.add_argument("--nfft", type=int, default=4096, help="STFT fft size and window size")
- parser.add_argument("--nhop", type=int, default=1024, help="STFT hop size")
- parser.add_argument(
- "--hidden-size",
- type=int,
- default=512,
- help="hidden size parameter of bottleneck layers",
- )
- parser.add_argument(
- "--bandwidth", type=int, default=16000, help="maximum model bandwidth in herz"
- )
- parser.add_argument(
- "--nb-channels",
- type=int,
- default=2,
- help="set number of channels for model (1, 2)",
- )
- parser.add_argument(
- "--nb-workers", type=int, default=0, help="Number of workers for dataloader."
- )
- parser.add_argument(
- "--debug",
- action="store_true",
- default=False,
- help="Speed up training init for dev purposes",
- )
-
- # Misc Parameters
- parser.add_argument(
- "--quiet",
- action="store_true",
- default=False,
- help="less verbose during training",
- )
- parser.add_argument(
- "--no-cuda", action="store_true", default=False, help="disables CUDA training"
- )
-
- args, _ = parser.parse_known_args()
-
- torchaudio.set_audio_backend(args.audio_backend)
- use_cuda = not args.no_cuda and torch.cuda.is_available()
- print("Using GPU:", use_cuda)
- dataloader_kwargs = {"num_workers": args.nb_workers, "pin_memory": True} if use_cuda else {}
-
- repo_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), ".."))
- repo = Repo(repo_dir)
- commit = repo.head.commit.hexsha[:7]
-
- # use jpg or npy
- torch.manual_seed(args.seed)
- random.seed(args.seed)
-
- device = torch.device("cuda" if use_cuda else "cpu")
-
- train_dataset, valid_dataset, args = data.load_datasets(parser, args)
-
- # create output dir if not exist
- target_path = Path(args.output)
- target_path.mkdir(parents=True, exist_ok=True)
-
- train_sampler = torch.utils.data.DataLoader(
- train_dataset, batch_size=args.batch_size, shuffle=True, **dataloader_kwargs
- )
- valid_sampler = torch.utils.data.DataLoader(valid_dataset, batch_size=1, **dataloader_kwargs)
-
- stft, _ = transforms.make_filterbanks(
- n_fft=args.nfft, n_hop=args.nhop, sample_rate=train_dataset.sample_rate
- )
- encoder = torch.nn.Sequential(stft, model.ComplexNorm(mono=args.nb_channels == 1)).to(device)
-
- separator_conf = {
- "nfft": args.nfft,
- "nhop": args.nhop,
- "sample_rate": train_dataset.sample_rate,
- "nb_channels": args.nb_channels,
- }
-
- with open(Path(target_path, "separator.json"), "w") as outfile:
- outfile.write(json.dumps(separator_conf, indent=4, sort_keys=True))
-
- if args.checkpoint or args.model or args.debug:
- scaler_mean = None
- scaler_std = None
- else:
- scaler_mean, scaler_std = get_statistics(args, encoder, train_dataset)
-
- max_bin = utils.bandwidth_to_max_bin(train_dataset.sample_rate, args.nfft, args.bandwidth)
-
- if args.model:
- # fine tune model
- print(f"Fine-tuning model from {args.model}")
- unmix = utils.load_target_models(
- args.target, model_str_or_path=args.model, device=device, pretrained=True
- )[args.target]
- unmix = unmix.to(device)
- else:
- unmix = model.OpenUnmix(
- input_mean=scaler_mean,
- input_scale=scaler_std,
- nb_bins=args.nfft // 2 + 1,
- nb_channels=args.nb_channels,
- hidden_size=args.hidden_size,
- max_bin=max_bin,
- ).to(device)
-
- optimizer = torch.optim.Adam(unmix.parameters(), lr=args.lr, weight_decay=args.weight_decay)
-
- scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
- optimizer,
- factor=args.lr_decay_gamma,
- patience=args.lr_decay_patience,
- cooldown=10,
- )
-
- es = utils.EarlyStopping(patience=args.patience)
-
- # if a checkpoint is specified: resume training
- if args.checkpoint:
- model_path = Path(args.checkpoint).expanduser()
- with open(Path(model_path, args.target + ".json"), "r") as stream:
- results = json.load(stream)
-
- target_model_path = Path(model_path, args.target + ".chkpnt")
- checkpoint = torch.load(target_model_path, map_location=device)
- unmix.load_state_dict(checkpoint["state_dict"], strict=False)
- optimizer.load_state_dict(checkpoint["optimizer"])
- scheduler.load_state_dict(checkpoint["scheduler"])
- # train for another epochs_trained
- t = tqdm.trange(
- results["epochs_trained"],
- results["epochs_trained"] + args.epochs + 1,
- disable=args.quiet,
- )
- train_losses = results["train_loss_history"]
- valid_losses = results["valid_loss_history"]
- train_times = results["train_time_history"]
- best_epoch = results["best_epoch"]
- es.best = results["best_loss"]
- es.num_bad_epochs = results["num_bad_epochs"]
- # else start optimizer from scratch
- else:
- t = tqdm.trange(1, args.epochs + 1, disable=args.quiet)
- train_losses = []
- valid_losses = []
- train_times = []
- best_epoch = 0
-
- for epoch in t:
- t.set_description("Training epoch")
- end = time.time()
- train_loss = train(args, unmix, encoder, device, train_sampler, optimizer)
- valid_loss = valid(args, unmix, encoder, device, valid_sampler)
- scheduler.step(valid_loss)
- train_losses.append(train_loss)
- valid_losses.append(valid_loss)
-
- t.set_postfix(train_loss=train_loss, val_loss=valid_loss)
-
- stop = es.step(valid_loss)
-
- if valid_loss == es.best:
- best_epoch = epoch
-
- utils.save_checkpoint(
- {
- "epoch": epoch + 1,
- "state_dict": unmix.state_dict(),
- "best_loss": es.best,
- "optimizer": optimizer.state_dict(),
- "scheduler": scheduler.state_dict(),
- },
- is_best=valid_loss == es.best,
- path=target_path,
- target=args.target,
- )
-
- # save params
- params = {
- "epochs_trained": epoch,
- "args": vars(args),
- "best_loss": es.best,
- "best_epoch": best_epoch,
- "train_loss_history": train_losses,
- "valid_loss_history": valid_losses,
- "train_time_history": train_times,
- "num_bad_epochs": es.num_bad_epochs,
- "commit": commit,
- }
-
- with open(Path(target_path, args.target + ".json"), "w") as outfile:
- outfile.write(json.dumps(params, indent=4, sort_keys=True))
-
- train_times.append(time.time() - end)
-
- if stop:
- print("Apply Early Stopping")
- break
-
-
-if __name__ == "__main__":
- main()
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/setup.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/setup.py
deleted file mode 100644
index c9e7ecdc5d5cff4747ba6101542472be5515d117..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/setup.py
+++ /dev/null
@@ -1,45 +0,0 @@
-from setuptools import setup, find_packages
-
-umx_version = "1.2.1"
-
-with open("README.md", encoding="utf-8") as fh:
- long_description = fh.read()
-
-setup(
- name="openunmix",
- version=umx_version,
- author="Fabian-Robert Stöter",
- author_email="fabian-robert.stoter@inria.fr",
- url="https://github.com/sigsep/open-unmix-pytorch",
- description="PyTorch-based music source separation toolkit",
- long_description=long_description,
- long_description_content_type="text/markdown",
- license="MIT",
- python_requires=">=3.6",
- install_requires=["numpy", "torchaudio>=0.9.0", "torch>=1.9.0", "tqdm"],
- extras_require={
- "asteroid": ["asteroid-filterbanks>=0.3.2"],
- "tests": [
- "pytest",
- "musdb>=0.4.0",
- "museval>=0.4.0",
- "asteroid-filterbanks>=0.3.2",
- "onnx",
- "tqdm",
- ],
- "stempeg": ["stempeg"],
- "evaluation": ["musdb>=0.4.0", "museval>=0.4.0"],
- },
- entry_points={"console_scripts": ["umx=openunmix.cli:separate"]},
- packages=find_packages(),
- include_package_data=True,
- classifiers=[
- "Development Status :: 4 - Beta",
- "Programming Language :: Python :: 3",
- "Programming Language :: Python :: 3.6",
- "Programming Language :: Python :: 3.7",
- "Programming Language :: Python :: 3.8",
- "License :: OSI Approved :: MIT License",
- "Operating System :: OS Independent",
- ],
-)
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/__init__.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/cli_test.sh b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/cli_test.sh
deleted file mode 100644
index 780fcdf5ebc2ba01f23dfeadbe5fa5cc293b2678..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/cli_test.sh
+++ /dev/null
@@ -1,5 +0,0 @@
-python -m pip install -e .['stempeg'] --quiet
-
-# run umx on url
-coverage run -a `which umx` https://samples.ffmpeg.org/A-codecs/wavpcm/test-96.wav --audio-backend stempeg
-coverage run -a `which umx` https://samples.ffmpeg.org/A-codecs/wavpcm/test-96.wav --audio-backend stempeg --outdir out --niter 0
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/create_dummy_datasets.sh b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/create_dummy_datasets.sh
deleted file mode 100644
index 78a08abfda0783bb4895fbfa63dde182e123c52a..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/create_dummy_datasets.sh
+++ /dev/null
@@ -1,18 +0,0 @@
-#!/usr/bin/env bash
-
-# Set the number of files to generate
-NBFILES=4
-BASEDIR=TrackfolderDataset
-subsets=(
- train
- valid
-)
-for subset in "${subsets[@]}"; do
- for k in $(seq 1 4); do
- path=$BASEDIR/$subset/$k
- mkdir -p $path
- for i in $(seq 1 $NBFILES); do
- sox -n -r 8000 -b 16 $path/$i.wav synth "0:3" whitenoise vol 0.5 fade q 1 "0:3" 1
- done
- done
-done
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/create_vectors.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/create_vectors.py
deleted file mode 100644
index b70d04d245f83fffdc6875a310ee93a9f1778d88..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/create_vectors.py
+++ /dev/null
@@ -1,31 +0,0 @@
-import os
-import torch
-import musdb
-import numpy as np
-from openunmix import model, utils
-
-"""script to create spectrogram test vectors for STFT regression tests
-
-Test vectors have been created using the `v1.0.0` release tag as this
-was the commit that umx was trained with
-"""
-
-
-def main():
- test_track = "Al James - Schoolboy Facination"
- mus = musdb.DB(download=True)
-
- # load audio track
- track = [track for track in mus.tracks if track.name == test_track][0]
-
- # convert to torch tensor
- audio = torch.tensor(track.audio.T, dtype=torch.float32)
-
- stft = model.STFT(n_fft=4096, n_hop=1024)
- spec = model.Spectrogram(power=1, mono=False)
- magnitude_spectrogram = spec(stft(audio[None, ...]))
- torch.save(magnitude_spectrogram, "Al James - Schoolboy Facination.spectrogram.pt")
-
-
-if __name__ == "__main__":
- main()
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_augmentations.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_augmentations.py
deleted file mode 100644
index 883167c921c4aae6e2dabc40ffad57c483075e85..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_augmentations.py
+++ /dev/null
@@ -1,35 +0,0 @@
-import pytest
-import torch
-
-from openunmix import data
-
-
-@pytest.fixture(params=[4096, 4096 * 10])
-def nb_timesteps(request):
- return int(request.param)
-
-
-@pytest.fixture(params=[1, 2, 3])
-def nb_channels(request):
- return request.param
-
-
-@pytest.fixture
-def audio(request, nb_channels, nb_timesteps):
- return torch.rand((nb_channels, nb_timesteps))
-
-
-def test_gain(audio):
- out = data._augment_gain(audio)
- assert out.shape == audio.shape
-
-
-def test_channelswap(audio):
- out = data._augment_channelswap(audio)
- assert out.shape == audio.shape
-
-
-def test_forcestereo(audio, nb_channels):
- out = data._augment_force_stereo(audio)
- assert out.shape[-1] == audio.shape[-1]
- assert out.shape[0] == 2
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_datasets.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_datasets.py
deleted file mode 100644
index f4fbce01347636a506a5cb47ceed7205d09b3a9a..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_datasets.py
+++ /dev/null
@@ -1,63 +0,0 @@
-import pytest
-import numpy as np
-import torchaudio
-
-from openunmix import data
-
-
-@pytest.fixture(params=["soundfile", "sox_io"])
-def torch_backend(request):
- return request.param
-
-
-def test_musdb():
- musdb = data.MUSDBDataset(download=True, samples_per_track=1, seq_duration=1.0)
- for x, y in musdb:
- assert x.shape[-1] == 44100
-
-
-def test_trackfolder_fix(torch_backend):
- torchaudio.set_audio_backend(torch_backend)
-
- train_dataset = data.FixedSourcesTrackFolderDataset(
- split="train",
- seq_duration=1.0,
- root="TrackfolderDataset",
- sample_rate=8000.0,
- target_file="1.wav",
- interferer_files=["2.wav", "3.wav", "4.wav"],
- )
- for x, y in train_dataset:
- assert x.shape[-1] == 8000
-
-
-def test_trackfolder_var(torch_backend):
- torchaudio.set_audio_backend(torch_backend)
-
- train_dataset = data.VariableSourcesTrackFolderDataset(
- split="train",
- seq_duration=1.0,
- root="TrackfolderDataset",
- sample_rate=8000.0,
- target_file="1.wav",
- )
- for x, y in train_dataset:
- assert x.shape[-1] == 8000
-
-
-def test_sourcefolder(torch_backend):
- torchaudio.set_audio_backend(torch_backend)
-
- train_dataset = data.SourceFolderDataset(
- split="train",
- seq_duration=1.0,
- root="TrackfolderDataset",
- sample_rate=8000.0,
- target_dir="1",
- interferer_dirs=["2", "3"],
- ext=".wav",
- nb_samples=20,
- )
- for k in range(len(train_dataset)):
- x, y = train_dataset[k]
- assert x.shape[-1] == 8000
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_io.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_io.py
deleted file mode 100644
index ffaf80b380b189cc6b11af121b72ba7e2fffc977..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_io.py
+++ /dev/null
@@ -1,42 +0,0 @@
-import pytest
-import numpy as np
-import os
-import torchaudio
-
-from openunmix import data
-
-
-audio_path = os.path.join(
- os.path.dirname(os.path.realpath(__file__)),
- "data/test.wav",
-)
-
-
-@pytest.fixture(params=["soundfile", "sox_io"])
-def torch_backend(request):
- return request.param
-
-
-@pytest.fixture(params=[1.0, 2.0, None])
-def dur(request):
- return request.param
-
-
-@pytest.fixture(params=[True, False])
-def info(request, torch_backend):
- torchaudio.set_audio_backend(torch_backend)
-
- if request.param:
- return data.load_info(audio_path)
- else:
- return None
-
-
-def test_loadwav(dur, info, torch_backend):
- torchaudio.set_audio_backend(torch_backend)
- audio, _ = data.load_audio(audio_path, dur=dur, info=info)
- rate = 8000.0
- if dur:
- assert audio.shape[-1] == int(dur * rate)
- else:
- assert audio.shape[-1] == rate * 3
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_jit.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_jit.py
deleted file mode 100644
index 85915975ff51951f39b69b7eae99d8808c0ba428..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_jit.py
+++ /dev/null
@@ -1,82 +0,0 @@
-import torch
-import torch.onnx
-import pytest
-from torch.testing._internal.jit_utils import JitTestCase
-
-from openunmix import model
-
-
-class TestModels(JitTestCase):
- @staticmethod
- def _test_umx(self, device, check_export_import=True):
- nb_samples = 1
- nb_channels = 2
- nb_bins = 2049
- nb_frames = 11
- nb_timesteps = 4096 * 10
-
- example = torch.rand((nb_samples, nb_channels, nb_bins, nb_frames), device=device)
- # set model to eval due to non-deterministic behaviour of dropout
- umx = model.OpenUnmix(nb_bins=nb_bins, nb_channels=nb_channels).eval().to(device)
-
- # test trace
- self.checkTrace(umx, (example,), export_import=check_export_import)
-
- # creatr separator
- separator = (
- model.Separator(
- target_models={"source_1": umx, "source_2": umx}, niter=1, filterbank="asteroid"
- )
- .eval()
- .to(device)
- )
-
- example_time = torch.rand((nb_samples, nb_channels, nb_timesteps), device="cpu")
-
- # disable tracing check for now as there are too many dynamic parts
- self.checkTrace(separator, (example_time,), export_import=False, inputs_require_grads=False)
- # test scripting of the separator
- torch.jit.script(separator)
-
- def test_umx(self):
- self._test_umx(self, device="cpu")
-
-
-@pytest.mark.skip(reason="Currently not supported")
-def test_onnx():
- """Test ONNX export of the separator
-
- currently results in erros, blocked by
- https://github.com/pytorch/pytorch/issues/49958
- """
- nb_samples = 1
- nb_channels = 2
- nb_timesteps = 11111
-
- example = torch.rand((nb_samples, nb_channels, nb_timesteps), device="cpu")
- # set model to eval due to non-deterministic behaviour of dropout
- umx = model.OpenUnmix(nb_bins=2049, nb_channels=2).eval().to("cpu")
-
- # creatr separator
- separator = (
- model.Separator(
- target_models={"source_1": umx, "source_2": umx}, niter=1, filterbank="asteroid"
- )
- .eval()
- .to("cpu")
- )
-
- torch_out = separator(example)
-
- # Export the model
- torch.onnx.export(
- separator,
- example,
- "umx.onnx",
- export_params=True,
- opset_version=10,
- do_constant_folding=True,
- input_names=["input"],
- output_names=["output"],
- dynamic_axes={"input": {0: "batch_size"}, "output": {0: "batch_size"}},
- )
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_model.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_model.py
deleted file mode 100644
index c7f931e268526b0743142d9340f24418e84d3a40..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_model.py
+++ /dev/null
@@ -1,64 +0,0 @@
-import pytest
-import torch
-
-from openunmix import model
-from openunmix import umxse
-from openunmix import umxhq
-from openunmix import umx
-from openunmix import umxl
-
-
-@pytest.fixture(params=[10, 100])
-def nb_frames(request):
- return int(request.param)
-
-
-@pytest.fixture(params=[1, 2, 3])
-def nb_channels(request):
- return request.param
-
-
-@pytest.fixture(params=[1, 5])
-def nb_samples(request):
- return request.param
-
-
-@pytest.fixture(params=[111, 1024])
-def nb_bins(request):
- return request.param
-
-
-@pytest.fixture
-def spectrogram(request, nb_samples, nb_channels, nb_bins, nb_frames):
- return torch.rand((nb_samples, nb_channels, nb_bins, nb_frames))
-
-
-@pytest.fixture(params=[True, False])
-def unidirectional(request):
- return request.param
-
-
-@pytest.fixture(params=[32])
-def hidden_size(request):
- return request.param
-
-
-def test_shape(spectrogram, nb_bins, nb_channels, unidirectional, hidden_size):
- unmix = model.OpenUnmix(
- nb_bins=nb_bins,
- nb_channels=nb_channels,
- unidirectional=unidirectional,
- nb_layers=1, # speed up training
- hidden_size=hidden_size,
- )
- unmix.eval()
- Y = unmix(spectrogram)
- assert spectrogram.shape == Y.shape
-
-
-@pytest.mark.parametrize("model_fn", [umx, umxhq, umxse, umxl])
-def test_model_loading(model_fn):
- X = torch.rand((1, 2, 4096))
- model = model_fn(niter=0, pretrained=True)
- Y = model(X)
- assert Y[:, 0, ...].shape == X.shape
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_regression.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_regression.py
deleted file mode 100644
index 7ac2bbc24fc90dc8893d550530283062feb59d6b..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_regression.py
+++ /dev/null
@@ -1,94 +0,0 @@
-import os
-import pytest
-import musdb
-import simplejson as json
-import numpy as np
-import torch
-
-
-from openunmix import model
-from openunmix import evaluate
-from openunmix import utils
-from openunmix import transforms
-
-
-test_track = "Al James - Schoolboy Facination"
-
-json_path = os.path.join(
- os.path.dirname(os.path.realpath(__file__)),
- "data/%s.json" % test_track,
-)
-
-spec_path = os.path.join(
- os.path.dirname(os.path.realpath(__file__)),
- "data/%s.spectrogram.pt" % test_track,
-)
-
-
-@pytest.fixture(params=["torch", "asteroid"])
-def method(request):
- return request.param
-
-
-@pytest.fixture()
-def mus():
- return musdb.DB(download=True)
-
-
-def test_estimate_and_evaluate(mus):
- # return any number of targets
- with open(json_path) as json_file:
- ref = json.loads(json_file.read())
-
- track = [track for track in mus.tracks if track.name == test_track][0]
-
- scores = evaluate.separate_and_evaluate(
- track,
- targets=["vocals", "drums", "bass", "other"],
- model_str_or_path="umx",
- niter=1,
- residual=None,
- mus=mus,
- aggregate_dict=None,
- output_dir=None,
- eval_dir=None,
- device="cpu",
- wiener_win_len=None,
- )
-
- assert scores.validate() is None
-
- with open(os.path.join(".", track.name) + ".json", "w+") as f:
- f.write(scores.json)
-
- scores = json.loads(scores.json)
-
- for target in ref["targets"]:
- for metric in ["SDR", "SIR", "SAR", "ISR"]:
-
- ref = np.array([d["metrics"][metric] for d in target["frames"]])
- idx = [t["name"] for t in scores["targets"]].index(target["name"])
- est = np.array([d["metrics"][metric] for d in scores["targets"][idx]["frames"]])
-
- assert np.allclose(ref, est, atol=1e-01)
-
-
-def test_spectrogram(mus, method):
- """Regression test for spectrogram transform
-
- Loads pre-computed transform and compare to current spectrogram
- e.g. this makes sure that the training is reproducible if parameters
- such as STFT centering would be subject to change.
- """
- track = [track for track in mus.tracks if track.name == test_track][0]
-
- stft, _ = transforms.make_filterbanks(
- n_fft=4096, n_hop=1024, sample_rate=track.rate, method=method
- )
- encoder = torch.nn.Sequential(stft, model.ComplexNorm(mono=False))
- audio = torch.as_tensor(track.audio, dtype=torch.float32, device="cpu")
- audio = utils.preprocess(audio, track.rate, track.rate)
- ref = torch.load(spec_path)
- dut = encoder(audio).permute(3, 0, 1, 2)
-
- assert torch.allclose(ref, dut, atol=1e-4, rtol=1e-3)
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_transforms.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_transforms.py
deleted file mode 100644
index 1e2f59d29f92bf44e69d44809fdc1b36ed03899c..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_transforms.py
+++ /dev/null
@@ -1,51 +0,0 @@
-import pytest
-import numpy as np
-import torch
-from openunmix import transforms
-
-
-@pytest.fixture(params=[4096, 44100])
-def nb_timesteps(request):
- return int(request.param)
-
-
-@pytest.fixture(params=[1, 2])
-def nb_channels(request):
- return request.param
-
-
-@pytest.fixture(params=[1, 2])
-def nb_samples(request):
- return request.param
-
-
-@pytest.fixture(params=[1024, 2048, 4096])
-def nfft(request):
- return int(request.param)
-
-
-@pytest.fixture(params=[2, 4])
-def hop(request, nfft):
- return nfft // request.param
-
-
-@pytest.fixture(params=["torch", "asteroid"])
-def method(request):
- return request.param
-
-
-@pytest.fixture
-def audio(request, nb_samples, nb_channels, nb_timesteps):
- return torch.rand((nb_samples, nb_channels, nb_timesteps))
-
-
-def test_stft(audio, nfft, hop, method):
- # we should only test for center=True as
- # False doesn't pass COLA
- # https://github.com/pytorch/audio/issues/500
- stft, istft = transforms.make_filterbanks(n_fft=nfft, n_hop=hop, center=True, method=method)
-
- X = stft(audio)
- X = X.detach()
- out = istft(X, length=audio.shape[-1])
- assert np.sqrt(np.mean((audio.detach().numpy() - out.detach().numpy()) ** 2)) < 1e-6
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_utils.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_utils.py
deleted file mode 100644
index 71ab4915a14fe1fc0d2b9fa575917b9fa1a89118..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_utils.py
+++ /dev/null
@@ -1,17 +0,0 @@
-from openunmix.utils import AverageMeter, EarlyStopping
-
-
-def test_average_meter():
- losses = AverageMeter()
- losses.update(1.0)
- losses.update(3.0)
- assert losses.avg == 2.0
-
-
-def test_early_stopping():
- es = EarlyStopping(patience=2)
- es.step(1.0)
-
- assert not es.step(0.5)
- assert not es.step(0.6)
- assert es.step(0.7)
diff --git a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_wiener.py b/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_wiener.py
deleted file mode 100644
index 2f0d02350bb60e20c6c058f2692c104725b8d223..0000000000000000000000000000000000000000
--- a/my_submssion/openunmix-baseline/sigsep_open-unmix-pytorch_master/tests/test_wiener.py
+++ /dev/null
@@ -1,72 +0,0 @@
-import pytest
-import torch
-
-
-from openunmix import model
-from openunmix.filtering import wiener
-
-
-@pytest.fixture(params=[10, 100])
-def nb_frames(request):
- return int(request.param)
-
-
-@pytest.fixture(params=[1, 2])
-def nb_channels(request):
- return request.param
-
-
-@pytest.fixture(params=[10, 127])
-def nb_bins(request):
- return request.param
-
-
-@pytest.fixture(params=[1, 2, 3])
-def nb_sources(request):
- return request.param
-
-
-@pytest.fixture(params=[0, 1, 2])
-def iterations(request):
- return request.param
-
-
-@pytest.fixture(params=[True, False])
-def softmask(request):
- return request.param
-
-
-@pytest.fixture(params=[True, False])
-def residual(request):
- return request.param
-
-
-@pytest.fixture
-def target(request, nb_frames, nb_channels, nb_bins, nb_sources):
- return torch.rand((nb_frames, nb_bins, nb_channels, nb_sources))
-
-
-@pytest.fixture
-def mix(request, nb_frames, nb_channels, nb_bins):
- return torch.rand((nb_frames, nb_bins, nb_channels, 2))
-
-
-@pytest.fixture(params=[torch.float32, torch.float64])
-def dtype(request):
- return request.param
-
-
-def test_wiener(target, mix, iterations, softmask, residual):
- output = wiener(target, mix, iterations=iterations, softmask=softmask, residual=residual)
- # nb_frames, nb_bins, nb_channels, 2, nb_sources
- assert output.shape[:3] == mix.shape[:3]
- assert output.shape[3] == 2
- if residual:
- assert output.shape[4] == target.shape[3] + 1
- else:
- assert output.shape[4] == target.shape[3]
-
-
-def test_dtype(target, mix, dtype):
- output = wiener(target.to(dtype=dtype), mix.to(dtype=dtype), iterations=1)
- assert output.dtype == dtype
diff --git a/my_submssion/openunmix-baseline/trusted_list b/my_submssion/openunmix-baseline/trusted_list
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000